作者:張政俊
一. Coprocessor 簡介
在 TiDB整體架構中,資料是存在 TiKV 裡的,當 TiDB 在收到一個來自用戶端的查詢請求時,會向 TiKV 擷取具體的資料資訊。
那麼一個讀請求的流程如下:
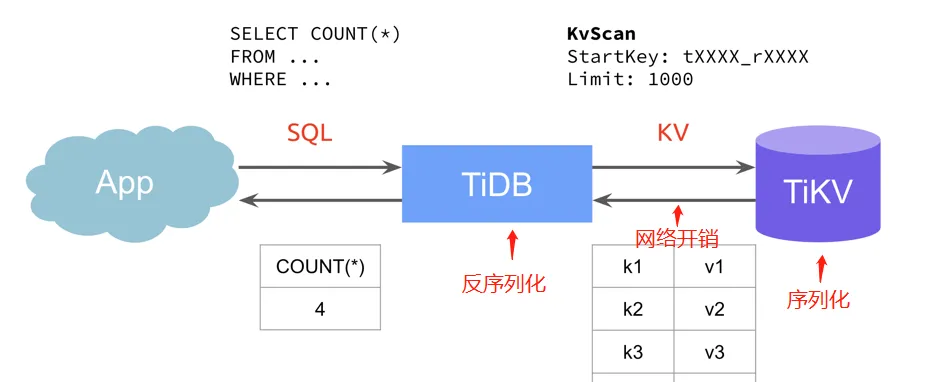
這種流程模式下主要有兩個問題:
- TiDB 負責計算所有資料,導緻 CPU 負載很大,而 TiKV 負載不大;
- TiKV 會傳回所有資料,網絡開銷大;
- 資料傳輸會先序列化,計算前再做反序列化,資料量大的場景下資源消耗大;
為了優化以上的問題,可以讓 TiKV 去承擔計算任務,處理完成後再傳回給 TiDB。
Coprocessor 就是 TiKV 中讀取資料并計算的子產品,它的實作類似于 HBase 中的 Coprocessor 的 Endpoint 部分,也可以類比 MySQL 的存儲過程。
二. 語句處理
看下讀請求是如何下發到 TiKV 的:

- TiDB 收到查詢語句,對語句進行分析,計算出實體執行計劃,組織稱 TiKV 的 Coprocessor 請求。
- TiDB 将該 Coprocessor 請求根據資料的分布,分發到所有相關的 TiKV 上。
- TiKV 在收到該 Coprocessor 請求後,根據請求算子對資料進行過濾聚合,然後傳回給 TiDB。
- TiDB 在收到所有資料的傳回結果後,進行二次聚合,并将最終結果計算出來,傳回給用戶端。
1. 火山模型
一條讀請求,使用 Table Scan 算子,需要掃出所有行的需求列,性能不高。3.0 之前使用的是火山模型去讓請求隻需要掃幾行。
SELECT * FROM table WHERE age > 10 limit 1
Limit
每次都從下層算子取一行,至多取 LIMIT 行,傳回給上層
Selection
不斷從下層算子取一行,按照 age > 10 為過濾條件,知道有一條滿足條件了傳回給上層
Table Scan
掃下一行的 age 列 傳回給上層
優缺點
- 優點:
- 掃的數最少,記憶體開銷少
- 缺點:
- 每次隻能處理一行資料,非掃表的算子性能比較低
2. 向量化模型(3.0之後)
- 算子之間每次都接受多行、處理多行、傳回多行;
- 函數表達式按列計算
- 聚合表達式按列計算
所謂的向量化,就是在 Executor 間傳遞的不再是單單的一行,而是多行,比如 TableScan 在底層 MVCC Snapshot 中掃上來的不再是一行,而是說多行。在算子執行計算任務的時候,計算的單元也不再是一個标量,而是一個向量。舉個例子,當遇到一個表達式:a + b 的時候, 我們不是計算一行裡邊 a 列和 b 列兩個标量相加的結果,而是計算 a 列和 b 列兩列相加的結果。
TableScan
根據指定主鍵範圍掃表資料,并過濾出一部分列傳回。它隻會作為最底層算子出現,從底層 KV 擷取資料。
select col from t IndexScan
根據指定索引傳回掃索引資料,并過濾出一部分索引列傳回。它隻會作為最底層算子出現,從底層 KV 擷取資料。
select index from t Selection
對底層算子的結果按照過濾條件進行過濾,其中這些條件由多個表達式組成。
select col from t where a+b=10
Limit
從底層算子吐出的資料中,限定傳回若幹行。
select col from t limit 10
TopN
按照給定表達式進行排序後,取出前若幹行資料。
select col from t order by a+1 limit 10
Aggregation
按照給定表達式進行分組、聚合。
select count(1) from t group by score + 1
混用算子
select count(1) from t where age>10
三. Coprocessor 部分知識點
- Coprocessor 隻能加速查詢類請求,不能用于支撐寫入的需求。也就是說 TiKV 是必須要的,不能隻使用 Coprocessor 接口;
- TiDB 上幾乎的查詢請求都是通過 Coprocessor 完成的。對于極少數的場景,比如點查,TiDB 會直接調用點查接口(Kv get),避免走到 Coprocessor 龐大的架構下執行,進而提升了性能;
- 除了 select 其他 DML 操作也可以走 Coprocessor;
- TiKV 隻能算出中間結果,需要 TiDB 去做彙集并計算最終結果。比如排序取前10的需求,需要每個 TiKV 取前10,然後 TiDB 去彙總再排序,才能取到需要的值;
- TiKV 的算子執行邏輯和 TiDB 的邏輯是不一樣的。比如請求是 AVG(),TiKV 傳回的是 sum 或者 count,AVG() 是在 TiDB 裡實作的;
四. Coprocessor cache
最新 v5.0.0 版本的 release notes 中寫到,5.0 GA 預設開啟 Coprocessor cache 功能。
開啟該功能後,TiDB 會在 tidb-server 中緩存算子下推到 tikv-server 計算後的結果,降低讀取資料的延時。
要關閉 Coprocessor cache 功能,可以修改
tikv-client.copr-cache
的
capacity-mb
配置項為 0.0。
- capacity-mb
- 緩存的總資料量大小。當緩存空間滿時,舊緩存條目将被逐出。值為 0.0 時表示關閉 Coprocessor Cache。
- 預設值:1000.0
- 機關:MB
- 類型:Float
參考資料:
MySQL at Scale. No more manual sharding
TiKV 源碼解析系列文章(十四)Coprocessor 概覽 | PingCAP
本文将簡要介紹 TiKV Coprocessor 的基本原理,面向想要了解 TiKV 資料讀取執行過程的同學,同時也面向想對該子產品貢獻代碼的同學。
MySQL at Scale. No more manual sharding