druid 可以運作在單機環境下,也可以運作在叢集環境下。簡單起見,我們先從單機環境着手學習。
環境要求
- java7 或者更高版本
- linux, macOS或者其他unix系統(不支援windows系統)
- 8G記憶體
- 2核CPU
開始
下載下傳并安裝druid
curl -O http://static.druid.io/artifacts/releases/druid-0.9.1.1-bin.tar.gz
tar -xzf druid-0.9.1.1-bin.tar.gz
cd druid-0.9.1.1 檔案夾中有如下幾個目錄:
- LICENSE 許可證
- bin/ 可執行腳本
- conf/* 在叢集環境下的配置檔案
- conf-quickstart/* quickstart的配置檔案
- extensions/* druid所有的擴充檔案
- hadoop-dependencies/* druid的hadoop擴充檔案
- lib/* druid 依賴的核心軟體包
- quickstart/* quickstart的資料檔案
ZK安裝
druid的分布式協同需要依賴zookeeper,是以我們需要安裝zk
curl http://www.gtlib.gatech.edu/pub/apache/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz -o zookeeper-3.4.6.tar.gz
tar -xzf zookeeper-3.4.6.tar.gz
cd zookeeper-3.4.6
cp conf/zoo_sample.cfg conf/zoo.cfg
./bin/zkServer.sh start 啟動druid服務
啟動zk後,我們就可以啟動druid的服務了。 首先進入到druid0.9.1.1的根目錄,執行
bin/init
druid會自動建立一個var目錄, 内含倆個目錄,一個是druid, 用于存放本地環境下hadoop的臨時檔案,索引日志,segments檔案及緩存 和 任務的臨時檔案。 另一個是tmp用于存放其他臨時檔案。
接下來就可以在控制台啟動druid服務了。 在單機情況下,我們可以在一台機器上啟動所有的druid服務程序,分終端進行。 在分布式生産叢集的環境下, druid的服務程序同樣也可以在一起啟動。
ava `cat conf-quickstart/druid/historical/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/historical:lib/*" io.druid.cli.Main server historical
java `cat conf-quickstart/druid/broker/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/broker:lib/*" io.druid.cli.Main server broker
java `cat conf-quickstart/druid/coordinator/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/coordinator:lib/*" io.druid.cli.Main server coordinator
java `cat conf-quickstart/druid/overlord/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/overlord:lib/*" io.druid.cli.Main server overlord
java `cat conf-quickstart/druid/middleManager/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/middleManager:lib/*" io.druid.cli.Main server middleManager
druid服務程序啟動後,可以在控制台看到相應的日志資訊。
我前一篇文章中提到過druid有幾種節點, 上面的啟動指令,對應的就是druid的各種節點
- historical 為Historical Nodes節點程序。主要用于查詢時從deepstroage 加載segments。
- broker 為Broker Nodes 節點程序。 主要為接收用戶端任務,任務分發,負載,以及結果合并等。
- coordinator 為 Coordinator Nodes 節點程序。 主要負責segments的管理和分發。
-
overlord 為 Overload Nodes 節點程序。
middleManager 為 MiddleManager Nodes 節點程序。 overload 和 middleManager是建立索引的主要服務程序, 具體會在接下來的章節中詳細介紹
如果想關閉服務,直接在控制台ctrl + c 就可以了。 如果你徹底清理掉之前的内容,重新開始,需要在關閉服務後,删除目錄下的var 檔案, 重新執行init腳本。
批量加載資料
服務啟動之後,我們就可以将資料load到druid中進行查詢了。在druid0.9.1.1的安裝包中,自帶了2015-09-12的wikiticker資料。我們可以用此資料來作為我們druid的學習執行個體。
首先我們看一下wikipedia的資料, 除了時間之外,包含的次元(dimensions)有:
- channel
- cityName
- comment
- countryIsoCode
- countryName
- isAnonymous
- isMinor
- isNew
- isRobot
- isUnpatrolled
- metroCode
- namespace
- page
- regionIsoCode
- regionName
- user
度量(measures) 我們可以設定如下:
- count
- added
- deleted
- delta
- user_unique
确定了度量,次元之後,接下來我們就可以導入資料了。首先,我們需要向druid送出一個注入資料的任務,并将目錄指向我們需要加載的資料檔案wikiticker-2015-09-12-sampled.json
Druid是通過post請求的方式送出任務的, 上面我們也講過,overload node 用于資料的加載,是以需要在overload節點上執行post請求, 目前單機環境,無需考慮這個。
在druid根目錄下執行
curl -X 'POST' -H 'Content-Type:application/json' -d @quickstart/wikiticker-index.json localhost:8090/druid/indexer/v1/task
其中
wikiticker-index.json 檔案指明了資料檔案的位置,類型,資料的schema(如度量,次元,時間,在druid中的資料源名稱等)等資訊, 之後我也會詳細的介紹,大家也可以從官網上查
當控制台列印如下資訊後,說明任務送出成功
{"task":"index_hadoop_wikipedia_2013-10-09T21:30:32.802Z"}
可以在overload控制台 http://localhost:8090/console.html來檢視任務的運作情況, 當狀态為“SUCCESS”時, 說明任務執行成功。
當資料注入成功後,historical node會加載這些已經注入到叢集的資料,友善查詢,這大概需要花費1-2分鐘的時間。 你可以在coordinator 控制台http://localhost:8081/#/來檢視資料的加載進度
當名為wikiticker的datasource 有個藍色的小圈,并顯示fully available時,說明資料已經可以了。可以執行查詢操作了。
加載流資料
為了實作流資料的加載,我們可以通過一個簡單http api來向druid推送資料,而tranquility就是一個不錯的資料生産元件
下載下傳并安裝tranquility
curl -O http://static.druid.io/tranquility/releases/tranquility-distribution-0.8.0.tgz
tar -xzf tranquility-distribution-0.8.0.tgz
cd tranquility-distribution-0.8.0
druid目錄中自帶了一個配置檔案
conf-quickstart/tranquility/server.json
啟動tranquility服務程序, 就可以向druid的 metrics datasource 推送實時資料。
bin/tranquility server -configFile <path_to_druid_distro>/conf-quickstart/tranquility/server.json
這一部分向大家介紹了如何通過tranquility服務來加載流資料, 其實druid還可以支援多種廣泛使用的流式架構, 包括Kafka, Storm, Samza, and Spark Streaming等
流資料加載中,次元是可變的,是以在schema定義的時候無需特别指明次元,而是将資料中任何一個字段都當做次元。而該datasource的度量則包含
- count
- value_sum (derived from
value
- value_min (derived from
value
- value_max (derived from
value
我們采用了一個腳本,來随機生成度量資料,導入到這個datasource中
執行完成後會傳回
{"result":{"received":25,"sent":25}}
這表明http server 從你這裡接收到了25條資料,并發送了這25條資料到druid。 在你第一次運作的時候,這個過程需要花一些時間,一段資料加載成功後,就可以查詢了。
Query data
接下來就是資料查詢了,我們可以采用如下幾種方式來查詢資料
Direct Druid queries 直接通過druid查詢
druid提供了基于json的富文本查詢方式。在提供的示例中,
quickstart/wikiticker-top-pages.json
是一個topN的查詢執行個體。
Visualizing data 資料可視化
druid是面向使用者分析應用的完美方案, 有很多開源的應用支援druid的資料可視化, 如pivot, caravel 和 metabase等
SQL and other query libraries 查詢元件
有許多查詢元件供我們使用,如sql引擎, 還有其他各種語言提供的元件,如python和ruby。 具體如下:
python: druid-io/pydruid
R: druid-io/RDruid
JavaScript: implydata/plywood
7eggs/node-druid-query
Clojure: y42/clj-druid
Ruby: ruby-druid/ruby-druid
redBorder/druid_config
SQL: Apache Calcite
implydata/plyql
PHP: pixelfederation/druid-php
本篇主要是講了單機環境下druid的搭建以及使用, 并使用druid安裝包自帶的例子給大家做了展示。 下一篇我講介紹在叢集環境下Druid如何安裝及使用。
Druid是一個為在大資料集之上做實時統計分析而設計的開源資料存儲。這個系統集合了一個面向列存儲的層,一個分布式、shared-nothing的架構,和一個進階的索引結構,來達成在秒級以内對十億行級别的表進行任意的探索分析。
特性
為分析而設計——Druid是為OLAP工作流的探索性分析而建構。它支援各種filter、aggregator和查詢類型,并為添加新功能提供了一個架構。使用者已經利用Druid的基礎設施開發了進階K查詢和直方圖功能。
互動式查詢——Druid的低延遲資料攝取架構允許事件在它們建立後毫秒内查詢,因為Druid的查詢延時通過隻讀取和掃描優必要的元素被優化。Aggregate和 filter沒有坐等結果。
高可用性——Druid是用來支援需要一直線上的SaaS的實作。你的資料在系統更新時依然可用、可查詢。規模的擴大和縮小不會造成資料丢失。
可伸縮——現有的Druid部署每天處理數十億事件和TB級資料。Druid被設計成PB級别。
使用場景:
第一:适用于清洗好的記錄實時錄入,但不需要更新操作
第二:支援寬表,不用join的方式(換句話說就是一張單表)
第三:可以總結出基礎的統計名額,可以用一個字段表示
第四:對時區和時間次元(year、month、week、day、hour等)要求高的(甚至到分鐘級别)
第五:實時性很重要
第六:對資料品質的敏感度不高
第七:用于定位效果分析和政策決策參考
2.安裝
安裝環境
本文使用Imply套件安裝,該套件提供了穩定的druid和web通路接口,在安裝之前需要先安裝node,
node下載下傳位址:https://nodejs.org/en/download/
imply下載下傳位址:http://imply.io/download
node安裝完成後使用下列指令檢查:
node --version
安裝過程
參考wiki:https://imply.io/docs/latest/quickstart
1.解壓Imply
tar -xzf imply-2.0.0.tar
2.啟動服務
nohup bin/supervise -c conf/supervise/quickstart.conf > test.log &
log日志記錄:
[Sun Apr 2 23:32:09 2017] Running command[zk], logging to[/Users/ball/Downloads/imply-2.0.0/var/sv/zk.log]: bin/run-zk conf-quickstart
[Sun Apr 2 23:32:09 2017] Running command[coordinator], logging to[/Users/ball/Downloads/imply-2.0.0/var/sv/coordinator.log]: bin/run-druid coordinator conf-quickstart
[Sun Apr 2 23:32:09 2017] Running command[broker], logging to[/Users/ball/Downloads/imply-2.0.0/var/sv/broker.log]: bin/run-druid broker conf-quickstart
[Sun Apr 2 23:32:09 2017] Running command[historical], logging to[/Users/ball/Downloads/imply-2.0.0/var/sv/historical.log]: bin/run-druid historical conf-quickstart
[Sun Apr 2 23:32:09 2017] Running command[overlord], logging to[/Users/ball/Downloads/imply-2.0.0/var/sv/overlord.log]: bin/run-druid overlord conf-quickstart
[Sun Apr 2 23:32:09 2017] Running command[middleManager], logging to[/Users/ball/Downloads/imply-2.0.0/var/sv/middleManager.log]: bin/run-druid middleManager conf-quickstart
[Sun Apr 2 23:32:09 2017] Running command[pivot], logging to[/Users/ball/Downloads/imply-2.0.0/var/sv/pivot.log]: bin/run-pivot-quickstart conf-quickstart
服務停止與啟動指令
./server --down 關閉
./server --restart ${服務名稱} 重新開機
3.資料導入
quickstart/wikiticker-2016-06-27-sampled.json 維奇百科網站日志資料
資料格式:
{"isRobot":true,"channel":"#pl.wikipedia","timestamp":"2016-06-27T00:00:58.599Z","flags":"NB","isUnpatrolled":false,"page":"Kategoria:Dyskusje nad usunięciem artykułu zakończone bez konsensusu − lipiec 2016","diffUrl":"https://pl.wikipedia.org/w/index.php?oldid=46204477&rcid=68522573","added":270,"comment":"utworzenie kategorii","commentLength":20,"isNew":true,"isMinor":false,"delta":270,"isAnonymous":false,"user":"Beau.bot","deltaBucket":200.0,"deleted":0,"namespace":"Kategoria"}
quickstart/wikiticker-index.json定義了任務的資料源,時間資訊,次元資訊,名額資訊,内容如下:
{
"type" : "index_hadoop",
"spec" : {
"ioConfig" : {
"type" : "hadoop",
"inputSpec" : {
"type" : "static",
"paths" : "quickstart/wikiticker-2016-06-27-sampled.json"
}
},
"dataSchema" : {
"dataSource" : "wikiticker",
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "day",
"queryGranularity" : "none",
"intervals" : ["2016-06-27/2016-06-28"]
},
"parser" : {
"type" : "hadoopyString",
"parseSpec" : {
"format" : "json",
"dimensionsSpec" : {
"dimensions" : [
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user",
"commentLength",
"deltaBucket",
"flags",
"diffUrl"
]
},
"timestampSpec" : {
"format" : "auto",
"column" : "timestamp"
}
}
},
"metricsSpec" : [
{
"name" : "count",
"type" : "count"
},
{
"name" : "added",
"type" : "longSum",
"fieldName" : "added"
},
{
"name" : "deleted",
"type" : "longSum",
"fieldName" : "deleted"
},
{
"name" : "delta",
"type" : "longSum",
"fieldName" : "delta"
},
{
"name" : "user_unique",
"type" : "hyperUnique",
"fieldName" : "user"
}
]
},
"tuningConfig" : {
"type" : "hadoop",
"partitionsSpec" : {
"type" : "hashed",
"targetPartitionSize" : 5000000
},
"jobProperties" : {}
}
}
}
使用離線導入:
./bin/post-index-task --file quickstart/wikiticker-index.json
Task started: index_hadoop_wikiticker_2017-04-02T15:44:23.464Z
Task log: http://localhost:8090/druid/indexer/v1/task/index_hadoop_wikiticker_2017-04-02T15:44:23.464Z/log
Task status: http://localhost:8090/druid/indexer/v1/task/index_hadoop_wikiticker_2017-04-02T15:44:23.464Z/status
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running...
