作者:靳獻旗,汽車之家 DBA
【目錄】
1.背景介紹
2.跨機房方案概述
3.工作原理
4.叢集架構
5.部署步驟
6.線上使用情況
7.展望
【正文】
1. 背景介紹
公司要求對 0 級應用做跨機房部署,當 A 機房整體故障時,業務可以快速切到 B 機房繼續提供服務。恰好也涉及到了幾套 TiDB 叢集相關業務,這裡做一下總結和回顧,希望能夠幫助需要的使用者。本文主要涉及下面幾項内容:
● 幾種基于 TiDB 的跨機房部署方案及優缺點
● 基于 Binlog 跨機房雙向複制的詳細部署步驟
● 線上 TiDB 跨機房使用情況及展望
2. 跨機房方案概述
下面介紹下 TiDB 幾種跨機房叢集部署方案的優缺點:
| 序号 | 方案 | 優點 | 缺點 | | -- | ------------------------------- | --------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------- | | 1 | 同城三中心 | 是完美适配TiDB的部署方式 1.提供單一中心故障的自動故障轉移能力 2.同城多活,資源最大化利用,所有副本都能參與計算 3.較低的成本(同城裸光纖) | 絕大多數使用者不具備同城三中心條件 | | 2 | 同城雙中心可用區方案(同中心的多個可用區在一定程度上實體隔離) | 1.提供單一可用區故障的自動故障轉移能力 2.同城多活,資源最大化利用,所有副本都能參與計算 3.較低的成本(同城裸光纖) | 無法容忍包含多個可用區的機房整體故障 | | 3 | 兩地三中心 | 1.提供單一可用區故障的自動故障轉移能力 2.同城雙活 | 1.成本過高 2.收益低(高網絡延遲,異地中心的部分不參與計算) 3.隻依賴異地的副本無法恢複一緻性(RPO=0)的資料,其異地容災能力與主從叢集方案差别不大 | | 4 | 同城雙中心 Raft 複制 | 1.提供災備中心故障的自動故障轉移能力 2.同城雙活 3.資源最大化利用,所有副本都能參與計算 4.較低的成本(同城裸光纖) | 隻能容忍災備機房故障,缺乏實際意義 | | 5 | 同城雙中心自适應同步複制 | 1.提供災備中心故障的自動故障轉移能力 2.提供主中心故障時的災備機房資料手工恢複的能力 3.同城雙活 4.資源最大化利用,所有副本都能參與計算 5.較低的成本(同城裸光纖) | 方案還外部試點測試中,預計2021年下半年達到生産級别可用 |
目前公司是同城雙中心,是以上述方案排除掉1、2、3方案,4方案缺乏實際意義,5方案還不成熟,是以4、5也排除掉。難道沒有方案可用?下面還有兩種方案沒提到,這裡從技術層面分析下兩種方案的優缺點。
| 序号 | 方案 | 優點 | 缺點 | | -- | -------------- | --------------- | -------------------------- | | 6 | 基于 Binlog 雙向複制 | 1.成熟穩定 | 1.Drainer 不具備高可用 2.并發處理不足 | | 7 | 基于 TiCDC 雙向複制 | 1.具備高可用 2.并發處理強 | 1.官方未 GA 2.記憶體使用較大 3.複制中斷問題 |
經過分析,我們最終選擇了過度方案 6 :基于 Binlog 雙向複制部署跨機房叢集。後續時間成熟,我們會更新到方案 7 或者 5。
3. 工作原理
下面簡單描述下基于 Binlog 雙向同步的工作原理
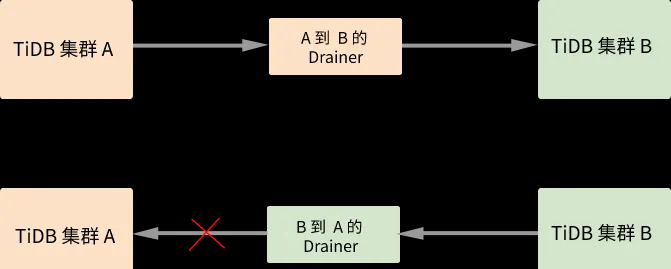
在 A 和 B 兩個叢集間開啟雙向同步,則寫入叢集 A 的資料會同步到叢集 B 中,然後這部分資料又會繼續同步到叢集 A,這樣就會出現無限循環同步的情況。如上圖所示,在同步資料的過程中 Drainer 對 Binlog 加上标記,通過過濾掉有标記的 Binlog 來避免循環同步。詳細的實作流程如下:
(1)為兩個叢集分别啟動 TiDB Binlog 同步程式。
(2)待同步的事務經過 A 的 Drainer 時,Drainer 為事務加入 _drainer_repl_mark 辨別表,并在表中寫入本次 DML event 更新,将事務同步至叢集 B。
(3)叢集 B 向叢集 A 傳回帶有 _drainer_repl_mark 辨別表的 Binlog event。叢集 B 的 Drainer 在解析該 Binlog event 時發現帶有 DML event 的辨別表,放棄同步該 Binlog event 到叢集 A。
● 注意事項:
叢集間雙向同步的前提條件是,寫入兩個叢集的資料必須保證無沖突,即在兩個叢集中,不會同時修改同一張表的同一主鍵和具有唯一索引的行。
更詳細的内容請參考官方文檔
