前言
前不久,公司有一項業務需要給出下一周的的預測(這是公司業務,這裡不細說)。于是,我接觸到了機器學習領域的知識,我覺得機器學習真是一個很奇妙的領域,它是一門交叉的學科,對各個業務領域沖擊性很大。可以說,在任何領域都有運用機器學習的相關知識。
我并沒有很完善的數學理論基礎,但我會用我自己的了解來講述所涉及到的算法,我想這樣也是有好處的,那就是将複雜難懂的公式轉換成了更接地氣更讓人明白的方式展現給大家。接下來的内容,如果有錯,請大家多多指教。
正文
分類器就是以曆史資料的“特征向量-結果”集合為依據,在給定特征向量時預測對應的具體類别。
Example:你天天看都接觸人,當你再看到一個人時,你能分辨出它是男是女。
樸素貝葉斯分類器是基于貝葉斯定理實作的一種高效、容易了解、容易實作的分類器,樸素貝葉斯分類器适用于标稱型資料分類,即使資料規模不夠大時也能有效分類。
貝葉斯定理:
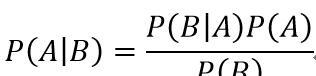
[MoonML]-樸素貝葉斯分類器 ,P(A|B)表示在B發生時A發生的機率
此時,我們就能明白樸素貝葉斯分類器的基本思想是什麼樣子的了。
就是當給定特征出現時,求類别出現的機率,比較出現不同類别的機率,找到最大機率,最大機率對應的類别就是我們預測的類别
Example:
我們來看一下P((a2,b1)|C=yes),由于兩個特征是相對獨立的,是以可以這樣計算:有兩個特征A={a1,a2,a3},B={b1,b2,b3},類别C={yes,no}
給定一個特征集合(a2,b1),求此特征集合資料什麼類别?
針對訓練樣本,進行計算:
根據貝葉斯定理計算:
P(C=yes|(a2,b1))=P((a2,b1)|C=yes)*P(C=yes)/P((a2,b1))
P(C=no|(a2,b1))=P((a2,b1)|C=no)*P(C=no)/P((a2,b1))
比較P(C=yes|(a2,b1))和P(C=no|(a2,b1))大小,誰大就是誰
這裡可以做一步優化,在進行比較時,由于分母P((a2,b1))的值是相等的,是以可以去掉P((a2,b1)),減少計算量P((a2,b1)|C=yes)=P(a2|C=yes)*P(b1|C=yes)
P(a2|C=yes)=(C=yes時出現a2的次數)/(C=yes出現的次數)
當單一特征出現的機率=0,那麼整個結果的機率就是0,這樣就會造成單一特征,影響整體結果(這個影響太大了),為了避免單一特征主導影響整體情況,當頻次等于0的時候,把分子分母都加1,表示此特征出現的機率特别特别的小
代碼實作
訓練樣本中特征向量共有10個元素(也就是每條資料10個特征),類别有兩個yes or no,共100條資料
這裡,我們可以把他當成銀行貸款,根據貸款人的十個特征(年齡、月收入、存款、是否已婚、是否有房等等),判斷貸款人是否是低風險使用者的例子
儲存樣本中記錄的特征,類别類
[MoonML]-樸素貝葉斯分類器
具體實作,這裡不多少了,代碼裡注釋寫的很清楚/** * @ClassName RecordWithFeaturesString * @Description 特征值為字元串類型的記錄 * @author "liumingxin" * @Date 2017年6月20日 下午1:57:28 * @version 1.0.0 */ public class RecordWithFeaturesString { private List<String> features;//特征集合 private Object category;//類别 public List<String> getFeatures() { return features; } public void setFeatures(List<String> features) { this.features = features; } public Object getCategory() { return category; } public void setCategory(Object category) { this.category = category; } }代碼我已經放在了github上了https://github.com/moonLazy/MoonML.gitpackage moon.ml.naivebayesian; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import moon.ml.record.RecordWithFeaturesString; /** * @ClassName NaiveBayesian * @Description 樸素貝葉斯分類器 * 對于給出的待分類特征向量,求出此特征時出現各個類别的機率, * 最大機率的類别就認為是哪一類别 * @author "liumingxin" * @Date 2017年6月23日 上午11:07:16 * @version 1.0.0 */ public class NaiveBayesian { /** * 讀取測試文檔 */ private static List<RecordWithFeaturesString> readTest(String fileIn) { List<RecordWithFeaturesString> outList = new ArrayList<RecordWithFeaturesString>(); try { File file = new File(fileIn); FileReader reader = new FileReader(file); BufferedReader in = new BufferedReader(reader); String line = null; while ((line = in.readLine()) != null) { RecordWithFeaturesString record = new RecordWithFeaturesString(); List<String> list = new ArrayList<String>(); String[] mArray = line.split(","); for (Integer i = 0; i < mArray.length - 1; i++) { list.add(mArray[i]); } record.setFeatures(list); record.setCategory(mArray[mArray.length - 1]); outList.add(record); } in.close(); reader.close(); } catch (Exception e) { System.out.println("讀取出錯"); e.printStackTrace(); } return outList; } /** * @Title: getCategoryRecordsMapper * @Description: 得到類型-記錄映射 * @param trainList * @return * @return Map<String,List<RecordWithFeaturesString>> */ private static Map<Object, List<RecordWithFeaturesString>> getCategoryRecordsMapper( List<RecordWithFeaturesString> trainList) { Map<Object, List<RecordWithFeaturesString>> categoryRecordsMapper = new HashMap<Object, List<RecordWithFeaturesString>>(); for (RecordWithFeaturesString record : trainList) { Object category = record.getCategory(); List<RecordWithFeaturesString> list = categoryRecordsMapper.get(category); if (list == null) { list = new ArrayList<RecordWithFeaturesString>(); } list.add(record); categoryRecordsMapper.put(category, list); } return categoryRecordsMapper; } /** * @Title: calFeatureIProbability * @Description: 計算第I個特征在集合中的機率,用于計算P(特征1|結果1) * @param records * @param testList * @param i * @return * @return double */ private static double calFeatureIProbability(List<RecordWithFeaturesString> records, List<String> testList, int i) { int fiCount = 0; int totalSize = records.size(); // 在類别C出現時第I個特征出現的機率 double featureIProbability = 1d; for (RecordWithFeaturesString record : records) { List<String> features = record.getFeatures(); if (features.size() == testList.size()) { String test = testList.get(i); String feature = features.get(i); if (test.equals(feature)) { fiCount++; } } } //P(特征1,特征2,特征3|結果1) = P(特征1|結果1)*P(特征2|結果1)*P(特征3|結果1) //當單一特征出現的機率=0,那麼整個結果的機率就是0,這樣就會造成單一特征,影響整體結果(這個影響太大了), //為了避免單一特征主導影響整體情況,當頻次等于0的時候,把分子分母都加1,表示此特征出現的機率特别特别的小 if(fiCount == 0){ fiCount++; totalSize++; } featureIProbability = (double) fiCount / totalSize; return featureIProbability; } /** * @Title: getResult * @Description: 得到結果 * @param trainList * 訓練集合 * @param testList * 測試資料 * @return Object */ public static Object getResult(List<RecordWithFeaturesString> trainList, List<String> testList) { int totalTrainList = trainList.size(); // 類型-記錄映射 Map<Object, List<RecordWithFeaturesString>> categoryRecordsMapper = getCategoryRecordsMapper(trainList); // 類型-機率映射,也就是最終結果 Map<Object, Double> categoryProbabilityMapper = new HashMap<Object, Double>(); // 計算類别機率 for (Object category : categoryRecordsMapper.keySet()) { List<RecordWithFeaturesString> records = categoryRecordsMapper.get(category); // 類别機率 double categoryProbability = (double) records.size() / totalTrainList; // 在類别C出現時第I個特征出現的機率 double featureIProbability = 1d; // P(特征1,特征2,特征3|結果1) = P(特征1|結果1)*P(特征2|結果1)*P(特征3|結果1),假設特征123互相獨立 for (int i = 0; i < testList.size(); i++) { featureIProbability = featureIProbability * calFeatureIProbability(records, testList, i); } // P(結果1|特征1,特征2,特征3) = // P(特征1,特征2,特征3|結果1)*P(結果1),因為P(特征1,特征2,特征3)相等,是以省略 featureIProbability = featureIProbability * categoryProbability; categoryProbabilityMapper.put(category, featureIProbability); } Object maxCategory = null; double maxProbability = 0d; for (Object category : categoryProbabilityMapper.keySet()) { double probability = categoryProbabilityMapper.get(category); if (probability > maxProbability) { maxProbability = probability; maxCategory = category; } } return maxCategory; } public static void main(String[] args) { //給定十個特征,求出資料哪一類别 String test1 = "6,1,9,1,2,3,1,2,2,1"; String[] testArr = test1.split(","); List<String> testList = new ArrayList<String>(); for (String str : testArr) { testList.add(str); } String trainTxt = "data/naivebayesian/naivebayesian1.txt"; // 讀取訓練資料 List<RecordWithFeaturesString> trainList = readTest(trainTxt); Object result = getResult(trainList, testList); System.out.println(result); } }