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running...
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running...
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running...
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running...
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running...
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running...
Task index_hadoop_wikiticker_2017-04-02T15:44:23.464Z still running...
Task finished with status: SUCCESS
4.通路web位址
http://localhost:9095/,
檢視剛剛導入資料
5.使用查詢語句查詢
/quickstart/wikiticker-top-pages.json
{
"queryType" : "topN",
"dataSource" : "wikiticker",
"intervals" : ["2016-06-27/2016-06-28"],
"granularity" : "all",
"dimension" : "page",
"metric" : "edits",
"threshold" : 25,
"aggregations" : [
{
"type" : "longSum",
"name" : "edits",
"fieldName" : "count"
}
]
}
查詢語句:
curl -L -H'Content-Type: application/json' -XPOST --data-binary @quickstart/wikiticker-top-pages.json http://localhost:8082/druid/v2/
結果資料:
[{"timestamp":"2016-06-27T00:00:11.080Z","result":[{"page":"Copa América Centenario","edits":29},{"page":"User:Cyde/List of candidates for speedy deletion/Subpage","edits":16},{"page":"Wikipedia:Administrators' noticeboard/Incidents","edits":16},{"page":"2016 Wimbledon Championships – Men's Singles","edits":15},{"page":"Wikipedia:Administrator intervention against vandalism","edits":15},{"page":"Wikipedia:Vandalismusmeldung","edits":15},{"page":"The Winds of Winter (Game of Thrones)","edits":12},{"page":"ولاية الجزائر","edits":12},{"page":"Copa América","edits":10},{"page":"Lionel Messi","edits":10},{"page":"Wikipedia:Requests for page protection","edits":10},{"page":"Wikipedia:Usernames for administrator attention","edits":10},{"page":"Википедия:Опросы/Унификация шаблонов «Не переведено»","edits":10},{"page":"Bailando 2015","edits":9},{"page":"Bud Spencer","edits":9},{"page":"User:Osterb/sandbox","edits":9},{"page":"Wikipédia:Le Bistro/27 juin 2016","edits":9},{"page":"Ветра зимы (Игра престолов)","edits":9},{"page":"Användare:Lsjbot/Namnkonflikter-PRIVAT","edits":8},{"page":"Eurocopa 2016","edits":8},{"page":"Mistrzostwa Europy w Piłce Nożnej 2016","edits":8},{"page":"Usuario:Carmen González C/Science and technology in China","edits":8},{"page":"Wikipedia:Administrators' noticeboard","edits":8},{"page":"Wikipédia:Demande de suppression immédiate","edits":8},{"page":"World Deaf Championships","edits":8}]}]
---------------------
1、環境和架構
2、druid的安裝
3、druid的配置
4、overlord json
5、overlord csv
1、druid 環境和架構
環境資訊
Centos6.5
32GB 8C *5
Zookeeper 3.4.5
Druid 0.9.2
Hadoop-2.6.5
Jdk1.7
架構
10.20.23.42 Broker Real-time datanode NodeManager QuorumPeerMain
10.20.23.29 middleManager datanode NodeManager
10.20.23.38 overlord datanode NodeManager QuorumPeerMain
10.20.23.82 coordinator namenode ResourceManager
10.20.23.41 historical datanode NodeManager QuorumPeerMain
2、druid安裝
Hadoop的安裝就不介紹了,之前一直用Hadoop2.3.0安裝但是沒有成功,是以換成了2.6.5
和單機一樣的流程
1、 先解壓
2、 拷貝檔案
拷貝Hadoop的配置檔案到 ${DRUID_HOME}/conf/druid/_common目錄下面,拷貝4個core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml
3、 建立目錄,拷貝jar包
在${DRUID_HOME} /hadoop-dependencies/hadoop-client目錄下面建立一個2.6.5(建議選擇Hadoop的版本号)的檔案夾,将Hadoop的jar包拷貝到這個目錄下面
4、 修改配置檔案
注意:配置檔案特别繁瑣,隻要有一個地方配置錯誤任務就不能執行
#配置中繼資料資訊,修改成druid-hdfs-storage和mysql-metadata-storage
druid.extensions.loadList=["druid-hdfs-storage","mysql-metadata-storage"]
#配置zookeeper的資訊
druid.zk.service.host=10.20.23.82:2181
druid.zk.paths.base=/druid/cluster
#配置中繼資料MySQL的資訊
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://10.20.23.42:3306/druid
druid.metadata.storage.connector.user=root
druid.metadata.storage.connector.password=123456
# 配置存儲的資訊
# Deep storage
#
# For HDFS (make sure to include the HDFS extension and that your Hadoop config files in the cp):
druid.storage.type=hdfs
druid.storage.storageDirectory=/druid/segments
#配置日志存儲的資訊
# Indexing service logs
#
# For HDFS (make sure to include the HDFS extension and that your Hadoop config files in the cp):
druid.indexer.logs.type=hdfs
druid.indexer.logs.directory=/druid/indexing-logs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
broker的配置
broker的配置,主要配置根據實際情況修改記憶體配置設定的大小。添加druid.host參數和修改Duser.timezone的值,因為druid預設的時區是Z。是以我們需要加上+0800
[[email protected] broker]$ cat jvm.config
-server
-Xms1g
-Xmx1g
-XX:MaxDirectMemorySize=4096m
-Duser.timezone=UTC+0800
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
[[email protected] broker]$ cat runtime.properties
druid.host=10.20.23.82
druid.service=druid/broker
druid.port=8082
# HTTP server threads
druid.broker.http.numConnections=5
druid.server.http.numThreads=25
# Processing threads and buffers
druid.processing.buffer.sizeBytes=536870912
druid.processing.numThreads=7
# Query cache
druid.broker.cache.useCache=true
druid.broker.cache.populateCache=true
druid.cache.type=local
druid.cache.sizeInBytes=2000000000
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
coordinator的配置
coordinator的配置,主要配置根據實際情況修改記憶體配置設定的大小。添加druid.host參數和修改Duser.timezone的值,因為druid預設的時區是Z。是以我們需要加上+0800
[[email protected] coordinator]$ cat jvm.config
-server
-Xms1g
-Xmx1g
-Duser.timezone=UTC+0800
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
-Dderby.stream.error.file=var/druid/derby.log
[[email protected] coordinator]$ cat runtime.properties
druid.host=10.20.23.82
druid.service=druid/coordinator
druid.port=18091
druid.coordinator.startDelay=PT30S
druid.coordinator.period=PT30S
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
historical 的配置
historical的配置,主要配置根據實際情況修改記憶體配置設定的大小。添加druid.host參數和修改Duser.timezone的值,因為druid預設的時區是Z。是以我們需要加上+0800
[[email protected] historical]$ cat jvm.config
-server
-Xms1g
-Xmx1g
-XX:MaxDirectMemorySize=4960m
-Duser.timezone=UTC+0800
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
[[email protected] historical]$ cat runtime.properties
druid.host=10.20.23.82
druid.service=druid/historical
druid.port=8083
# HTTP server threads
druid.server.http.numThreads=25
# Processing threads and buffers
druid.processing.buffer.sizeBytes=536870912
druid.processing.numThreads=7
# Segment storage
druid.segmentCache.locations=[{"path":"var/druid/segment-cache","maxSize"\:130000000000}]
druid.server.maxSize=130000000000
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
middleManager 的配置
middleManager的配置,主要配置根據實際情況修改記憶體配置設定的大小。添加druid.host參數和修改Duser.timezone的值,因為druid預設的時區是Z。是以我們需要加上+0800
其中hadoop-client:2.6.5 這個2.6.5是和第3點中建立的路徑名字是一樣的,
[[email protected] middleManager]$ cat jvm.config
-server
-Xms64m
-Xmx64m
-Duser.timezone=UTC+0800
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
[[email protected] middleManager]$ cat runtime.properties
druid.service=druid/middleManager
druid.port=8091
# Number of tasks per middleManager
druid.worker.capacity=3
# Task launch parameters
druid.indexer.runner.javaOpts=-server -Xmx2g -Duser.timezone=UTC+0800 -Dfile.encoding=UTF-8 -Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
druid.indexer.task.baseTaskDir=var/druid/task
# HTTP server threads
druid.server.http.numThreads=25
# Processing threads and buffers
druid.processing.buffer.sizeBytes=536870912
druid.processing.numThreads=2
# Hadoop indexing
druid.host=10.20.23.82
druid.indexer.task.hadoopWorkingPath=/druid/hadoop-tmp
druid.indexer.task.defaultHadoopCoordinates=["org.apache.hadoop:hadoop-client:2.6.5"]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
overlord 的配置
overlord的配置,主要配置根據實際情況修改記憶體配置設定的大小。添加druid.host參數和修改Duser.timezone的值,因為druid預設的時區是Z。是以我們需要加上+0800
[[email protected] overlord]$ cat jvm.config
-server
-Xms1g
-Xmx1g
-Duser.timezone=UTC+0800
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
[[email protected] overlord]$ cat runtime.properties
druid.host=10.20.23.82
druid.service=druid/overlord
druid.port=8090
druid.indexer.queue.startDelay=PT30S
druid.indexer.runner.type=remote
druid.indexer.storage.type=metadata
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
5、 在 通過scp拷貝到其他的機器上面去
6、 在對應機器啟動各個程序
java `cat conf/druid/historical/jvm.config | xargs` -cp "conf/druid/_common:conf/druid/historical:lib/*" io.druid.cli.Main server historical
java `cat conf/druid/broker/jvm.config | xargs` -cp "conf/druid/_common:conf/druid/broker:lib/*" io.druid.cli.Main server broker
java `cat conf/druid/coordinator/jvm.config | xargs` -cp "conf/druid/_common:conf/druid/coordinator:lib/*" io.druid.cli.Main server coordinator
java `cat conf/druid/overlord/jvm.config | xargs` -cp "conf/druid/_common:conf/druid/overlord:lib/*" io.druid.cli.Main server overlord
java `cat conf/druid/middleManager/jvm.config | xargs` -cp "conf/druid/_common:conf/druid/middleManager:lib/*" io.druid.cli.Main server middleManager
1
2
3
4
5
6
7
8
9
可以通過下面2個URL檢視到對應的頁面
http://10.20.23.82:18091/#/
http://10.20.23.82:8090/console.html
---------------------
http://lxw1234.com/archives/2015/11/554.htm 海量資料實時OLAP分析系統-Druid.io安裝配置和體驗
http://druid.io/docs/0.9.2/design/design.html Druid官網搭建
Druid.io 部署&使用文檔
1.叢集模式下部署
Prerequisites : Java 7 or higher & Zookeeper & mysql
下載下傳Druid.io :
curl -O http://static.druid.io/artifacts/releases/druid-0.9.1.1-bin.tar.gz
tar -xzf druid-0.9.1.1-bin.tar.gz
cd druid-0.9.1.1
1
2
3
檔案夾目錄結構 :
LICENSE - the license files.
