作者 | 姚維
面向的對象
本文主要面向對 TiDB 有一定了解的讀者,讀者在閱讀本文之前,推薦先閱讀講解 TiDB 原理的三篇文章(講存儲,說計算,談排程),以及 TiDB Best Practice。
場景
高并發批量插入場景,通常存在于業務系統中的批量任務中,例如清算以及結算等業務。它存在以下顯著的特點:
- 資料量大
- 需要短時間内将曆史資料入庫
- 需要短時間内讀取大量資料
這就對 TiDB 提出了一些挑戰:
- 寫入/讀取能力是否可以線性水準擴充
- 資料在持續大并發寫入,性能是否穩定不衰減
對于分布式資料庫來說,除了本身的基礎性能之外,最重要的就是充分利用所有節點能力,避免出現單個節點成為瓶頸。
TiDB 資料分布原理
如果要解決以上挑戰,需要從 TiDB 資料切分以及排程的原理開始講起。這裡隻是作簡單的說明,詳細請大家參見:談排程。
TiDB 對于資料的切分,按 Region 為機關,一個 Region 有大小限制(預設 96M)。Region 的切分方式是範圍切分。每個 Region 會有多副本,每一組副本,稱為一個 Raft-Group。由 Leader 負責執行這塊資料的讀 & 寫(當然 TiDB 即将支援 Follower-Read)。Leader 會自動地被 PD 元件均勻排程在不同的實體節點上,用以均分讀寫壓力。
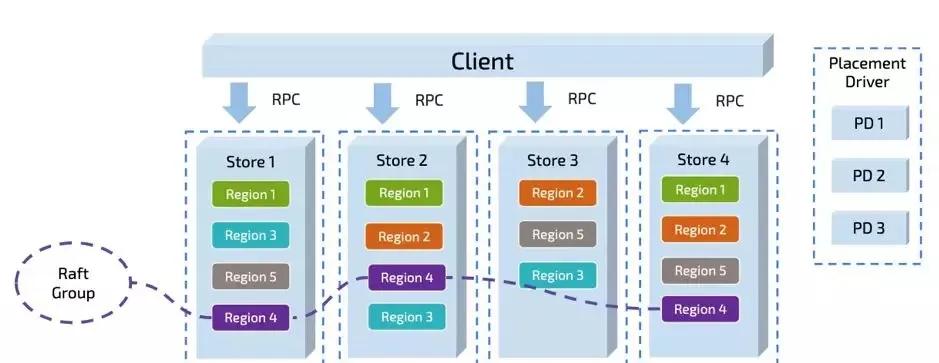
隻要業務的寫入沒有 AUTO_INCREMENT 的主鍵或者單調遞增的索引(也即沒有業務上的寫入熱點,更多細節參見 TiDB 正确使用方式)。從原理上來說,TiDB 依靠這個架構,是可以線性擴充讀寫能力,并且可以充分利用分布式的資源的。這一點上 TiDB 尤其适合高并發批量寫入場景的業務。
但是軟體世界裡,沒有銀彈。具體的事情還需要具體分析。我們接下來就通過一些簡單的負載來探讨 TiDB 在這種場景下,需要如何被正确的使用,才能達到此場景理論上的最佳性能。
簡單的例子
有一張簡單的表:
CREATE TABLE IF NOT EXISTS TEST_HOTSPOT(
id BIGINT PRIMARY KEY,
age INT,
user_name VARCHAR(32),
email VARCHAR(128)
) 這個表結構非常簡單,除了 id 為主鍵以外,沒有額外的二級索引。寫入的語句如下,id 通過随機數離散生成:
INSERT INTO TEST_HOTSPOT(id, age, user_name, email) values(%v, %v, '%v', '%v'); 負載是短時間内密集地執行以上寫入語句。
到目前為止,似乎已經符合了我們上述提到的 TiDB 最佳實踐了,業務上沒有熱點産生,隻要我們有足夠的機器,就可以充分利用 TiDB 的分布式能力了。要驗證這一點,我們可以在實驗環境中試一試(實驗環境部署拓撲是 2 個 TiDB 節點,3 個 PD 節點,6 個 TiKV 節點,請大家忽略 QPS,這裡的測試隻是為了闡述原理,并非 benchmark):

用戶端在短時間内發起了 “密集” 的寫入,TiDB 收到的請求是 3K QPS。如果沒有意外的話,壓力應該均攤給 6 個 TiKV 節點。但是從 TiKV 節點的 CPU 使用情況上看,存在明顯的寫入傾斜(tikv - 3 節點是寫入熱點):
Raft store CPU 代表 raftstore 線程的 CPU 使用率,通常代表着寫入的負載,在這個場景下 tikv-3 是 raft 的 leader,tikv-0 跟 tikv-1 是 raft 的 follower,其他的 tikv 節點的負載幾乎為空。
從 PD 的監控中也可以印證這一點:
反直覺的原因
上面這個現象是有一些違反直覺的,造成這個現象的原因是:剛建立表的時候,這個表在 TiKV 隻會對應為一個 Region,範圍是:
[CommonPrefix + TableID, CommonPrefix + TableID + 1) 對于在短時間内的大量寫入,它會持續寫入到同一個 Region。
上圖簡單描述了這個過程,持續寫入,TiKV 會将 Region 切分。但是由于是由原 Leader 所在的 Store 首先發起選舉,是以大機率下舊的 Store 會成為新切分好的兩個 Region 的 Leader。對于新切分好的 Region 2,3。也會重複之前發生在 Region 1 上的事情。也就是壓力會密集地集中在 TiKV-Node 1 中。
在持續寫入的過程中, PD 能發現 Node 1 中産生了熱點,它就會将 Leader 均分到其他的 Node 上。如果 TiKV 的節點數能多于副本數的話,還會發生 Region 的遷移,盡量往空閑的 Node 上遷移,這兩個操作在插入過程,在 PD 監控中也可以印證:
在持續寫入一段時間以後,整個叢集會被 PD 自動地排程成一個壓力均勻的狀态,到那個時候才會真正利用整個叢集的能力。對于大多數情況來說,這個是沒有問題的,這個階段屬于表 Region 的預熱階段。
但是對于高并發批量密集寫入場景來說,這個卻是應該避免的。
那麼我們能否跳過這個預熱的過程,直接将 Region 切分為預期的數量,提前排程到叢集的各個節點中呢?
