1. Collections 與Collection的差別
- java.util.Collection 是一個集合接口(集合類的一個頂級接口)。它提供了對集合對象進行基本操作的通用接口方法。Collection接口在Java 類庫中有很多具體的實作。Collection接口的意義是為各種具體的集合提供了最大化的統一操作方式,其直接繼承接口有List與Set。
- Collections則是集合類的一個工具類/幫助類,其中提供了一系列靜态方法,用于對集合中元素進行排序、搜尋以及線程安全等各種操作。
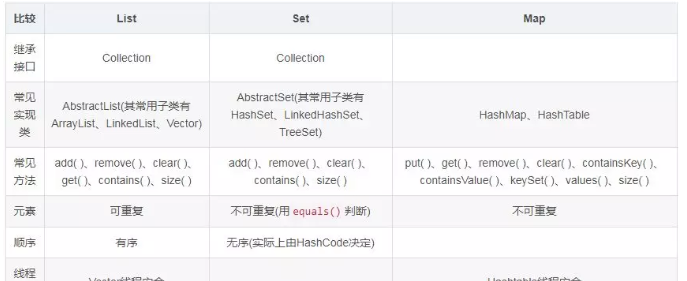
2. List、Set、Map 之間的差別
3. HashMap 的實作原理

HashMap的主幹是一個Entry數組。Entry是HashMap的基本組成單元,每一個Entry包含一個key-value鍵值對。
HashMap由數組+連結清單+紅黑樹組成的。
a:數組的初始容量為16,而容量是以2的次方擴充的,一是為了提高性能使用足夠大的數組,二是為了能使用位運算代替取模預算(據說提升了5~8倍)。
b:數組是否需要擴充是通過負載因子判斷的,如果目前元素個數為數組容量的0.75時,就會擴充數組。這個0.75就是預設的負載因子,可由構造傳入。我們也可以設定大于1的負載因子,這樣數組就不會擴充,犧牲性能,節省記憶體。
c:為了解決碰撞,數組中的元素是單向連結清單類型。當連結清單長度到達一個門檻值時(7或8),會将連結清單轉換成紅黑樹提高性能。而當連結清單長度縮小到另一個門檻值時(6),又會将紅黑樹轉換回單向連結清單提高性能,這裡是一個平衡點。
4. HashSet 的實作原理
①是基于HashMap實作的,預設構造函數是建構一個初始容量為16,負載因子為0.75 的HashMap。封裝了一個 HashMap 對象來存儲所有的集合元素,所有放入 HashSet 中的集合元素實際上由 HashMap 的 key 來儲存,而 HashMap 的 value 則存儲了一個 PRESENT,它是一個靜态的 Object 對象。
②當我們試圖把某個類的對象當成 HashMap的 key,或試圖将這個類的對象放入 HashSet 中儲存時,重寫該類的equals(Object obj)方法和hashCode() 方法很重要,而且這兩個方法的傳回值必須保持一緻:當該類的兩個的 hashCode() 傳回值相同時,它們通過 equals() 方法比較也應該傳回 true。通常來說,所有參與計算 hashCode() 傳回值的關鍵屬性,都應該用于作為 equals() 比較的标準。
③HashSet的其他操作都是基于HashMap的。
HashSet的add方法調用HashMap的put()方法實作,如果鍵已經存在,HashMap.put()放回的是舊值,添加失敗,如果添加成功map.put()方法傳回的是null ,HashSet.add()方法傳回true,要添加的元素作為可map中的key 。
總結: HashSet的底層通過HashMap實作的,而HashMap在1.7之前使用的是數組+連結清單實作,在1.8+使用的數組+連結清單+紅黑樹實作。其實也可以這樣了解,HashSet的底層實作和HashMap使用的是相同的方式,因為Map是無序的,是以HashSet也無法保證順序。HashSet的方法也是借助HashMap的方法來實作的。
5. HashMap 和 Hashtable 的差別
(1)繼承父類不同:HashMap是繼承自AbstractMap類,而HashTable是繼承自Dictionary類。不過它們都實作了同時實作了map、Cloneable(可複制)、Serializable(可序列化)這三個接口。
(2)對外提供的接口不同:Hashtable比HashMap多提供了elments() 和contains() 兩個方法。elments() 方法繼承自Hashtable的父類Dictionnary。elements() 方法用于傳回此Hashtable中的value的枚舉。contains() 方法判斷該Hashtable是否包含傳入的value。它的作用與containsValue()一緻。事實上,contansValue() 就隻是調用了一下contains() 方法。
(3)對Null key 和Null value的支援不同:
a:Hashtable既不支援Null key也不支援Null value。當key為Null時,調用put() 方法,會抛出空指針異常;當value為null值時,Hashtable對其做了限制,也會抛出空指針異常。