bin/ - scripts related to the single-machine quickstart.
conf/* - template configurations for a clustered setup.
conf-quickstart/* - configurations for the single-machine quickstart.
extensions/* - all Druid extensions.
hadoop-dependencies/* - Druid Hadoop dependencies.
lib/* - all included software packages for core Druid.
quickstart/* - files related to the single-machine quickstart.
所有配置檔案均在 conf/* 目錄下.
配飾HDFS為Druid.io的deep storage & 配置zk & 配置mysql
修改 conf/druid/_common/common.runtime.properties 檔案.
#
# Extensions
#
# This is not the full list of Druid extensions, but common ones that people often use. You may need to change this list
# based on your particular setup.
#使用 "mysql-metadata-storage" 作為metadata的存儲
#使用 "druid-hdfs-storage" 作為 deep storage
#使用 "druid-parquet-extensions" 向druid中插入parquet資料
druid.extensions.loadList=["druid-kafka-eight", "druid-histogram", "druid-datasketches", "mysql-metadata-storage", "druid-hdfs-storage", "druid-avro-extensions", "druid-parquet-extensions"]
# If you have a different version of Hadoop, place your Hadoop client jar files in your hadoop-dependencies directory
# and uncomment the line below to point to your directory.
#druid.extensions.hadoopDependenciesDir=/my/dir/hadoop-dependencies
#
# Logging
#
# Log all runtime properties on startup. Disable to avoid logging properties on startup:
druid.startup.logging.logProperties=true
#
# Zookeeper
#
druid.zk.service.host=tagtic-slave01:2181,tagtic-slave02:2181,tagtic-slave03:2181
druid.zk.paths.base=/druid
#
# Metadata storage
#
# For MySQL:
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://tagtic-master:3306/druid
druid.metadata.storage.connector.user=root
druid.metadata.storage.connector.password=123456
#
# Deep storage
#
# For HDFS (make sure to include the HDFS extension and that your Hadoop config files in the cp):
druid.storage.type=hdfs
druid.storage.storageDirectory=/druid/segments
#
# Indexing service logs
#
# For HDFS (make sure to include the HDFS extension and that your Hadoop config files in the cp):
druid.indexer.logs.type=hdfs
druid.indexer.logs.directory=/druid/indexing-logs
#
# Service discovery
#
druid.selectors.indexing.serviceName=druid/overlord
druid.selectors.coordinator.serviceName=druid/coordinator
#
# Monitoring
#
druid.monitoring.monitors=["com.metamx.metrics.JvmMonitor"]
druid.emitter=logging
druid.emitter.logging.logLevel=info
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
将 Hadoop 的配置檔案(core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml) cp 到 conf/druid/_common 目錄下
修改 conf/druid/middleManager/runtime.properties 檔案.
druid.service=druid/middleManager
druid.port=18091
# Number of tasks per middleManager
druid.worker.capacity=3
# Task launch parameters
# **CDH版本添加 -Dhadoop.mapreduce.job.classloader=true 來解決hadoop indexer導入時jar包沖突問題**
druid.indexer.runner.javaOpts=-server -Xmx2g -Duser.timezone=UTC -Dfile.encoding=UTF-8 -Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager -Dhadoop.mapreduce.job.classloader=true
druid.indexer.task.baseTaskDir=var/druid/task
# HTTP server threads
druid.server.http.numThreads=25
# Processing threads and buffers
druid.processing.buffer.sizeBytes=536870912
druid.processing.numThreads=2
# Hadoop indexing
druid.indexer.task.hadoopWorkingPath=/tmp/druid-indexing
druid.indexer.task.defaultHadoopCoordinates=["org.apache.hadoop:hadoop-client:2.6.0"]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Hadoop叢集版本必須和Druid.io中版本同一,可以通過pull-deps下載下傳相同hadoop-dependencies版本,e.g. :
java -classpath "lib/*" io.druid.cli.Main tools pull-deps --defaultVersion 0.9.1.1 -c io.druid.extensions:mysql-metadata-storage:0.9.1.1 -c druid-hdfs-storage -h org.apache.hadoop:hadoop-client:2.6.0
項目中Druid.io配置端口号:
druid.service=druid/coordinator druid.port=18081
druid.service=druid/broker druid.port=18082
druid.service=druid/historical druid.port=18083
druid.service=druid/overlord druid.port=18090
druid.service=druid/middleManager druid.port=18091
2.啟動Druid.io
java `cat conf/druid/coordinator/jvm.config | xargs` -cp conf/druid/_common:conf/druid/coordinator:lib/* io.druid.cli.Main server coordinator &>> logs/coordinator.log &
java `cat conf/druid/overlord/jvm.config | xargs` -cp conf/druid/_common:conf/druid/overlord:lib/* io.druid.cli.Main server overlord &>> logs/overlord.log &
java `cat conf/druid/historical/jvm.config | xargs` -cp conf/druid/_common:conf/druid/historical:lib/* io.druid.cli.Main server historical &>> logs/historical.log &
java `cat conf/druid/middleManager/jvm.config | xargs` -cp conf/druid/_common:conf/druid/middleManager:lib/* io.druid.cli.Main server middleManager &>> logs/middleManager.log &
java `cat conf/druid/broker/jvm.config | xargs` -cp conf/druid/_common:conf/druid/broker:lib/* io.druid.cli.Main server broker &>> logs/broker.log &
1
2
3
4
5
6
7
8
9
3.從HDFS導入資料到Druid.io
批量導入Batch Data Ingestion
導入Parquet檔案
Druid作業檢視 Coordinator : http://tagtic-master:18090/console.html
Druid叢集檢視Cluster : http://tagtic-master:18081/#/
解決傳入資料時區問題 Hadoop Configuration,在conf/druid/_common/mapred-site.xml中添加
<property>
<name>mapreduce.map.java.opts</name>
<value>-server -Xmx1536m -Duser.timezone=UTC -Dfile.encoding=UTF-8 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-server -Xmx2560m -Duser.timezone=UTC -Dfile.encoding=UTF-8 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps</value>
</property>
1
2
3
4
5
6
7
8
---------------------
Imply提供了一套完整的部署方式,包括依賴庫,Druid,圖形化的資料展示頁面,SQL查詢元件等。本文将基于Imply套件進行說明
單機部署
依賴
Java 8 or better
Node.js 4.5.x or better
Linux, Mac OS X, or other Unix-like OS (Windows is not supported)
At least 4GB of RAM
下載下傳與安裝
從https://imply.io/get-started 下載下傳最新版本安裝包
tar -xzf imply-2.3.9.tar.gz
cd imply-2.3.9
目錄說明如下:
- bin/ - run scripts for included software.
- conf/ - template configurations for a clustered setup.
- conf-quickstart/* - configurations for the single-machine quickstart.
- dist/ - all included software.
- quickstart/ - files related to the single-machine quickstart.
啟動服務
bin/supervise -c conf/supervise/quickstart.conf
1
2
安裝驗證
導入測試資料
安裝包中包含一些測試的資料,可以通過執行預先定義好的資料說明檔案進行導入
bin/post-index-task --file quickstart/wikiticker-index.json
1
可視化控制台
overlord 控制頁面:http://localhost:8090/console.html.
druid叢集頁面:http://localhost:8081
資料可視化頁面:http://localhost:9095
資料展示與查詢
資料展示:對管道進行統計的柱狀圖
SQL資料查詢:使用sql查詢編輯次數最多的10個page
HTTP POST資料查詢
指令:curl -L -H’Content-Type: application/json’ -XPOST –data-binary @quickstart/wikiticker-top-pages.json http://localhost:8082/druid/v2?pretty
結果:
[ {
"timestamp" : "2016-06-27T00:00:11.080Z",
"result" : [ {
"edits" : 29,
"page" : "Copa América Centenario"
}, {
"edits" : 16,
"page" : "User:Cyde/List of candidates for speedy deletion/Subpage"
},
..........
{
"edits" : 8,
"page" : "World Deaf Championships"
} ]
} ]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
叢集部署
叢集配置的規劃需要根據需求來定制,下面以一個開發環境機器搭建為例,描述如何搭建一個有HA特性的Druid叢集.