https://docs.pingcap.com/zh/TiDB/stable/bidirectional-replication-between-TiDB-clusters#%E9%9B%86%E7%BE%A4%E9%97%B4%E5%8F%8C%E5%90%91%E5%90%8C%E6%AD%A5
4. 叢集架構
叢集資訊如下:
叢集 A (位于機房 A,ip 做了脫敏處理)
| IP | 版本 | 元件 | 配置 |
| 192.168.1.1 | 4.0.9 | TiDB/PD/Pump/Drainer | 記憶體:256G 硬碟:SATA SSD CPU:48核 網卡:萬兆 |
| 192.168.1.2 | 4.0.9 | TiDB/PD/Pump | |
| 192.168.1.3 | 4.0.9 | TiDB/PD/Pump | |
| 192.168.1.4 | 4.0.9 | 2個TiKV | 記憶體:256G 硬碟:SATA SSD CPU:64核 網卡:萬兆 |
| 192.168.1.5 | 4.0.9 | 2個TiKV | |
| 192.168.1.6 | 4.0.9 | 2個TiKV | |
| 192.168.1.7 | 4.0.9 | 2個TiKV |
叢集 B (位于機房 B,ip 做了脫敏處理)
| IP | 版本 | 元件 | 配置 |
| 192.168.2.1 | 4.0.9 | TiDB/PD/Pump/Drainer | 記憶體:256G 硬碟:SATA SSD CPU:48核 網卡:萬兆 |
| 192.168.2.2 | 4.0.9 | TiDB/PD/Pump | |
| 192.168.2.3 | 4.0.9 | TiDB/PD/Pump | |
| 192.168.2.4 | 4.0.9 | 2個TiKV | 記憶體:256G 硬碟:SATA SSD CPU:64核 網卡:萬兆 |
| 192.168.2.5 | 4.0.9 | 2個TiKV | |
| 192.168.2.6 | 4.0.9 | 2個TiKV | |
| 192.168.2.7 | 4.0.9 | 2個TiKV |
叢集架構如下

5. 部署步驟
本節詳細介紹基于 Binlog 的跨機房部署步驟,這裡以 TiDB 4.0.9 版本為例,對一個線上未開啟 Binlog 的叢集配置跨機房複制。主要分為兩部配置設定置:A 叢集配置,B 叢集配置。
● A 叢集配置步驟概要
(1)A 叢集部署 Pump
(2)A 叢集開啟 Binlog
(3)A 叢集導出全量資料,将全量資料導入 B 叢集
(4)A 叢集配置 drainer ,實作增量複制
● B 叢集部署步驟概要
(1)B 叢集部署 Pump
(2)B 叢集開啟 Binlog
(3)B 叢集配置 drainer ,實作反向複制
5.1 A 叢集部署步驟
【 A 叢集部署 Pump 】
- 編寫 Pump 擴容拓撲配置
vim scale_out_pump.yaml
pump_servers:
- host: 192.168.1.1
ssh_port: 22
port: 8250
deploy_dir: /data/pump-8250
data_dir: /data/pump-8250/data.pump
log_dir: /data/pump-8250/log
config:
gc: 3 #指定 binlog 可在本地存儲的天數,超過指定天數的 binlog 會被自動删除
- host: 192.168.1.2
ssh_port: 22
port: 8250
deploy_dir: /data/pump-8250
data_dir: /data/pump-8250/data.pump
log_dir: /data/pump-8250/log
config:
gc: 3
- host: 192.168.1.3
ssh_port: 22
port: 8250
deploy_dir: /data/pump-8250
data_dir: /data/pump-8250/data.pump
log_dir: /data/pump-8250/log
config:
gc: 3 - 執行下面指令擴容 Pump
tiup cluster scale-out a_cluster scale_out_pump.yaml - 檢視 Pump 狀态
tiup cluster display a_cluster - 登入 TiDB 檢視 Pump 狀态
show pump status; 【 A 叢集開啟 Binlog 】
- 編輯 A 叢集配置檔案開啟 Binlog
tiup cluster edit-config a_cluster
server_configs:
TiDB:
binlog.enable: true # 設定為 true 開啟 Binlog
