- 1 HashSet簡介
- 2 基本用法與特點
- 3 HashSet的唯一性
- 4 增删改時需要注意
1 HashSet簡介
作為Set接口的一個實作類,特點是無序、存儲元素唯一的。底層實作的資料結構為哈希表。
2 基本用法與特點
-
建立一個HashSet集合對象
與ArrayList集合相同,HashSet集合對象建立也依據不同的版本有不同的方法。
-
JDK5.0之前,預設往集合裡面存放的都是Object類型的對象,取元素後類型需強轉。
HashSet set = new HashSet();
-
JDK5.0及以後,可以加泛型(不加泛型預設傳入元素為Object類型)
HashSet<泛型> set = new HashSet<泛型>();
-
JDK7.0及以後,後面的泛型會自動推斷(不加泛型預設傳入元素為Object類型)
HashSet<泛型> set = new HashSet<>();
-
但是與ArrayList不同的是,HashSet集合構造方法中傳入的參數,預設(空參)時傳入16,0.75。分别代表分組組數(int)和加載因子(float)。
其中,第一個參數分組組數一定是2的n次方,如傳入7,自動開辟8個分組;傳入17,自動開辟32個分組。元素根據其類中hashCode()生成哈希碼為特征值(若未重寫,根據Object類中定義的,以位址的哈希碼作為特征值),模以組數根據得到的結果去往不同的分組。
第二個參數為加載因子。
這兩個參數共同構成門檻值(分組組數 * 加載因子),門檻值指的是哈希表擴容的最小臨界值,一個集合中的某一個哈希表達到或者超出的時候這個值的時候,整個集合的哈希表都需要擴容。擴容倍數為2倍。
最好不要使用擴容方法對HashSet集合進行擴容,因為這會改變分組數量使元素的特征碼模以新的分組數量重新進入新的分組,效率低。
-
如何調整HashSet性能和空間的取舍?
分的組數越多,組内元素越少,查找效率越高,但占空間;
加載因子越高,承受得擴容數量越高,查找效率低,但省記憶體。(注意:加載因子可以大于1,隻要一個分組到了門檻值(集合中某一個哈希表分組中元素達到的某個數量),統一擴容)
- 添加元素到HashSet
//元素的類型要與聲明HashSet時傳入的泛型相一緻 set.add(Object obj); Collections.addAll(set, Object obj1,Object obj2....); //将新的集合加入到set中 set1.addAll(集合類型的引用); - 得到HashSet集合的大小
set.size(); - 判斷集合裡是否包含指定元素
set.contains(Object obj); - 指定元素進行删除
set.remove(Object obj);
注意,這裡的删除remove、判斷是否包含指定元素contains底層依賴的依據是Object類中的equals(),傳入obj引用作為一個參照,依據這個類中定義好的或者Object類中的equals()(原生比較位址)進行true/false的比較。
- 周遊
因為HashSet集合是無序的,在周遊時不能根據for + 下标進行順序周遊,隻能根據疊代器進行周遊。foreach底層也是依據疊代器周遊。另外HashSet也缺少依據下标的get()和remove()。//周遊 //foreach for(Integer x : set){ System.out.println(x); } //疊代器 for(Iterator<Integer> i = set.iterator(); i.hasNext(); ){ Integer num = i.next(); System.out.println(num); }
//将ArrayList中重複的元素去除
import java.util.*;
public class Test{
public static void main(String[] args){
ArrayList<Integer> list = new ArrayList<>();//不唯一
Collections.addAll(list,45,77,92,45,92,33);
//将集合裡面的重複元素删除
HashSet<Integer> set = new HashSet<>();
set.addAll(list);
System.out.println(set);
}
}
- 與ArrayList相比,HashSet缺少的方法有
- get(int 下标)
- remove(int 下标)
- for + 下标
3 HashSet的唯一性
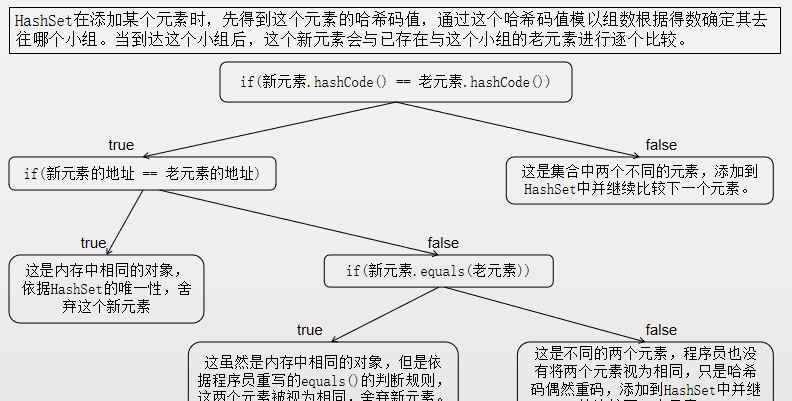
HashSet的唯一不是指記憶體裡面的唯一。而是取決于程式員如何定義hashCode()、equals()。此時add()都需要通過hashCode()、equals()判斷唯一性;remove(Object obj)、contains(Object obj)在操作元素時也需要判斷hashCode()、equals()。這一點與ArrayList這種不唯一的集合不同。
- 因包裝類、String類中的equals()和hashCode()方法均在定義類時重寫,是以被認定為唯一。因HashSet的唯一性,若被驗證兩個元素重複了,為保證效率,新加入的那個元素被舍棄。
HashSet<String> set = new HashSet<>();
String x = new String("OK");
String y = new String("OK");
set.add(x);
System.out.println(set.size());//--->1
set.add(y);
System.out.println(set.size());//--->1
HashSet<Integer> set = new HashSet<>();
Integer a = new Integer(77);
Integer b = new Integer(77);
set.add(a);
System.out.println(set.size());//--->1
set.add(b);
System.out.println(set.size());//--->1
-
隻重寫了hashCode(),隻能保證特征碼相同的對象能去往同一個小組,
若未重寫equals(),Object類的equals()預設比較位址,此時兩個對象位址不同,不能被認為是同一個元素,size()增加,如Test1;
若重寫了equals(),則使用程式員自定義的規則判斷兩對象是否相同,此時這兩個元素被判為相同元素,size()不變。
import java.util.*;
public class Test1{
public static void main(String[] asrgs){
HashSet<Student> set = new HashSet<>();
Student s1 = new Student("張三");
Student s2 = new Student("張三");
System.out.println("s1:" + s1.hashCode());
System.out.println("s2:" + s2.hashCode());
set.add(s1);
System.out.println("size1:" + set.size());
set.add(s2);
System.out.println("size2:" + set.size());
}
}
class Student{
String name;
public Student(String name){
this.name = name;
}