叢集部署有以下幾點需要說明
1. 為了保證HA,主節點部署兩台
2. 管理節點與查詢節點可以考慮多核大記憶體的機器
部署規劃
角色 機器 配置 叢集角色
主節點 10.5.24.137 8C16G Coordinator,Overlord
主節點 10.5.24.138 8C16G Coordinator,Overlord
資料節點,查詢節點 10.5.24.139 8C16G Historical, MiddleManager, Tranquility,Broker,Pivot Web
資料節點,查詢節點 10.5.24.140 8C16G Historical, MiddleManager, Tranquility,(資料節點,查詢節點)Broker
部署步驟
公共配置
編輯conf/druid/_common/common.runtime.properties 檔案内容
1. loadList配置:==此處需要統一在一個位置統一定義,否則會出現extension加載的問題==
druid.extensions.loadList=["mysql-metadata-storage","druid-hdfs-storage"]
1
Zookeeper
#
# Zookeeper
#
druid.zk.service.host=native-lufanfeng-2-5-24-138:2181,native-lufanfeng-3-5-24-139:2181,native-lufanfeng-4-5-24-140:2181
druid.zk.paths.base=/druid
1
2
3
4
5
6
7
MetaData:使用Mysql
# For MySQL:
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://10.5.24.151:3306/druid
druid.metadata.storage.connector.user=root
druid.metadata.storage.connector.password=123456
1
2
3
4
5
6
Deepstorage:使用HDFS
#druid.storage.type=local
#druid.storage.storageDirectory=var/druid/segments
druid.storage.type=hdfs
druid.storage.storageDirectory=hdfs://10.5.24.137:9000/druid/segments
#druid.indexer.logs.type=file
#druid.indexer.logs.directory=var/druid/indexing-logs
druid.indexer.logs.type=hdfs
druid.indexer.logs.directory=hdfs://10.5.24.137:9000/druid/indexing-logs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
主節點配置
建立配置檔案:cp conf/supervise/master-no-zk.conf conf/supervise/master.conf
編輯master.conf 内容如下:
:verify bin/verify-java
:verify bin/verify-version-check
coordinator bin/run-druid coordinator conf
!p80 overlord bin/run-druid overlord conf
1
2
3
4
5
6
目前的版本中,mysql-metadata-storage沒有包含在預設的安裝包中,如果使用mysql存儲中繼資料,需要單獨安裝下對應的擴充,是用下列指令在兩個master節點上對需要用到的擴充進行安裝:
[email protected]:~/imply-2.3.8# java -classpath "dist/druid/lib/*" -Ddruid.extensions.directory="dist/druid/extensions" io.druid.cli.Main tools pull-deps -c io.druid.extensions:mysql-metadata-storage:0.10.1 -c io.druid.extensions.contrib:druid-rabbitmq:0.10.1 -h org.apache.hadoop:hadoop-client:2.7.0
1
==預設mysql-metadata-storage帶的mysql驅動是針對Mysql 5.1的,如果使用Mysql的版本是5.5 或是其他版本,可能會出現”Communications link failure”的錯誤,此時需要更新Mysql的驅動。==
在10.5.24.137/138上啟動master相關服務:nohup bin/supervise -c conf/supervise/master.conf > master.log &
資料節點與查詢節點配置
安裝NodeJS:apt-get install nodejs
建立配置檔案:vim conf/supervise/data-with-query.conf
編輯data-with-query.conf 内容如下:
:verify bin/verify-java
:verify bin/verify-node
:verify bin/verify-version-check
broker bin/run-druid broker conf
imply-ui bin/run-imply-ui conf
historical bin/run-druid historical conf
middleManager bin/run-druid middleManager conf
# Uncomment to use Tranquility Server
#!p95 tranquility-server bin/tranquility server -configFile conf/tranquility/server.json
# Uncomment to use Tranquility Kafka
#!p95 tranquility-kafka bin/tranquility kafka -configFile conf/tranquility/kafka.json
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
對于叢集模式,pivot的配置檔案必須調整為mysql,sqllite會導緻無法檢視datasource,修改conf/pivot/config.xml檔案
settingsLocation:
location: mysql
uri: 'mysql://root:[email protected]:3306/druid'
table: 'pivot_state'
initialSettings:
clusters:
- name: druid
type: druid
host: localhost:8082
1
2
3
4
5
6
7
8
9
10
在10.5.24.139/140兩台機器上分别執行:nohup bin/supervise -c conf/supervise/data-with-query.conf > data-with-query.log &
驗證
可視化控制台
overlord 控制頁面:http://10.5.24.138:8090/console.html.
druid叢集頁面:http://10.5.24.138:8081
資料可視化頁面:http://10.5.24.139:9095
---------------------
下載下傳:
http://druid.io/downloads.html
A version may be declared as a release candidate if it has been deployed to a sizable production cluster. Release candidates are declared as stable after we feel fairly confident there are no major bugs in the version. Check out the Versioning section for how we describe releases.
The current stable is tagged at version 0.10.0.
Druid: druid-0.10.0-bin.tar.gz.
MySQL metadata store extension: mysql-metadata-storage-0.10.0.tar.gz. (Due to licensing, we've separated MySQL metadata store extension from main Druid release. If you would like to use it, please untar this tarball and follow the steps in Include Extensions)
Tranquility: tranquility-distribution-0.8.2.tgz.
安裝
http://druid.io/docs/0.10.0/tutorials/cluster.html
Select hardware
TheCoordinator and Overlord processes can be co-located on a single server that is responsible for handling the metadata and coordination needs of your cluster(進行中繼資料以及叢集之間的協調). The equivalent of an AWS m3.xlarge is sufficient for most clusters. This hardware offers:
4 vCPUs
15 GB RAM
80 GB SSD storage
Historicalsand MiddleManagers can be colocated on a single server to handle the actual data in your cluster. These servers benefit greatly from CPU, RAM, and SSDs. The equivalent of an AWS r3.2xlarge is a good starting point. This hardware offers:
8 vCPUs
61 GB RAM
160 GB SSD storage
DruidBrokers accept queries and farm them out to the rest of the cluster. They also optionally maintain an in-memory query cache. These servers benefit greatly from CPU and RAM, and can also be deployed on the equivalent of an AWS r3.2xlarge. This hardware offers:
8 vCPUs
61 GB RAM
160 GB SSD storage
You can consider co-locating any open source UIs or query libraries on the same server that the Broker is running on.
Very large clusters should consider selecting larger servers.
Select OS
We recommend running your favorite Linux distribution. You will also need:
Java 8 or better
Download the distribution
First, download and unpack the release archive. It's best to do this on a single machine at first, since you will be editing the configurations and then copying the modified distribution out to all of your servers.
curl -O http://static.druid.io/artifacts/releases/druid-0.10.0-bin.tar.gztar -xzf druid-0.10.0-bin.tar.gzcd druid-0.10.0
步驟一:Configure deep storage
Druid relies on a distributed filesystem or large object (blob) store for data storage. The most commonly used deep storage implementations are S3 (popular for those on AWS) and HDFS (popular if you already have a Hadoop deployment).
S3 (略)
HDFS(我們使用)
手動替換所依賴的Hadoop的Jar包:
cd $DRUID_HOME
find -name "*hadoop*"
因為我們使用的Hadoop的版本是2.7.0。是以需要将Druid自帶的Hadoop的jar包更新到2.7.0,替換2.3.0的jar包。
注意:extensions/druid-hdfs-storage/中預設有guava-16.0.1.jar,而不是Hadoop依賴的guava-11.0.2.jar。這個是沒問題的。
将本地的Hadoop的依賴複制到DRUID下。hadoop-client沒有,網上下載下傳。
cd $DRUID_HOME/extensions/druid-hdfs-storage
wgethttp://central.maven.org/maven2/org/apache/hadoop/hadoop-client/2.7.0/hadoop-client-2.7.0.jar
cp $HADOOP_HOME/share/hadoop/tools/lib/hadoop-auth-2.7.0.jar $DRUID_HOME/extensions/druid-hdfs-storage
cp $HADOOP_HOME/share/hadoop/common/hadoop-common-2.7.0.jar $DRUID_HOME/extensions/druid-hdfs-storage
cp $HADOOP_HOME/share/hadoop/hdfs/hadoop-hdfs-2.7.0.jar $DRUID_HOME/extensions/druid-hdfs-storage
cp $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.0.jar $DRUID_HOME/extensions/druid-hdfs-storage
cp $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.0.jar $DRUID_HOME/extensions/druid-hdfs-storage
cp $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.0.jar $DRUID_HOME/extensions/druid-hdfs-storage
cp $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.0.jar $DRUID_HOME/extensions/druid-hdfs-storage
cp $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-api-2.7.0.jar $DRUID_HOME/extensions/druid-hdfs-storage
cp $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-client-2.7.0.jar $DRUID_HOME/extensions/druid-hdfs-storage
cp $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-common-2.7.0.jar $DRUID_HOME/extensions/druid-hdfs-storage
cp $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-server-common-2.7.0.jar $DRUID_HOME/extensions/druid-hdfs-storage
cp $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.0.jar $DRUID_HOME/extensions/druid-hdfs-storage
cp $HADOOP_HOME/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar $DRUID_HOME/extensions/druid-hdfs-storage
mkdir $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
cd $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
wgethttp://central.maven.org/maven2/org/apache/hadoop/hadoop-client/2.7.0/hadoop-client-2.7.0.jar
cp $HADOOP_HOME/share/hadoop/hdfs/hadoop-hdfs-2.7.0.jar $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
cp $HADOOP_HOME/share/hadoop/common/hadoop-common-2.7.0.jar $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
cp $HADOOP_HOME/share/hadoop/common/lib/hadoop-auth-2.7.0.jar $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
cp $HADOOP_HOME/share/hadoop/common/lib/hadoop-annotations-2.7.0.jar $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
cp $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.0.jar $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
cp $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.0.jar $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
cp $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.0.jar $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
cp $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.0.jar $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
cp $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.0.jar $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
cp $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-server-common-2.7.0.jar $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
cp $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-common-2.7.0.jar $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
cp $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-client-2.7.0.jar $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
cp $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-api-2.7.0.jar $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
cp $HADOOP_HOME/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar $DRUID_HOME/hadoop-dependencies/hadoop-client/2.7.0
配置common.runtime.properties
配置 conf/druid/_common/common.runtime.properties檔案。修改以下内容:
1)設定druid.extensions.hadoopDependenciesDir=/hadoop/haozhuo/druid/druid-0.10.0/hadoop-dependencies
(注意這裡不帶hadoop-client/2.7.0)
并且
在conf/druid/middleManager/runtime.properties修改druid.indexer.task.defaultHadoopCoordinates=["org.apache.hadoop:hadoop-client:2.7.0"]
這樣運作時,會自動找到/hadoop/haozhuo/druid/druid-0.10.0/hadoop-dependencies/hadoop-client/2.7.0這個路徑
或者另一種寫法是:
設定druid.extensions.hadoopDependenciesDir=/hadoop/haozhuo/druid/druid-0.10.0/hadoop-dependencies/hadoop-client/2.7.0
設定druid.indexer.task.defaultHadoopCoordinates=[]
這兩種方式都是可以的,任選其一
2)将druid.extensions.loadList=["druid-s3-extensions"]修改成
druid.extensions.loadList=["druid-hdfs-storage"].
3) 注釋掉:
#druid.storage.type=local#druid.storage.storageDirectory=var/druid/segments解除注釋:druid.storage.type=hdfsdruid.storage.storageDirectory=/druid/segments
4)注釋掉:
#druid.indexer.logs.type=file#druid.indexer.logs.directory=var/druid/indexing-logs解除注釋:druid.indexer.logs.type=hdfsdruid.indexer.logs.directory=/druid/indexing-logs
5)将Hadoop配置檔案:core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml複制到 conf/druid/_common/目錄下
步驟二:Configure addresses for Druid coordination
還是修改conf/druid/_common/common.runtime.properties這個檔案:
1)設定ZooKeeper的位址:
druid.zk.service.host=192.168.1.150:2181
2)修改metadata store的配置。我這裡使用mysql作為metadata store。注釋掉derby的配置。然後使用mysql相關配置
#druid.metadata.storage.type=derby
#druid.metadata.storage.connector.connectURI=jdbc:derby://metadata.store.ip:1527/var/druid/metadata.db;create=true
#druid.metadata.storage.connector.host=metadata.store.ip
#druid.metadata.storage.connector.port=1527
# For MySQL:
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://192.168.1.162:3306/druid
druid.metadata.storage.connector.user=datag
druid.metadata.storage.connector.password=yjkdatag
3)從http://druid.io/downloads.html中下載下傳mysql-metadata-storage-0.10.0.tar.gz ,然後解壓到$DRUID_HOME/extensions目錄下:
步驟三:Configure Tranquility Server (optional)需要配置
Data streams can be sent to Druid through a simple HTTP API powered by Tranquility Server. If you will be using this functionality, then at this point you should configure Tranquility Server.
http://druid.io/docs/0.10.0/ingestion/stream-ingestion.html#server
Loading streams
Streams can be ingested in Druid using either Tranquility (a Druid-aware client) and the indexing service or through standalone Realtime nodes. The first approach will be more complex to set up, but also offers scalability and high availability characteristics that advanced production setups may require. The second approach has some known limitations.
(使用 Tranquility這種方式攝入資料的特點是:部署起來更加複雜,但是提供高可用和可擴充的特點。适用于生産環境)
Stream push
If you have a program that generates a stream, then you can push that stream directly into Druid in real-time. With this approach, Tranquility is embedded in your data-producing application. Tranquility comes with bindings for the Storm and Samza stream processors.It also has a direct API that can be used from any JVM-based program, such as Spark Streaming or a Kafka consumer.
Tranquility handles partitioning, replication, service discovery, and schema rollover for you, seamlessly and without downtime. You only have to define your Druid schema.
