作者:張魚小丸子-PingCAP
背景
資料庫運作 SQL 時需要盡量選擇最優的 Plan,來保證 SQL 執行的效率
一個最主要的名額是根據不同 Plan 的 row count 來判斷優劣
統計資訊就是用來估算不同 plan 的 row count
一、統計資訊組成部分
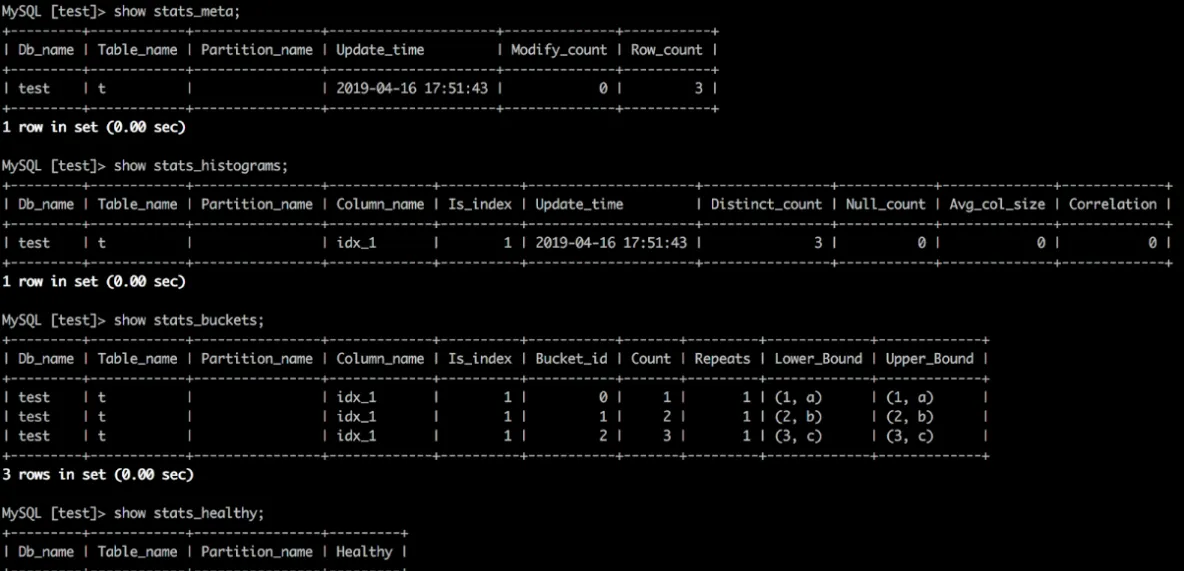
- show stats_meta;
- show stats_histograms;
- show stats_buckets;
- show stats_healthy;
1、表級别
- Modify_count
- Row_count
2、列級别
- Histogram
直方圖,主要在 range 查詢場景中用到
- Count-Min Sketch
在點查場景中使用
- Distinct count
某一列有多少個不同的值
- Null count
某一列有多少個 Null 值
- Avg col size
某一列的平均大小,可以忽略掉
- Correlation
在 master 版本新增的功能,還在改進中,目的是使 order by limit n 場景盡量走 index scan 而不是 table scan
二、直方圖(Histogram)
1、概念

- Histogram 主要用于 range 查詢場景。
例如:select count(*) from t where a > 1 and a < 10
- 在 TiDB 中我們選擇的是等深的直方圖,每個 bucket 的 range 不會重疊。
- 橫坐标是每個 bucket 的範圍;其中複合索引的場景,橫坐标是 encode 之後的值,與在 tikv 中存儲的索引資料的 key 相關。
- 縱坐标表示桶深,可以了解為是對應 bucket 的 row count。
- 對于每一個 bucket,我們認為資料是均勻分布的。
- 估算之後,會選擇 count 值最小的 plan 來執行
2、估算邏輯
- 當一個查詢完全覆寫了一個 bucket,這個 bucket 的高度就是 row count 的值。
- 當一個查詢覆寫了一個 bucket 的一部分,我們隻需要計算這個 range 占整個 bucket 的比例,然後與桶深相稱即可。
比如 (2.00, 2.75) 是一個 bucket,當查詢的範圍是 (2.15, 2.50) 時,rowCount(2.15, 2.5.0) = (2.50 - 2.15) / (2.75 - 2.00) * rowCount(2.00, 2.75)
- 當一個查詢覆寫了多個 bucket,計算方法與上面類似。
3、Bytes 類型的估算
由于存在 Bytes 或者 String 類型的資料,不能簡單的按照上面的方法計算。關于資料在 kv 中的存儲這裡不再贅述,可以看一下我們官網部落格。以索引為例,在 TiDB 中的估算方法如下:
- 首先将索引的 key(包含 tableID、indexID、indexColumnValue 等) 中的相同字首去掉,這部分相同的字首對于估算沒有影響。
- 剩餘的内容還是不能直接計算,這裡我們會将前 8 個 Bytes 轉換成 uint64,然後再用上面的方式計算
三、Count-Min Sketch
适用于在等值查詢場景下 Plan 的選擇
例如:select count(*) from t where a = 1
可以了解為在 TiDB 中維護了一個 d(行) * w(列) 的表
1、Count 統計
在插入資料(這裡包含表資料和索引資料)的時候,會在 d 個 Hash 函數裡面對寫入的 Calue 做計算,映射到每一行的 [0, w) 區間的一個格子中,然後在對應的格子上 Count + 1。
2、估算 Count
由于同一個格子的資訊可能會由于其他資料的寫入而更新,當做估算的時候,會以 d 個 Count 中的最小值為準,這個值也最接近真實值。
當一個 SQL 執行時,會分别對多個索引或者表資料按照上面方式進行估算(每個一個索引或者資料的估算值都是取 d 個 Count 的最小值),然後對不同索引或者資料的 Count 值作對比,選擇 Count 最小的 Plan。
四、Multi-column selecttivity
目前在 TIDB 上沒有多列(這裡是指聯合索引之外的,可以是單列索引或者無索引)的統計資訊,當遇到多列條件的查詢時,我們按以下方式來估算。
1、獨立性假設
當查詢中的多列沒有聯合索引時,我們認為多列之間是不相關的或者相關性很低的,這時候我們就可以用下面示例中的方式來估算。
select count(*) from t where a = 1 and b < 1 and c > 1;
表中沒有 a,b,c 這三個字段任意組合的聯合索引,估算方式為:
sel(a = 1 and b < 1 and c >1) = sel(a = 1) * sel(b < 1) * sel(c > 1)
2、有聯合索引的多列查詢
當查詢中的多列存在聯合索引時,我們将其轉化為範圍查詢或者等值查詢,下面舉例說明。
2.1、範圍查詢
範圍查詢參考直方圖(Histogram)的方式,使用聯合索引 Encode 之後的範圍來估算
select count(*) from t where a = 1 and b < 1;
表中存在 a,b 的聯合索引,估算方式為:
sel(a = 1 and b < 1) = sel([a=1, b=-inf), [a=1, b=1))
2.2、等值查詢
等值查詢參考 Count-Min Sketch 的方式,通過查 Encode 之後的聯合索引的 Value 對應的 Count 值來估算
select count(*) from t where a = 1 and b = 1;
表中存在 a,b 的聯合索引,估算方式為:
五、估算不準的場景
- 統計資訊過期
- 獨立性假設場景不适用,這種估算的數值和真實值差距比較大,可能會導緻選到比較差的索引,或者掃全表