//hashCode方法得到一個對象的散列特征碼
//并用來決定對象應該取到哪一個小組
@Override
public int hashCode(){
return name.hashCode();
}
}
//輸出結果:
/**
s1:774889
s2:774889
size1:1
size2:2
*/
import java.util.*;
public class Test2{
public static void main(String[] asrgs){
HashSet<Student> set = new HashSet<>();
Student s1 = new Student("張三");
Student s2 = new Student("張三");
System.out.println("s1:" + s1.hashCode());
System.out.println("s2:" + s2.hashCode());
set.add(s1);
System.out.println("size1:" + set.size());
set.add(s2);
System.out.println("size2:" + set.size());
}
}
class Student{
String name;
public Student(String name){
this.name = name;
}
//hashCode方法得到一個對象的散列特征碼
//并用來決定對象應該取到哪一個小組
@Override
public int hashCode(){
return name.hashCode();
}
//當這個對象A取到某個小組之後 發現這個小組裡面有一個對象的哈希碼值和A對象的哈希碼值完全相同
//需要使用equals()定義的比較規則作比較
@Override
public boolean equals(Object obj){
if(obj == null) return false;
if(!(obj instanceof Student)) return false;
if(obj == this) return true;
System.out.println("===========================");
return this.name.equals(((Student)obj).name);
}
}
//輸出結果:
/**
s1:774889
s2:774889
size1:1
===========================
size2:1
*/
- 為保證兩個意義本來就不同的兩個對象不因偶然的重碼而被唯一性拒絕添加,需要使用equals()進行進一步确認,這也是equals()存在的必要性。
import java.util.*;
public class Test3{
public static void main(String[] args){
HashSet<Student> set = new HashSet<>();
Student s1 = new Student("小花",6,'女');//hashCode():6 + 1 = 7
Student s2 = new Student("小黑",7,'男');//hashCode():7 + 0 = 7,此時兩對象造成了重碼
set.add(s1);
set.add(s2);
System.out.println(set.size());
}
}
class Student{
String name;
int age;
char gender
public Student(String name,int age,char gender){
this.name = name;
this.age = age;
this.gender = gender;
}
@Override
public int hashCode(){
return age + (gender == '男'? 0 : 1);
}
@Override
public boolean equals(Object obj){
return this.age == ((Student)obj).age &&
this.gender == ((Student)obj).gender;
}
}
- 當什麼都沒有重寫,但傳入位址相同的一個對象時,hashCode()預設以位址生成特征碼。位址相同,特征碼模以組數的結果也相同,兩個對象去往同一個小組,之後比較位址,因位址相同視為同一對象,舍棄新加入的那個重複對象。
import java.util.*;
public class Test4{
public static void main(String[] args){
HashSet<Student> set = new HashSet<>();
Student s = new Student("Tom",21);
set.add(s);
set.add(s);
System.out.println(set.size());//--->1
}
}
class Student{
String name;
int age;
public Student(String name,int age){
this.name = name;
this.age = age;
}
}
- remove(Object obj)、contains(Object obj)在操作元素時也需要判斷hashCode()、equals()。
import java.util.*;
public class Test5{
public static void main(String[] args){
HashSet<Student> set = new HashSet<>();
Student s1 = new Student("張三");
Student s2 = new Student("李四");
set.add(s1);
System.out.println(set.contains(s2));//false
System.out.println(set);//[張三]
set.remove(s2);
System.out.println(set);//[張三]
}
}
class Student{
String name;
public Student(String name){
this.name = name;
}
@Override
public int hashCode(){
return 1;
}
@Override
public boolean equals(Object obj){
if(obj == null) return false;
if(!(obj instanceof Student)) return false;
if(obj == this) return true;
return false;
}
@Override
public String toString(){
return name;
}
}
- 例:
import java.util.*;
public class Example{
public static void main(String[] args){
HashSet<Teacher> set = new HashSet<>();
Teacher t1 = new Teacher("Tom",33,8000.0);
Teacher t2 = new Teacher("Tom",35,8000.0);
Collections.addAll(set,t1,t2);
System.out.println(set.size());//--->1
}
}
class Teacher{