For examples and more information, please see the Tranquility README.
Spark Streaming往Druid發送資料:
https://github.com/druid-io/tranquility/blob/master/docs/spark.md
有Spark2.10的包
https://mvnrepository.com/artifact/io.druid/tranquility-spark_2.10/0.7.2
Stream pull
If you have an external service that you want to pull data from, you have two options. The simplest option is to set up a "copying" service that reads from the data source and writes to Druid using the stream push method.
Another option is stream pull. With this approach, a Druid Realtime Node ingests data from a Firehose connected to the data you want to read. Druid includes builtin firehoses for Kafka, RabbitMQ, and various other streaming systems.
More information
For more information on loading streaming data via a push based approach, please see here.
For more information on loading streaming data via a pull based approach, please see here.
步驟四:Configure Tranquility Kafka (optional ) 暫時不配
Druid can consuming streams from Kafka through Tranquility Kafka. If you will be using this functionality, then at this point you should configure Tranquility Kafka.
步驟五:Configure for connecting to Hadoop(optional)配置
如果想要從Hadoop加載資料,那麼就需要配置。注意,這裡從HDFS加載資料與用HDFS作為deep storage是不同的概念。
1)修改$DRUID_HOME/conf/druid/middleManager/runtime.properties
druid.service=druid/middleManager
druid.port=8091
# Number of tasks per middleManager
druid.worker.capacity=3
# Task launch parameters
druid.indexer.runner.javaOpts=-server -Xmx2g -Duser.timezone=UTC+08:00 -Dfile.encoding=UTF-8 -Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
druid.indexer.task.baseTaskDir=/hadoop/haozhuo/druid/var/task
# HTTP server threads
druid.server.http.numThreads=20
# Processing threads and buffers
# druid.processing.buffer.sizeBytes=536870912
druid.processing.buffer.sizeBytes=268435456
druid.processing.numThreads=2
# Hadoop indexing 是HDFS中的路徑
druid.indexer.task.hadoopWorkingPath=/druid/tmp/druid-indexing
# 具體根據之前設定的druid.extensions.hadoopDependenciesDir而定。
# 也可能是 druid.indexer.task.defaultHadoopCoordinates=[]
druid.indexer.task.defaultHadoopCoordinates=["org.apache.hadoop:hadoop-client:2.7.0"]
3)将Hadoop配置檔案:core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml複制到conf/druid/_common/下。(這步驟在步驟1時已經做了)
4)最最重要的一步,也是官網中沒有。在從Hadoop導入資料到DRUID時出現了問題,折磨了我好長時間才解決的:
解決guice沖突問題:
DRUID依賴的谷歌的guice的版本是:
./lib/jersey-guice-1.19.jar
./lib/guice-multibindings-4.1.0.jar
./lib/guice-servlet-4.1.0.jar
./lib/guice-4.1.0.jar
而Hadoop依賴的guice版本是
./share/hadoop/yarn/lib/guice-servlet-3.0.jar
./share/hadoop/yarn/lib/guice-3.0.jar
./share/hadoop/yarn/lib/jersey-guice-1.9.jar
./share/hadoop/mapreduce/lib/guice-servlet-3.0.jar
./share/hadoop/mapreduce/lib/guice-3.0.jar
./share/hadoop/mapreduce/lib/jersey-guice-1.9.jar
這樣會導緻Druid送出job到Hadoop執行MapReduce時會報以下錯誤:
java.lang.NoSuchMethodError: com.google.inject.util.Types.collectionOf(Ljava/lang/reflect/Type;)Ljava/lang/reflect/ParameterizedType;
at com.google.inject.multibindings.Multibinder.collectionOfProvidersOf(Multibinder.java:202)
at com.google.inject.multibindings.Multibinder$RealMultibinder.<init>(Multibinder.java:283)
at com.google.inject.multibindings.Multibinder$RealMultibinder.<init>(Multibinder.java:258)
at com.google.inject.multibindings.Multibinder.newRealSetBinder(Multibinder.java:178)
at com.google.inject.multibindings.Multibinder.newSetBinder(Multibinder.java:150)
at io.druid.guice.LifecycleModule.getEagerBinder(LifecycleModule.java:131)
at io.druid.guice.LifecycleModule.configure(LifecycleModule.java:137)
at com.google.inject.spi.Elements$RecordingBinder.install(Elements.java:223)
at com.google.inject.spi.Elements.getElements(Elements.java:101)
at com.google.inject.spi.Elements.getElements(Elements.java:92)
我的解決方法是:
cp $DRUID_HOME/lib/*guice* $HADOOP_HOME/share/hadoop/yarn/lib/
cp $DRUID_HOME/lib/*guice* $HADOOP_HOME/share/hadoop/mapreduce/lib/
這樣,Hadoop中的guice的版本就有:
./share/hadoop/yarn/lib/jersey-guice-1.19.jar
./share/hadoop/yarn/lib/jersey-guice-1.9.jar
./share/hadoop/yarn/lib/guice-multibindings-4.1.0.jar
./share/hadoop/yarn/lib/guice-3.0.jar
./share/hadoop/yarn/lib/guice-servlet-4.1.0.jar
./share/hadoop/yarn/lib/guice-4.1.0.jar
./share/hadoop/yarn/lib/guice-servlet-3.0.jar
./share/hadoop/mapreduce/lib/jersey-guice-1.19.jar
./share/hadoop/mapreduce/lib/jersey-guice-1.9.jar
./share/hadoop/mapreduce/lib/guice-multibindings-4.1.0.jar
./share/hadoop/mapreduce/lib/guice-3.0.jar
./share/hadoop/mapreduce/lib/guice-servlet-4.1.0.jar
./share/hadoop/mapreduce/lib/guice-4.1.0.jar
./share/hadoop/mapreduce/lib/guice-servlet-3.0.jar
Hadoop中有了guice-4.1.0的版本後執行Druid任務就不會報錯了。
解決guava沖突問題:
出現以下問題:
2017-07-19 22:39:43,122 ERROR [main] org.apache.hadoop.mapred.YarnChild: Error running child : java.lang.NoSuchMethodError: com.google.common.base.Enums.getIfPresent(Ljava/lang/Class;Ljava/lang/String;)Lcom/google/common/base/Optional;
原因跟上面一樣,Druid需要guava-16.0.1.jar,而Hadoop中隻有guava-11.0.2.jar。将Druid中的guava-16.0.1.jar複制到Hadoop中。
cp $DRUID_HOME/lib/guava-16.0.1.jar $HADOOP_HOME/share/hadoop/yarn/lib/
cp $DRUID_HOME/lib/guava-16.0.1.jar $HADOOP_HOME/share/hadoop/common/lib/
cp $DRUID_HOME/lib/guava-16.0.1.jar $HADOOP_HOME/share/hadoop/hdfs/lib/
結果如下:
./share/hadoop/tools/lib/guava-11.0.2.jar
./share/hadoop/common/lib/guava-16.0.1.jar
./share/hadoop/common/lib/guava-11.0.2.jar
./share/hadoop/kms/tomcat/webapps/kms/WEB-INF/lib/guava-11.0.2.jar
./share/hadoop/httpfs/tomcat/webapps/webhdfs/WEB-INF/lib/guava-11.0.2.jar
./share/hadoop/yarn/lib/guava-16.0.1.jar
./share/hadoop/yarn/lib/guava-11.0.2.jar
./share/hadoop/hdfs/lib/guava-16.0.1.jar
./share/hadoop/hdfs/lib/guava-11.0.2.jar
步驟六:Tune Druid Coordinator and Overlord
注意:設定時區,其他配置檔案中都要修改!
由于Druid是時間序列資料庫,是以對時間非常敏感。Druid底層采用絕對毫秒數存儲時間,如果不指定時區,預設輸出為零時區時間,即ISO8601中yyyy-MM-ddThh:mm:ss.SSSZ。我們生産環境中采用東八區,也就是Asia/Hong Kong時區,是以需要将叢集所有UTC時間調整為UTC+08:00;同時導入的資料的timestamp列格式必須為:yyyy-MM-ddThh:mm:ss.SSS+08:00
如果不設定,Hadoop batch ingestion會失敗,出現“No buckets?? seems there is no data to index.”的錯誤
配置Coordinator:
cd $DRUID_HOME/conf/druid/coordinator
vi jvm.config
-server
-Xms3g
-Xmx3g
-Duser.timezone=UTC+08:00
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=/hadoop/haozhuo/druid/var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
-Dderby.stream.error.file=/hadoop/haozhuo/druid/var/derby.log(這個配置感覺并沒啥卵用。用的是mysql作為中繼資料庫)
vi runtime.properties(并沒做什麼修改,都是預設值)
druid.service=druid/coordinator
druid.port=8081
druid.coordinator.startDelay=PT30S
druid.coordinator.period=PT30S
配置Overlord:
cd $DRUID_HOME/conf/druid/overlord
vi jvm.config
-server
-Xms3g
-Xmx3g
-Duser.timezone=UTC+08:00
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=/hadoop/haozhuo/druid/var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
vi runtime.properties(并沒做什麼修改,都是預設值)
druid.service=druid/overlord
druid.port=8090
druid.indexer.queue.startDelay=PT30S
druid.indexer.runner.type=remote
druid.indexer.storage.type=metadata
步驟七:Tune Druid processes that serve queries
Druid Historicals andMiddleManagers can be co-located on the same hardware. Both Druid processes benefit greatly from being tuned to the hardware they run on. If you are running Tranquility Server or Kafka, you can also colocate Tranquility with these two Druid processes. If you are using r3.2xlarge EC2 instances, or similar hardware, the configuration in the distribution is a reasonable starting point.
If you are using different hardware, we recommend adjusting configurations for your specific hardware. The most commonly adjusted configurations are:
-Xmx and -Xms
druid.server.http.numThreads
druid.processing.buffer.sizeBytes
druid.processing.numThreads
druid.query.groupBy.maxIntermediateRows
druid.query.groupBy.maxResults
druid.server.maxSize and druid.segmentCache.locations on Historical Nodes
druid.worker.capacity on MiddleManagers
Please see the Druidconfiguration documentation for a full description of all possible configuration options
cd $DRUID_HOME/conf/druid/historical
vi jvm.config
-server
-Xms4g
-Xmx4g
-XX:MaxDirectMemorySize=3072m
-Duser.timezone=UTC+08:00
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=/hadoop/haozhuo/druid/var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
vi runtime.properties
備注:端口本來應該是預設8023,但是該端口被其他程式占用了,是以修改成8283。druid.processing.numThreads和druid.processing.buffer.sizeBytes縮小了一半,記憶體不夠用
druid.service=druid/historical
druid.port=8283
# HTTP server threads
#druid.server.http.numThreads=25
druid.server.http.numThreads=20
# Processing threads and buffers
#druid.processing.buffer.sizeBytes=536870912
druid.processing.buffer.sizeBytes=268435456
#druid.processing.numThreads=7
druid.processing.numThreads=3
# Segment storage
druid.segmentCache.locations=[{"path":"var/druid/segment-cache","maxSize"\:130000000000}]
druid.server.maxSize=130000000000
cd $DRUID_HOME/conf/druid/middleManager
vi jvm.config
-server
-Xms64m
-Xmx64m
-Duser.timezone=UTC+08:00
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=/hadoop/haozhuo/druid/var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
vi runtime.properties
druid.service=druid/middleManager
druid.port=8091
# Number of tasks per middleManager
druid.worker.capacity=3
# Task launch parameters
druid.indexer.runner.javaOpts=-server -Xmx2g -Duser.timezone=UTC+08:00 -Dfile.encoding=UTF-8 -Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
druid.indexer.task.baseTaskDir=/hadoop/haozhuo/druid/var/task
# HTTP server threads
druid.server.http.numThreads=20
# Processing threads and buffers
druid.processing.buffer.sizeBytes=268435456
druid.processing.numThreads=2
# Hadoop indexing
druid.indexer.task.hadoopWorkingPath=/druid/tmp/druid-indexing
druid.indexer.task.defaultHadoopCoordinates=["org.apache.hadoop:hadoop-client:2.7.0"]
步驟八:Tune Druid Brokers
Druid Brokers also benefit greatly from being tuned to the hardware they run on. If you are usingr3.2xlarge EC2 instances, or similar hardware, the configuration in the distribution is a reasonable starting point.