b:HashMap中,null可以作為鍵,這樣的鍵隻有一個;可以有一個或多個鍵所對應的值為null。當get()方法傳回null值時,可能是 HashMap中沒有該鍵,也可能使該鍵所對應的值為null。是以,在HashMap中不能由get()方法來判斷HashMap中是否存在某個鍵, 而應該用containsKey()方法來判斷。
(4)線程安全性不同:
a:Hashtable是線程安全的,它的每個方法中都加入了Synchronize方法。在多線程并發的環境下,可以直接使用Hashtable,不需要自己為它的方法實作同步;
b:HashMap不是線程安全的,在多線程并發的環境下,可能會産生死鎖等問題。使用HashMap時就必須要自己增加同步處理,它的效率會比Hashtable要好很多。當需要多線程操作的時候可以使用線程安全的ConcurrentHashMap。ConcurrentHashMap雖然也是線程安全的,但是它的效率比Hashtable要高好多倍。因為ConcurrentHashMap使用了分段鎖,并不對整個資料進行鎖定。
(5) 周遊方式的内部實作上不同:
a:Hashtable、HashMap都使用了 Iterator。而由于曆史原因,Hashtable還使用了Enumeration的方式 。一旦在疊代的過程中狀态發生了改變,則會快速抛出一個異常,終止疊代行為。
b:HashMap的Iterator是fail-fast疊代器。當有其它線程改變了HashMap的結構(增加,删除,修改元素),将會抛出ConcurrentModificationException。不過,通過Iterator的remove()方法移除元素則不會抛出ConcurrentModificationException異常。但這并不是一個一定發生的行為,要看JVM。
(6)初始容量大小和每次擴充容量大小的不同:Hashtable預設的初始大小為11,之後每次擴充,容量變為原來的2n+1。HashMap預設的初始化大小為16。之後每次擴充,容量變為原來的2倍。
(7)計算hash值的方法不同:
a:Hashtable直接使用對象的hashCode。hashCode是JDK根據對象的位址或者字元串或者數字算出來的int類型的數值。然後再使用除留餘數發來獲得最終的位置。Hashtable在計算元素的位置時需要進行一次除法運算,而除法運算是比較耗時的。
b:HashMap為了提高計算效率,将哈希表的大小固定為了2的幂,這樣在取模預算時,不需要做除法,隻需要做位運算。位運算比除法的效率要高很多。但是會産生hash沖突,HashMap重新根據hashcode計算hash值後,又對hash值做了一些運算來打散資料,使得取得的位置更加分散,進而減少了hash沖突。
6. ArrayList、LinkedList、Vector的差別和實作原理
(1)存儲結構:ArrayList和Vector是按照順序将元素存儲(從下表為0開始),删除元素時,删除操作完成後,需要使部分元素移位,預設的初始容量都是10;ArrayList和Vector是基于數組實作的,LinkedList是基于雙向連結清單實作的(含有頭結點)。
(2)線程安全性
ArrayList是線程不安全的,在單線程的環境中,LinkedList也是線程不安全的,如果在并發環境下使用它們,可以用Collections類中的靜态方法synchronizedList()對ArrayList和LinkedList進行調用即可。
Vector實作線程安全的,即它大部分的方法都包含關鍵字synchronized,但是Vector的效率沒有ArraykList和LinkedList高。
(3)擴容機制
從内部實作機制來講,ArrayList和Vector都是使用Object的數組形式來存儲的,當向這兩種類型中增加元素的時候,若容量不夠,需要進行擴容。ArrayList擴容後的容量是之前的1.5倍,然後把之前的資料拷貝到建立的數組中去。而Vector預設情況下擴容後的容量是之前的2倍。
Vector可以設定容量增量,而ArrayList不可以。在Vector中,有capacityIncrement:當大于其容量時,容量自動增加。如果在建立Vector時,指定了capacityIncrement的大小,則Vector中動态數組容量需要增加時,如果容量的增量大于0,則增加的是大小是capacityIncrement,如果增量小于0,則增大為之前的2倍。
(4)增删改查的效率
ArrayList和Vector中,從指定的位置檢索一個對象,或在集合的末尾插入、删除一個元素的時間是一樣的,時間複雜度都是O(1)。但是如果在其他位置增加或者删除元素花費的時間是O(n),LinkedList中,在插入、删除任何位置的元素所花費的時間都是一樣的,時間複雜度都為O(1),但是他在查詢一個元素的時間複雜度為O(n)。