String name;
int age;
double salary;
public Teacher(String name,int age,double salary){
this.name = name;
this.age = age;
this.salary = salary;
}
@Override
public int hashCode(){
return name.hashCode() + (int)salary;
}
@Override
public boolean equals(Object obj){
if(obj == null) return false;
if(!(obj instanceof Teacher)) return false;
if(obj == this) return true;
return this.name.equals(((Teacher)obj).name) &&
this.salary == ((Teacher)obj).salary;
}
}
4 增删改時需要注意
除注意疊代器中使用調用這個疊代器的集合的remove()、add()會出現CME異常,需要使用疊代器的remove()方法以及新建立LinkedList來臨時接收新添加的元素在循環結束時addAll到老集合中以外,HashSet集合還需要注意當一個對象已經添加進HashSet集合之後,不要随意修改其中參與生成哈希碼值的屬性值。
import java.util.*;
public class Test{
public static void main(String[] args){
HashSet<Teacher> set = new HashSet<>();
Teacher tea = new Teacher("張三",21);
set.add(tea);
//在原有的對象上直接操作,會緻使其hashCode發生改變
//但還是會位于原來的分組,分組出現錯誤
//是以後面要删除時,參照物到正确的分組中找不到這個修改後的元素
tea.age += 11;
//tea這個參照物無法根據hashCode()、位址以及equals()在這個分組找到要删除的元素
//既而無法删除改變後的這個元素
set.remove(tea);
System.out.println(set);//--->[張三:32]
//再添加相同的元素還可以添加,因為正确的分組中還不存在這個元素
//直接修改後的元素在錯誤的分組中
set.add(tea);
System.out.println(set);//--->[張三:32, 張三:32]
}
}
class Teacher{
String name;
int age;
public Teacher(String name,int age){
this.name = name;
this.age = age;
}
@Override
public String toString(){
return name + ":" + age;
}
@Override
public int hashCode(){
return name.hashCode() + age;
}
@Override
public boolean equals(Object obj){
if(obj == null) return false;
if(!(obj instanceof Teacher)) return false;
if(obj == this) return true;
return this.name.equals(((Teacher)obj).name) &&
this.age == ((Teacher)obj).age;
}
}
- 改後
import java.util.*;
public class Test{
public static void main(String[] args){
HashSet<Teacher> set = new HashSet<>();
Teacher tea = new Teacher("張三",21);
set.add(tea);
set.remove(tea);
tea.age += 11;
set.add(tea);
System.out.println(set);//--->[張三:32]
set.add(tea);
System.out.println(set);//--->[張三:32]
}
}
class Teacher{
String name;
int age;
public Teacher(String name,int age){
this.name = name;
this.age = age;
}
@Override
public String toString(){
return name + ":" + age;
}
@Override
public int hashCode(){
return name.hashCode() + age;
}
@Override
public boolean equals(Object obj){
if(obj == null) return false;
if(!(obj instanceof Teacher)) return false;
if(obj == this) return true;
return this.name.equals(((Teacher)obj).name) &&
this.age == ((Teacher)obj).age;
}
}
- 當一個對象已經添加進HashSet集合之後,修改其中未參與生成哈希碼值的屬性值,哈希碼值不變,此時可以直接删除元素。
import java.util.*;
public class TestHashSet8{
public static void main(String[] args){
HashSet<Teacher> set = new HashSet<>();
Teacher tea = new Teacher("李四",20);
set.add(tea);
tea.name = "王五";
set.remove(tea);
System.out.println(set);//[]
}
}
class Teacher{
String name;
int age;
public Teacher(String name,int age){
this.name = name;
this.age = age;
}
@Override
public String toString(){
return name + ":" + age;
}
@Override
public int hashCode(){
return age;
}
@Override
public boolean equals(Object obj){
if(obj == null) return false;
if(!(obj instanceof Teacher)) return false;
if(obj == this) return true;
return this.age == ((Teacher)obj).age;
}
}
-
總結
在每個改寫了equals()方法的類中,必須要改寫hashCode()方法。 如果不這樣做,就會違反Object.hashCode()的通用約定,進而導緻該類無法與所有基于hash的集合類結合在一起正常運作。** 這樣的集合類包括HashMap、HashSet和HashTable。
![Set集合---- HashSet集合、LinedHashSet集合、TreeSet集合[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)