If you are using different hardware, we recommend adjusting configurations for your specific hardware. The most commonly adjusted configurations are:
-Xmx and -Xms
druid.server.http.numThreads
druid.cache.sizeInBytes
druid.processing.buffer.sizeBytes
druid.processing.numThreads
druid.query.groupBy.maxIntermediateRows
druid.query.groupBy.maxResults
Please see the Druidconfiguration documentation for a full description of all possible configuration options.
cd $DRUID_HOME/conf/druid/broker
vi jvm.config
-server
-Xms12g
-Xmx12g
-XX:MaxDirectMemorySize=3072m
-Duser.timezone=UTC+08:00
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=/hadoop/haozhuo/druid/var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
vi runtime.properties
備注:端口本來應該是預設8022,但是該端口被其他程式占用了,是以修改成8282。
druid.service=druid/broker
druid.port=8282
# HTTP server threads
druid.broker.http.numConnections=5
druid.server.http.numThreads=25
# Processing threads and buffers
druid.processing.buffer.sizeBytes=268435456
druid.processing.numThreads=3
# Query cache
druid.broker.cache.useCache=true
druid.broker.cache.populateCache=true
druid.cache.type=local
druid.cache.sizeInBytes=1000000000
步驟九:Open ports (if using a firewall)
If you're using a firewall or some other system that only allows traffic on specific ports, allow inbound connections on the following:
1527 (Derby on your Coordinator; not needed if you are using a separate metadata store like MySQL or PostgreSQL)
2181 (ZooKeeper; not needed if you are using a separate ZooKeeper cluster)
8081 (Coordinator)
8082 (Broker) 注意:此端口已被其他程式占用。在conf/druid/historical/runtime.properties中修改成8282。
8083 (Historical) 注意:此端口已被其他程式占用。在conf/druid/historical/runtime.properties中修改成8283。
8084 (Standalone Realtime, if used)
8088 (Router, if used)
8090 (Overlord)
8091, 8100–8199 (Druid Middle Manager; you may need higher than port 8199 if you have a very highdruid.worker.capacity)
8200 (Tranquility Server, if used)
In production, we recommend deploying ZooKeeper and your metadata store on their own dedicated hardware, rather than on the Coordinator server.
步驟十:啟動
修改:-Djava.io.tmpdir=var/tmp
修改:conf/druid/coordinator/jvm.config 中的-Dderby.stream.error.file=var/druid/derby.log
確定Zookeeper和MySQL已經啟動。
我有三台機子,每台機子如下
機子 官網推薦配置 druid啟動部分 程序記憶體占用 總的記憶體占用
192.168.1.150 4 vCPUs, 15 GB RAM ,80 GB SSD storage Coordinator jvm:3g(預設3g) jvm:6g
Overlord jvm :3g(預設3g)
192.168.1.152 8 vCPUs,61 GB RAM,160 GB SSD storage historical jvm:4g(預設8g),DirectMemory:3g(預設4g) jvm:10g+
middleManager jvm:2g(預設2g),buffer:1g(預設1g)
Tranquility 所需記憶體另算
192.168.1.153 8 vCPUs,61 GB RAM,160 GB SSD storage Broker jvm:12g(預設24g),DirectMemory:3g(預設4g) jvm:15g
注意historical中DirectMemory中的計算方式:
memoryNeeded[3,221,225,472] = druid.processing.buffer.sizeBytes[536,870,912] * (druid.processing.numMergeBuffers[2] + druid.processing.numThreads[3] + 1)
将druid-0.10.0複制到其他節點:
scp -r druid-0.10.0 [email protected]:/hadoop/haozhuo/druid
scp -r druid-0.10.0 [email protected]:/hadoop/haozhuo/druid
1) 在192.168.1.150上Start Coordinator, Overlord
啟動coordinator
cd $DRUID_HOME;nohup java `cat conf/druid/coordinator/jvm.config | xargs` -cp conf/druid/_common:conf/druid/coordinator:lib/* io.druid.cli.Main servercoordinator &
tail -1000f nohup.out
啟動 overlord
cd $DRUID_HOME; nohup java `cat conf/druid/overlord/jvm.config | xargs` -cp conf/druid/_common:conf/druid/overlord:lib/* io.druid.cli.Main serveroverlord &
2) 在192.168.1.152上Start Historicals and MiddleManagers
啟動historical
cd $DRUID_HOME; nohup java `cat conf/druid/historical/jvm.config | xargs` -cp conf/druid/_common:conf/druid/historical:lib/* io.druid.cli.Main serverhistorical &
啟動middleManagercd $DRUID_HOME; nohup java `cat conf/druid/middleManager/jvm.config | xargs` -cp conf/druid/_common:conf/druid/middleManager:lib/* io.druid.cli.Main server middleManager&
是否需要部署Tranquility Server?
You can add more servers with Druid Historicals and MiddleManagers as needed.
這部分注意下,後面Spark Streaming流式攝入時可能會用到:
If you are doing push-based stream ingestion with Kafka or over HTTP, you can also start Tranquility Server on the same hardware that holds MiddleManagers and Historicals. For large scale production, MiddleManagers and Tranquility Server can still be co-located. If you are running Tranquility (not server) with a stream processor, you can co-locate Tranquility with the stream processor and not require Tranquility Server.
curl -O http://static.druid.io/tranquility/releases/tranquility-distribution-0.8.0.tgztar -xzf tranquility-distribution-0.8.0.tgzcd tranquility-distribution-0.8.0bin/tranquility <server or kafka> -configFile <path_to_druid_distro>/conf/tranquility/<server or kafka>.json
3)在192.168.1.153上Start Druid Broker
cd $DRUID_HOME; nohup java `cat conf/druid/broker/jvm.config | xargs` -cp conf/druid/_common:conf/druid/broker:lib/* io.druid.cli.Main server broker &
自己寫的腳本
所有機子添加:stopDruid.sh
pids=`ps -ef | grep druid | awk '{print $2}'`
for pid in $pids
do
kill -9 $pid
done
部署coordinator和overlord的機子,添加startDruid.sh
java `cat $DRUID_HOME/conf/druid/coordinator/jvm.config | xargs` -cp $DRUID_HOME/conf/druid/_common:$DRUID_HOME/conf/druid/coordinator:$DRUID_HOME/lib/* io.druid.cli.Main server coordinator >> $DRUID_HOME/start.log &
java `cat $DRUID_HOME/conf/druid/overlord/jvm.config | xargs` -cp $DRUID_HOME/conf/druid/_common:$DRUID_HOME/conf/druid/overlord:$DRUID_HOME/lib/* io.druid.cli.Main server overlord >> $DRUID_HOME/start.log &
部署historical和middleManager的機子,添加startDruid.sh
java `cat $DRUID_HOME/conf/druid/historical/jvm.config | xargs` -cp $DRUID_HOME/conf/druid/_common:$DRUID_HOME/conf/druid/historical:$DRUID_HOME/lib/* io.druid.cli.Main server historical >> $DRUID_HOME/start.log &
java `cat $DRUID_HOME/conf/druid/middleManager/jvm.config | xargs` -cp $DRUID_HOME/conf/druid/_common:$DRUID_HOME/conf/druid/middleManager:$DRUID_HOME/lib/* io.druid.cli.Main server middleManager >> $DRUID_HOME/start.log &
部署broker的機子,添加startDruid.sh
java `cat $DRUID_HOME/conf/druid/broker/jvm.config | xargs` -cp $DRUID_HOME/conf/druid/_common:$DRUID_HOME/conf/druid/broker:$DRUID_HOME/lib/* io.druid.cli.Main server broker >> $DRUID_HOME/start.log &
Loading data
Congratulations, you now have a Druid cluster! The next step is to learn about recommended ways to load data into Druid based on your use case. Read more aboutloading data.
Load streaming data
http://druid.io/docs/0.10.0/tutorials/quickstart.html
To load streaming data, we are going to push events into Druid over a simple HTTP API. To do this we will use [Tranquility], a high level data producer library for Druid.
To download Tranquility, issue the following commands in your terminal:
curl -O http://static.druid.io/tranquility/releases/tranquility-distribution-0.8.0.tgztar -xzf tranquility-distribution-0.8.0.tgzcd tranquility-distribution-0.8.0
We've included a configuration file in conf-quickstart/tranquility/server.json as part of the Druid distribution for a metricsdatasource. We're going to start the Tranquility server process, which can be used to push events directly to Druid.
bin/tranquility server -configFile <path_to_druid_distro>/conf-quickstart/tranquility/server.json
This section shows you how to load data using Tranquility Server, but Druid also supports a wide variety of other streaming ingestion options, including from popular streaming systems like Kafka, Storm, Samza, and Spark Streaming.
The dimensions (attributes you can filter and split on) for this datasource are flexible. It's configured for schemaless dimensions, meaning it will accept any field in your JSON input as a dimension.
The metrics (also called measures; values you can aggregate) in this datasource are:
count
value_sum (derived from value in the input)
value_min (derived from value in the input)
value_max (derived from value in the input)
We've included a script that can generate some random sample metrics to load into this datasource. To use it, simply run in your Druid distribution repository:
bin/generate-example-metrics| curl -XPOST -H'Content-Type: application/json' --data-binary @- http://localhost:8200/v1/post/metrics
Which will print something like:
{"result":{"received":25,"sent":25}}
This indicates that the HTTP server received 25 events from you, and sent 25 to Druid. Note that this may take a few seconds to finish the first time you run it, as Druid resources must be allocated to the ingestion task. Subsequent POSTs should complete quickly.
Once the data is sent to Druid, you can immediately query it.
Query data
Direct Druid queries
Druid supports a rich family of JSON-based queries. We've included an example topN query in quickstart/wikiticker-top-pages.json that will find the most-edited articles in this dataset:
curl -L -H'Content-Type: application/json' -XPOST --data-binary @quickstart/wikiticker-top-pages.json http://localhost:8082/druid/v2/?pretty
Visualizing data
Druid is ideal for power user-facing analytic applications. There are a number of different open source applications to visualize and explore data in Druid. We recommend trying Pivot, Superset, or Metabase to start visualizing the data you just ingested.
If you installed Pivot for example, you should be able to view your data in your browser at localhost:9090.
SQL and other query libraries
There are many more query tools for Druid than we've included here, including SQL engines, and libraries for various languages like Python and Ruby. Please see the list of libraries for more information.