7. Iterator疊代器
疊代器是一種設計模式,它是一個對象,它可以周遊并選擇序列中的對象。
(1) 使用方法iterator()要求容器傳回一個Iterator。第一次調用Iterator的next()方法時,它傳回序列的第一個元素。注意:iterator()方法是java.lang.Iterable接口,被Collection繼承。
(2) 使用next()獲得序列中的下一個元素。
(3) 使用hasNext()檢查序列中是否還有元素。
(4) 使用remove()将疊代器新傳回的元素删除。
terator 和 ListIterator 的差別:
Iterator可用來周遊Set和List集合,但是ListIterator隻能用來周遊List。
Iterator對集合隻能是前向周遊,ListIterator既可以前向也可以後向。
ListIterator實作了Iterator接口,并包含其他的功能,比如:增加元素,替換元素,擷取前一個和後一個元素的索引,等等。
8. Collections 工具類和 Arrays 工具類常見方法
(1)Collections工具類的常用方法
Collections.reverse(arrayList);
排序:
void reverse(List list)//反轉
void shuffle(List list)//随機排序
void sort(List list)//按自然排序的升序排序
void sort(List list, Comparator c)//定制排序,由Comparator控制排序邏輯
void swap(List list, int i , int j)//交換兩個索引位置的元素
void rotate(List list, int distance)//旋轉。當distance為正數時,将list後distance個元素整體移到前面。當distance為負數時,将 list的前distance個元素整體移到後面。
查找和替換:
int binarySearch(List list, Object key)//對List進行二分查找,傳回索引,注意List必須是有序的
int max(Collection coll)//根據元素的自然順序,傳回最大的元素。 類比int min(Collection coll)
int max(Collection coll, Comparator c)//根據定制排序,傳回最大元素,排序規則由Comparatator類控制。類比int min(Collection coll, Comparator c)
void fill(List list, Object obj)//用指定的元素代替指定list中的所有元素。
int frequency(Collection c, Object o)//統計元素出現次數
int indexOfSubList(List list, List target)//統計target在list中第一次出現的索引,找不到則傳回-1,類比int lastIndexOfSubList(List source, list target).
boolean replaceAll(List list, Object oldVal, Object newVal), 用新元素替換舊元素
(2)Arrays類的常見操作
Arrays.sort(a);
排序 : sort()
Arrays.sort(a);
Arrays.sort(b, 2, 6);
Arrays.parallelSort(c);
Arrays.parallelSort(d);
查找 : binarySearch()
// 排序後再進行二分查找,否則找不到
Arrays.sort(e);
Arrays.binarySearch(e, 'c');
比較: equals()
Arrays.equals(e, f);//比較兩個數組
填充 : fill()
// 數組中所有元素重新配置設定值
Arrays.fill(g, 3);
// 數組中指定範圍元素重新配置設定值
Arrays.fill(h, 0, 2, 9);
轉清單: asList()
Arrays.asList("Larry", "Moe", "Curly");
轉字元串 : toString()
//傳回指定數組的内容的字元串表示形式。
Arrays.toString(k);
複制: copyOf()
//copyOf 方法實作數組複制,h為數組,6為複制的長度
Arrays.copyOf(h, 6);
// copyOfRange将指定數組的指定範圍複制到新數組中
Arrays.copyOfRange(h, 6, 11);