解決方法
TiDB 在 v3.0.x 版本以及 v2.1.13 以後的版本支援了一個新特性叫做 Split Region。這個特性提供了新的文法:
SPLIT TABLE table_name [INDEX index_name] BETWEEN (lower_value) AND (upper_value) REGIONS region_num
SPLIT TABLE table_name [INDEX index_name] BY (value_list) [, (value_list)] 讀者可能會有疑問,為何 TiDB 不自動将這個切分動作提前完成?大家先看一下下圖:
從圖 8 可以知道,Table 行資料 key 的編碼之中,行資料唯一可變的是行 ID (rowID)。在 TiDB 中 rowID 是一個 Int64 整形。那麼是否我們将 Int64 整形範圍均勻切分成我們要的份數,然後均勻分布在不同的節點就可以解決問題呢?
答案是不一定,需要看情況,如果行 id 的寫入是完全離散的,那麼上述方式是可行的。但是如果行 id 或者索引是有固定的範圍或者字首的。例如,我隻在 [2000w, 5000w) 的範圍内離散插入,這種寫入依然是在業務上沒有熱點的,但是如果按上面的方式切分,那麼就有可能在開始也還是隻寫入到某個 Region。
作為通用的資料庫,TiDB 并不對資料的分布作假設,是以開始隻用一個 Region 來表達一個表,等到真實資料插入進來以後,TiDB 自動地根據這個資料的分布來作切分。這種方式是較通用的。
是以 TiDB 提供了 Split Region 文法,來專門針對短時批量寫入場景作優化,下面我們嘗試在上面的例子中用以下語句提前切散 Region,再看看負載情況。
由于測試的寫入是在正數範圍内完全離散,是以我們可以用以下語句,在 Int64 空間内提前将表切散為 128 個 Region:
SPLIT TABLE TEST_HOTSPOT BETWEEN (0) AND (9223372036854775807) REGIONS 128; 切分完成以後,可以通過
SHOW TABLE test_hotspot REGIONS;
語句檢視打散的情況,如果 SCATTERING 列值全部為 0,代表排程成功。
也可以通過 table-regions.py 腳本,檢視 Region 的分布,已經比較均勻了:
[[email protected] scripts]# python table-regions.py --host 172.16.4.3 --port 31453 test test_hotspot
[RECORD - test.test_hotspot] - Leaders Distribution:
total leader count: 127
store: 1, num_leaders: 21, percentage: 16.54%
store: 4, num_leaders: 20, percentage: 15.75%
store: 6, num_leaders: 21, percentage: 16.54%
store: 46, num_leaders: 21, percentage: 16.54%
store: 82, num_leaders: 23, percentage: 18.11%
store: 62, num_leaders: 21, percentage: 16.54% 我們再重新運作插入負載:
可以看到已經消除了明顯的熱點問題了。
當然,這裡隻是舉例了一個簡單的表,還有索引熱點的問題。如何預先切散索引相關的 Region?
這個問題可以留給讀者,通過 Split Region 文檔 可以獲得更多的資訊。
更複雜一些的情況
如果表沒有主鍵或者主鍵不是 int 類型,使用者也不想自己生成一個随機分布的主鍵 ID,TiDB 内部會有一個隐式的 _tidb_rowid 列作為行 id。在不使用 SHARD_ROW_ID_BITS 的情況下,_tidb_rowid 列的值基本上也是單調遞增的,此時也會有寫熱點存在。(檢視什麼是 SHARD_ROW_ID_BITS)
要避免由 _tidb_rowid 帶來的寫入熱點問題,可以在建表時,使用 SHARD_ROW_ID_BITS 和 PRE_SPLIT_REGIONS 這兩個建表 option(檢視什麼是 PRE_SPLIT_REGIONS)。
SHARD_ROW_ID_BITS 用來把 _tidb_rowid 列生成的行 ID 随機打散,pre_split_regions 用來在建完表後就預先 split region。注意:pre_split_regions 必須小于等于 shard_row_id_bits。
示例:
create table t (a int, b int) shard_row_id_bits = 4 pre_split_regions=·3; - SHARD_ROW_ID_BITS = 4 表示 tidb_rowid 的值會随機分布成 16 (16=2^4) 個範圍區間。
- pre_split_regions=3 表示建完表後提前 split 出 8 (2^3) 個 region。
在表 t 開始寫入後,資料寫入到提前 split 好的 8 個 region 中,這樣也避免了剛開始建表完後因為隻有一個 region 而存在的寫熱點問題。
參數配置
關閉 TiDB 的 Latch 機制
[txn-local-latches]
enabled = false