binlog.ignore-error: true # 建議設定為 true ,否則 Binlog 無法寫入時會導緻整個叢集無法寫入資料 - 滾動重新開機 TiDB-server
tiup cluster reload a_cluster -R tidb - 登入 TiDB 确認目前叢集是否開啟 Binlog
show global variables like 'log_bin'; # 1 表示開啟 【 A 叢集導出全量資料,将全量資料導入 B 叢集 】
1.A 叢集導出全量資料
/data/tidb-tools/bin/dumpling -h 192.168.1.1 -P 4000 -u username -p password --params="TiDB_isolation_read_engines=tikv" --filetype sql --tidb-mem-quota-query 8589934592 --threads 2 -r 500000 -F 200MiB -o /data/bak_4000_20210522 -f 'sms_send.*' -f 'rcm_pool.*' --loglevel debug --logfile dumpling_20210522.log 2.将全量資料導入 B 叢集
/data/tidb-tools/bin/loader -h 192.168.2.1 -P 4000 -u username -p password -t 4 -d /data/bak_4000_20210522 【 A 配置 Drainer 實作增量複制 】
- 編寫 Drainer 擴容拓撲配置
vim scale_out_drainer.yaml
drainer_servers:
- host: 192.168.1.1
ssh_port: 22
port: 8249
commit_ts: 425112071610302470 #從上一步的 /data/tmp/bak_20210522/metadata 檔案擷取
deploy_dir: /data/drainer-8249
data_dir: /data/drainer-8249/data
log_dir: /data/drainer-8249/log
config:
syncer.loopback-control: true
syncer.channel-id: 123456 #互相同步的兩個叢集配置相同的 ID
syncer.sync-ddl: true #需要同步 DDL 操作
syncer.db-type: tidb
syncer.ignore-schemas: INFORMATION_SCHEMA,METRICS_SCHEMA,PERFORMANCE_SCHEMA,mysql,test
syncer.ignore-table: #忽略 checkpoint 表
- db-name: tidb_binlog
tbl-name: checkpoint
syncer.to.host: 192.168.2.1 #下遊 TiDB 叢集 ip
syncer.to.port: 4000 #下遊 TiDB 叢集 port
syncer.to.sync-mode: 1
syncer.to.password: password #下遊使用者的密碼
syncer.to.user: drainer_user #下遊使用者,需要提前在下遊 TiDB 叢集建立
syncer.txn-batch: 200 #将 DML 分批執行,用于設定每個事務中包含多少個 DML
syncer.worker-count: 4 #指定并發數 - 執行下面指令擴容 Drainer
tiup cluster scale-out a_cluster scale_out_drainer.yaml - 檢視 Drainer 狀态
tiup cluster display a_cluster 4.登入 TiDB 檢視 Drainer 狀态
show drainer status; 5.2 B 叢集部署步驟
【 B 叢集部署 Pump 】
- 編寫 Pump 擴容拓撲配置
vim scale_out_pump.yaml
pump_servers:
- host: 192.168.2.1
ssh_port: 22
port: 8250
deploy_dir: /data/pump-8250
data_dir: /data/pump-8250/data.pump
log_dir: /data/pump-8250/log
config:
gc: 3
- host: 192.168.2.2
ssh_port: 22
port: 8250
deploy_dir: /data/pump-8250
data_dir: /data/pump-8250/data.pump