測試從HDFS導入資料到Druid
overlord console:http://192.168.1.150:8090/console.html
cd $DRUID_HOME
curl -X 'POST' -H 'Content-Type:application/json' -d @quickstart/wikiticker-index.json 192.168.1.150:8090/druid/indexer/v1/task
查詢:
curl -L -H'Content-Type: application/json' -XPOST --data-binary @quickstart/wikiticker-top-pages2.jsonhttp://192.168.1.153:8282/druid/v2/?pretty
流式攝入:
啟動:
注意,必須在該目錄下啟動
cd /hadoop/haozhuo/druid/tranquility-distribution-0.8.2;
bin/tranquility server-configFile $DRUID_HOME/conf/tranquility/server.json
//測試插入
cd $DRUID_HOME;
bin/generate-example-metrics| curl -XPOST -H'Content-Type: application/json' --data-binary @-http://192.168.1.152:8200/v1/post/metrics
//查詢
curl -L -H'Content-Type: application/json' -XPOST --data-binary @quickstart/wikiticker-top-pages.json http://192.168.1.152:8082/druid/v2/?pretty
curl -L -H'Content-Type: application/json' -XPOST --data-binary @quickstart/wikiticker-top-pages2.json http://192.168.1.153:8282/druid/v2/?pretty
curl -L -H'Content-Type: application/json' -XPOST --data-binary @quickstart/test-top-pages.json http://192.168.1.153:8282/druid/v2/?pretty
http://192.168.1.150:8081/#/
---------------------
druid.io實踐分享之Realtime+kafka
但如何發揮到最好、最穩定,需要更多細節的調整。
我會從整體部署、實時節點、曆史節點、broker節點來依次介紹。
從整體部署來看:
第一:druid.io 屬于IO和CPU雙重密集型引擎,是以對記憶體、CPU、硬碟IO都有特定要求,特别提醒,如果資金充足,可以直接上SSD(記憶體和CPU同理)。
第二:部署的整個過程需要多次練習,并記錄成流程規範,因為整體叢集涉及的層次較多,如果不進行流程規範化,會導緻因人不同,使線上操作出現問題
第三:相應的監控機制,要配合到位,後期在整體部署中,逐漸進行實施自動化方式
第四:各節點類型服務啟動時,沒有明确的先後順序
整體完整結構如下:
目前作者成立的https://imply.io 提供了更加完善的解決方案,有興趣的可以參考下。
首先我們來分析下實時節點。
對實時節點(realtime)我考慮從兩個方面來分享:
一個方面:資料本身要求
一個方面:realtime運作階段出現的一些問題(如:segment堆積等)
首先我會對背景進行介紹下,我們是一個CPA廣告聯盟,有impression、click、conversion等類型的資料。對我們而言conversion資料最重要,因為我們是conversion來計費的。是以就有一個高标準conversion類型資料不能丢失且不能重複,對另外兩類型資料在一定範圍内可以接受少數丢失和少數重複。我們是基于6.0的版本來分析的。
初期druid的實時資料擷取的方式是通過realtime節點結合kafka的方式,是以提供了不丢失資料的優勢,如果對實時資料的各方面要求很高的前提下,realtime節點結合kafka的方式還是會帶來諸多問題(這也是新版本中已經不推薦使用的原因,個人見解任何系統隻要使用了kafka叢集都會有這樣的情況發生,隻要努力去解決就好)。
場景如下:
場景一:realtime保證了不少資料,但沒保證不多資料
場景二:realtime節點是單點特性,這樣一旦一個節點出問題,對資料敏感的話,會立馬發現問題
場景三:realtime節點沒有提供安全關閉的邏輯(官方是提供直接kill方式)
場景四:realtime在某些場景中,還是會掉資料
另外也存在少量的bug,這個可以忽略下(在6.0版本之後都得到了修複)。我将一一對這些場景的産生及解決方式進行闡述。
場景一:
确實隻要你的資料進入了kafka叢集,資料是真的不丢失(當然如果kafka的硬碟已經滿了這種情況,一般都會用監控的方式去規避吧)。但是為了支援多個realtime節點,kafka裡的topic必須進行分區,不然無法整體提升并發的能力。如下圖:
并且官方文檔給出的kafka使用有一個參數:
"auto.commit.enable": "false"
也就是交由realtime節點自行管理。這個參數設定成false後,realtime會在把一個時間段的資料持久化之後,才會給kafka叢集發一個commit指令。
正是因為這個邏輯,是以線上上運作階段,當consumer組裡某個一個消費者出現某種問題,會導緻沒有及時對topic消費進行響應(但是已經正常消費資料了),這時候kafka會對分區進行重新調整,導緻其它消費者會根據上次的offset進行消費資料,進而最終導緻資料重複。如下圖:
場景二:
總體來說也是由于場景一帶來的副作用,由于分區導緻,每一個partition被一個cousumer消費,是以多個realtime節點就是單點特性,kill任意一台realtime節點反過來也會激活kafka叢集對partition再配置設定的處理。是以會出現這樣的場景一旦啟動realtime節點,就永久無法正常shutdown(隻能用kill方式)。并且多realtime節點一起啟動時,在啟動的過程中,每個節點啟動間隔不能太長(原因大家可以想想,是以一般會使用一個遠端啟動腳本方式,統一進行遠端啟動)。首先我先啟動realtime1節點,如下圖:
3個partition先配置設定給realtime1,分别從offset=300、200、100開始消費。過1分鐘後再啟動realtime2節點,這樣會觸發partition動态配置設定事件,啟動時假設realtime1已經消費到offset=312、222、133,但還沒有送出commit(是以kafka那邊的offset值是不變的)
如下圖:
假設重新配置設定後,partition-3配置設定給了realtime2,那麼realtime2節點将從offset=100的位置開始進行消費,如下圖:
這就是realtime節點間啟動間隔不能太長的原因。
場景三:
跟場景二有關,就是沒有提供安全關閉的指令(隻能kill),這會讓實際操作過程中,有種不安全感,雖然kill掉後,可以通過kafka來恢複,但是在這種場景下,還是會導緻資料重複,例如:當realtime已經對資料持久化了,但還沒來得及傳回offset告知kafka叢集(是将 auto.commit.enable = false),這時realtime節點被kill掉後。如下圖:
kill指令發生在持久化之後,commit之前。如下圖:
再重新開機realtime節點就會引發資料重複消費。
可能大家會發現,如果kill指令發生在記憶體Cache到持久化之間,會不會重複?當auto.commit.enable = false情況下,這塊的資料是會從kafka裡恢複回來的。
解決方案
其實場景一、二和三,總結起來其實是一個類别的情況,需要整體一起考慮去解決。
後面版本中,官方了給出了一個方案類似于雙機熱備,簡單的說,就是兩個realitme節點對應一個partition,但我沒有去嘗試過,這裡主要介紹下我們在當時如何解決這樣的場景的(特别是kafka、realtime叢集在擴容或者删除節點的時候,也會帶來這樣的問題)。
首先給出一個最簡單方式,在采集層做資料的backup,如果你的segment是設定的一個小時,那麼就按小時進行check。發現異常,就用backup資料進行修複還原。
我們嘗試下來後,發現客戶在使用的過程中,會回報為什麼上一個小時的資料有變化,給使用者的體驗不好(當然後期我們可以做到提前發消息通知使用者告知),站在使用者的角度出發希望資料不要經常變動,這樣使用者會質疑你的系統,而對我們開發人員來說,可以讓資料補進目前這個時間段裡,總體來說沒有讓資料丢失。其次按每小時check背景邏輯複雜,人工幹預工作量很大。再次就是當我們開發在進行快速疊代和上線的時候,勢必帶來相關資料修複工作,影響效率(最常見的就是增加緯度資訊時)。
後來我們讨論了後,重新訂了一個新方案:
增加安全關閉邏輯
realtime叢集增加一層Cache,用于重複資料過濾
改auto.commit.enable = true,并将zk同步時間稍微縮
定期記錄partition的offset值,用于復原
注:這些方式不一定是最通用最完美的方式,但在當時一定是适合我們需要的方式。
以下是安全關閉部分
啟動時 RealtimeManager 為每個datasouce, 啟動一個線程, 建立一個FireChief
FireChief 持有RealtimePlumber 和Firehose
FireChief消費資料邏輯
plumber.startJob();
while(notSafeCloseFlag && firehose.hasNext())
定時 persistent
plumber.finishJob();
plumber.finishJob邏輯
basePersistent 下面的datasource下的檔案夾表示sink, 現在系統中一個小時一個Sink
一個plumber 持有多個sink.
Sink持有多個FireHydrant, 但隻有一個是激活狀态, 用于接收資料
一個FireHydrant儲存在0, 1, 2 檔案夾下。
對應一個IncrementalIndex和一個Segment
index 表示記憶體中的對象
segment 表示持久化對象
hasSwapped表示十分已經持久化
swap操作: 建立segment, 将index設定成null
stop邏輯, 見流程圖
RealtimeManager層次圖:
stop關閉流程圖:
關于Cache層解決方式,很多人都提過有單點故障,但這個時候需要具體分析了,首先我們這裡主要解決是conversion問題,就數量級來說conversion比impression、click要小太多了;其次Cache的conversion不是永久的(屬于一個區間内),不會出現資料量過于膨脹;再次邏輯簡單因為conversion隻有主鍵存儲及判斷,不會負載很重。要而且經過了時間證明,運作了兩年多零故障率。結構如下圖:
後面兩點,屬于小調整,這樣的好處:
一是重複資料量較小,在面對每天10多億資料的流轉過程中,不影響體驗
二是復原offset的範圍可控
通過此方式,我們進行不斷的調整、測試、驗證和細節優化,最終做到了整體資料丢失率99.99%(由測試部門給出的),conversion資料丢失率是0的效果。并且也讓人工幹預的操作減少很多。
場景四:
當資料量進來的速率高于消費的速率時,就會引發資料丢失,主要原因就是windowPeriod這個參數設定,假設segment是設定成1個小時,其windowPeriod設定成PT10m,目前時間是13點,那麼就表示在13點10分之前(包含10分)還可以繼續消費12點-13點之間的資料,大家應該知道在海量資料傳輸時,不可能在13點整點就能消費完成12點-13點之間的資料,是以druid在配置時,提供了一個緩沖區間,我們在整個運作過程中出現過兩次,第一次是就是速率突然暴漲導緻,第二次是因為資料的時間導緻。
這樣的場景在實際的營運過程中,不會常碰到,但不排除惡意攻擊或者刷流量的情況。
一般解決方式:
第一:流控報警
第二:時間重置
流控主要是定時監控Kafka叢集裡的offset的內插補點,發現內插補點變大就要報警。這時的政策就是資料采集服務層降低寫入速度(這部分最後也可以變成自動化方式進行),讓realtime節點叢集的消費得到緩解。然後快速定位到底是達到了目前消費極限還是其它問題。
時間重置通過讀取windowPeriod的值,來進行換算,将此記錄放到下一個時間段裡,