log_dir: /data/pump-8250/log
config:
gc: 3
- host: 192.168.2.3
ssh_port: 22
port: 8250
deploy_dir: /data/pump-8250
data_dir: /data/pump-8250/data.pump
log_dir: /data/pump-8250/log
config:
gc: 3 - 執行下面指令擴容 Pump
tiup cluster scale-out b_cluster scale_out_pump.yaml - 檢視 Pump 狀态
tiup cluster display b_cluster - 登入 TiDB 檢視 Pump 狀态
show pump status; 【 B 叢集開啟 Binlog 】
- 編輯 B 叢集配置檔案開啟 Binlog
tiup cluster edit-config b_cluster
server_configs:
TiDB:
binlog.enable: true # 設定為 true 開啟 Binlog
binlog.ignore-error: true # 建議設定為 true ,否則 Binlog 無法寫入時會導緻整個叢集無法寫入資料 - 滾動重新開機 TiDB-server
tiup cluster reload b_cluster -R TiDB - 确認目前叢集是否開啟 Binlog
show global variables like 'log_bin'; # 1 表示開啟 【 B 配置 Drainer 實作反向複制 】
- 編寫 Drainer 擴容拓撲配置
vim scale_out_drainer.yaml
drainer_servers:
- host: 192.168.2.1
ssh_port: 22
port: 8249
deploy_dir: /data/drainer-8249
data_dir: /data/drainer-8249/data
log_dir: /data/drainer-8249/log
config:
syncer.loopback-control: true
syncer.channel-id: 123456 #互相同步的兩個叢集配置相同的 ID
syncer.sync-ddl: false #不需要同步 DDL 操作
syncer.db-type: tidb
syncer.ignore-schemas: INFORMATION_SCHEMA,METRICS_SCHEMA,PERFORMANCE_SCHEMA,mysql,test
syncer.ignore-table: #忽略 checkpoint 表
- db-name: tidb_binlog
tbl-name: checkpoint
syncer.to.host: 192.168.1.1 #下遊 TiDB 叢集 ip
syncer.to.port: 4000 #下遊 TiDB 叢集 port
syncer.to.sync-mode: 1
syncer.to.password: password #下遊使用者的密碼
syncer.to.user: drainer_user #下遊使用者,需要提前在下遊 TiDB 叢集建立
syncer.txn-batch: 200
syncer.worker-count: 2 - 執行下面指令擴容 Drainer
tiup cluster scale-out b_cluster scale_out_drainer.yaml - 檢視 Drainer 狀态
tiup cluster display b_cluster 4.登入 TiDB 檢視 Drainer 狀态
show drainer status; 5.3 測試雙向複制
我們重點對下面幾種場景做了測試:
| 序号 | 測試内容 | 測試結果 | | -- | --------------------- | ---- | | 1 | A 叢集資料同步到 B 叢集是否正常 | 正常 | | 2 | B 叢集資料同步到 A 叢集是否正常 | 正常 | | 3 | A 叢集 DDL 同步到 B 叢集是否正常 | 正常 | | 4 | B 叢集 DDL 不能同步到 A 叢集 | 無法同步 |
6. 線上使用情況
目前線上有3套 TiDB 叢集做了跨機房部署,如下表所示:
| 叢集資訊 | 業務說明 | 跨機房部署說明 | 運作時間 |
| 叢集1 | 短信業務 | 庫級别雙向複制 | 2020/10 — 至今 |
| 叢集2 | 使用者中心登入注冊相關接口 | 庫級别雙向複制 | 2021/05 — 至今 |
| 叢集3 | 資源池 | 叢集級别雙向複制 | 2021/05 — 至今 |