舉例說明:windowPeriod設定成10分鐘,目前的click資料的時間是17:59:44,目前系統時間是18:10:23,這時滿足18:10:23-17:59:44>10分鐘,将對此click資料的時間重置成18:10:23,進入下一個時間段。
這種方式,特别适合自動化補數,提高效率。
以上就是資料本身的要求所帶來的全部内容。
下一篇我将介紹realtime結合kafka在運作階段會出現場景及解決方式。
本節重點介紹在運作過程中,這兩個元件會出現什麼問題及解決方式
場景如下:
場景1、第一次上線kafka的partition與realtime的個數關系
場景2、kafka資料寫入最優方式
場景3、realtime配置檔案在實際過程的變化及重點參數
場景4、segment堆積産生的原因及如何避免
場景5、realtime對JVM的要求
場景6、多個dataSource,大小表拆分,多topic消費
場景一
初次上線要目前的資料量、叢集規模等因素來綜合考慮。基本定律是(以一個topic為例):
partitions=N*realtimes
partitions表示目前topic的分區數
N表示每台realtime消費的partition的個數
realtimes表示realtime節點總數
舉例說明:
3個partitions,3台realtime,那麼N就是1。表示每台realtime節點消費1個partitions。
6個partitions,3台realtime,那麼N就是2。表示每台realtime節點消費2個partitions。
同理都是類似方式計算。
為撒這樣計算?主要考慮就是均衡,充分利用好每台realtime節點的資源。
随着資料量的增加,會碰到目前topic的消費速率變慢的情況,這個時候就會對kafka叢集增加節點或增加kafka節點硬碟或擴充partition個數。
增加節點和增加硬碟都屬于kafka本身的操作,不會影響到realtime這層。但擴充partition個數時,realtime節點在水準擴充的時候,就需要考慮下realtime節點增加的個數(參考上面的公式來算)。
場景二
kafka寫入最優方式是均衡,如果不均衡,會影響到兩個點:
- kafka節點有些硬碟會報警并且通過監控平台會發現有些機器負載高,有些負載低。
- 接着帶來就是realtime消費的不均衡,也會導緻有些機器負載高,有些負載低。
是以使用新的hash算法(這個調整後一定要進行測試驗證),我們重新開發了配置設定算法。預設情況下,Kafka根據傳遞消息的key來進行分區的配置設定,即hash(key) % numPartitions。
但因為Key的關系預設情況下,寫入各partition資料還是會出現不均衡的。
調整成輪訓方式即可。
場景三
這裡先說的參數重點是指runtime.properties檔案裡屬性druid.realtime.specFile所對應的json檔案内容。涉及的參數如下:
第一:shardSpec
第二:rejectionPolicy
第三:intermediatePersistPeriod ≤ windowPeriod < segmentGranularity 和 queryGranularity ≤ segmentGranularity
**shardSpec**
預設設定成
"shardSpec": {"type": "none"} 這種情況單機版還可以玩一玩。在多個realtime節點的情況下,這個不能這樣設定了。
現在官方文檔提供:linear and numbered,但在源碼中還提供了另一種SingleDimensionShardSpec,這種使用較少。
這裡可以給大家分享一下,當多個realtime節點時還配置成預設值的效果(這是當初文檔沒有現在這麼詳細導緻我們疏忽了),那麼就是目前小時範圍内的資料是跳躍的,簡單的說,就是同一個查詢條件發多次,傳回的結果集大小不同,有時候傳回30多條,有時候又傳回50多條。在當時對初學的人來說很緊張,後面通過源碼分析和大家的努力,終于發現了是這個參數配置失誤導緻。
但這個調整是有要求的,就是調整完後,必須對目前時間段realtime所有節點已經存儲的資料要删除掉,不然查詢的結果還是跳躍的。
舉例說明:
目前時間段是12點-13點(假設segment是按小時進行),我是在12點20分調整此參數,那麼再重新開機全部realtime節點之前,必須把12點-13點之間已經持久化的資料要删除掉,不然調整成linear後,是沒有任何效果的。這個步驟非常重要。
另外注意下:
realtime 節點1設定為:
“partitionNum” : 1
realtime 節點2設定為:
“partitionNum” : 2
realtime 節點3設定為:
“partitionNum” : 3
依次類推。
關于numbered和linear的差別很小,主要在查詢上面的限制,大家檢視官方文檔再實踐下就知道了。
**rejectionPolicy**
此參數要是不了解,帶來的效果就是丢失資料,會讓你誤認為系統有bug。
有三個值:serverTime(推薦使用)、messageTime、none。
如果想不丢棄資料就用none,另外一個用系統時間作為參考,一個用event裡的timestamp作為參考。如果此參數是none的話,windowPeriod這個參數就沒有什麼效果了。
是以當資料有丢失的時候,首先檢查時間戳和這個參數。也就是檢查資料裡面的timestamp和系統時間是否有較大的誤差。(提醒下:首先要保證json資料格式要能正常解析)
**intermediatePersistPeriod、windowPeriod、segmentGranularity和queryGranularity**
在實際的使用過程中,這幾個參數的關聯關系一定要當心。
首先介紹下intermediatePersistPeriod、windowPeriod、segmentGranularity三個是緊密關聯的,特别windowPeriod這個參數不光控制資料消費延遲,也控制着segment合并持久化。
并且intermediatePersistPeriod參與的邏輯部分和windowPeriod參與的邏輯部分,是兩個線程分開進行的。
劉博宇,滴滴出行進階軟體開發工程師,就職于滴滴基礎平台大資料架構部。負責Druid叢集維護與研發工作。
摘要:
Druid是一款支援資料實時寫入、低延時、高性能的OLAP引擎,具有優秀的資料聚合能力與實時查詢能力。在大資料分析、實時計算、監控等領域都有特定的應用場景,是大資料基礎架建構設中重要的一環。Druid在滴滴承接了包括實時報表、監控、資料分析、大盤展示等應用場景的大量業務,作為大資料基礎設施服務于公司多條業務線。本次演講我們将介紹Druid的核心特性與原理,以及在滴滴内部大規模使用中積累的經驗。
分享大綱:
1、Druid特性簡介
2、Druid在滴滴的應用
3、Druid平台化建設
4、展望
正文:
一、Druid特性簡介
Druid是針對時間序列資料提供的低延時資料寫入以及快速互動式查詢的分布式OLAP資料庫。其兩大關鍵點是:首先,Druid主要針對時間序列資料提供低延時資料寫入和快速聚合查詢;其次,Druid是一款分布式OLAP引擎。
針對第一個特點來看,Druid與典型的TSDB,比如InfluxDB、Graphite、OpenTSDB的部分特性類似。這些時序資料庫具備一些共同特點,一是寫入即可查,通過記憶體增量索引讓資料寫入便可查詢;二是下采樣或RDD,通過下采樣或類似于RDD的操作減少資料量,而Druid在資料寫入時就會對資料預聚合,進而減少原始資料量,節省存儲空間并提升查詢效率;三是可能會支援Schema less,在InfluxDB中,使用者可任意增加tag,InfluxDB可對新增tag進行聚合查詢,但Druid在這點上與InfluxDB略有差異,Druid需要預先定義Schema 。Druid的Schema資料打包在最後形成的資料檔案中,資料檔案按照時間分片,也就是說過去和未來資料的Schema可以不同,而不同schema的資料可以共存。是以,雖然Druid不是schema less的,但是Schema調整也是比較靈活。
另外,Druid作為一個OLAP資料庫。OLAP資料庫需要支援類似上卷、切塊、切片、下鑽等操作,但不适合明細查詢。對于類似根據某主鍵ID定位唯一資料的任務,OLAP資料庫并不能友好支援。常用的OLAP資料庫實作方式以下幾種:1)資料檢索引擎,比如ES;2)預計算加KV存儲實作,比如Kylin;3)SQL on Hadoop 引擎,比如 Presto、SparkSQL。
接下來,我們就以上中實作進行對比。首先是資料檢索引擎的代表ES,ES可以存儲結構化和非結構化資料,同時具備明細查詢和聚合查詢能力,由于其自身是一個資料檢索引擎,其索引類型并不是針對聚合分析設計的,是以聚合查詢方面開銷較大;其次,ES不但要儲存所有的原始資料,還需要生成較多的索引,是以存儲空間開銷會更大,資料的寫入效率方面會比Druid差一些。
與ES相比,Druid隻能處理結構化資料,因為它必須預定義Schema;其次,Druid會對資料進行預聚合以減少存儲空間,同時對資料寫入和聚合進行優化。但是,由于進行了預聚合,是以Druid抛棄掉了原始資料,導緻其缺少原始明細資料查詢能力。如果業務方有需求,可以關閉預聚合,但會喪失Druid的優勢。
其次是預計算 + kv存儲方式 ,KV存儲需要通過預計算實作聚合,可以認為Key涵蓋了查詢參數,而值就是查詢結果,由于直接從KV存儲進行查詢,是以速度非常快。缺點是因為需要在預計算中處理預設的聚合邏輯,是以損失了查詢靈活性,複雜場景下的預計算過程可能會非常耗時,而且面臨資料過于膨脹的情況;由于隻有字首拼配一種索引方式,是以在大資料量的複雜過濾條件下,性能下降明顯;且缺少聚合下推能力。
與預計算+KV存儲方式相比,Druid 是使用Bitmap索引的列式存儲,查詢速度肯定不如KV存儲快; 但是由于使用記憶體增量索引,增量預聚合的模式,寫入即可查,無需等待預計算生成Cube,是以實時性更強;其次,Druid可針對任意次元組合過濾、聚合,查詢更加靈活;最後,Scatter & Gather模式支援一定的聚合下推。
最後是SQL on Hadoop, 這類引擎的SQL支援通常很強大,且無備援資料,不需要預處理。缺點是因為其直接通過計算引擎對Hadoop上的檔案進行操作,是以響應速度較慢且QPS相對較低。
與SQL on Hadoop方式相比,Druid的SQL支援有限,但在逐漸完善;必須預定義次元名額。其優勢在于可達到亞秒級響應,并發較高。
二、Durid在滴滴的應用
Druid目前在滴滴使用規模大概為多個叢集百餘台機器,日原始資料寫入量在千億級别,日落盤資料在TB級别,數百實時資料源、千級實時寫入任務,日查詢量近千萬級。主要承接業務有監控、實時報表,大屏展示等。
下圖為滴滴實時業務監控案例:
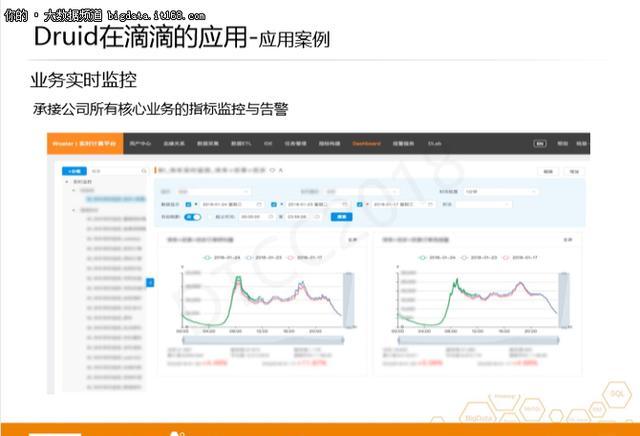
我們的監控體系大概可以分為三層:頂層為業務監控,主要由業務方定義名額,然後配置相應的查詢和報警。主要目的在于及時發現業務問題并告警;中層的監控體系是對各服務網關調用的監控日志,主要為了發現某業務問題造成的影響範圍和具體影響對象;底層運維體系主要對網絡、機器各方面名額進行監控。
之是以業務監控适用Druid,是因為業務名額通常具有較為複雜多變的業務邏輯。Druid本身是一個OLAP引擎,定義一個資料源就可衍生出衆多聚合名額,是以很适合這類靈活查詢的配置。
第二類應用是實時報表類應用(如下圖),實時報表類應用主要用于營運資料分析,用戶端網絡性能分析以及客服應答實時統計等。這些使用者通常是從Hive資料倉庫遷移過來的,因為希望獲得實時使用者體驗而Hive查詢速度太慢,是以選擇遷移。典型應用場景比如快速擷取某下雨區域的使用者單據,對使用者進行優惠券投放進而刺激使用者打車。

第三類是大屏展示類應用(如下圖),這類應用主要用于呈現業務性關鍵結果,通常是PV、UV或TOP N查詢,非常适合Druid。
三、Druid平台化建設
在承接應用場景的過程中,我們做了很多平台化建設。簡單啊介紹下平台化建設的背景: 業務資料主要來源是日志和binlog;公司統一資料通道是kafka;業務名額多樣,邏輯複雜多變;Druid接入配置較複雜,除Schema配置外,還包括實時任務配置;資料進入Druid之前通常需要流計算處理,業務方自己開發既費時又很容易出現問題;Druid資料的對應關系以及資料源衍生名額鍊路較長,需要進行上下遊關系梳理;由于Druid官方主要通過API查詢,未提供資料可視化服務元件,是以業務方急需資料可視化相關服務元件。
在以上的背景下,我們建構了實時計算平台,架構圖如下:
底層引擎有三部分組成,流計算引擎包括Flink Streaming和Spark Streaming,存儲部分主要依靠Druid;流計算引擎之上,我們主要開發了WebIDE和任務管理功能,WebIDE在Web内部內建,我們會為使用者提供相應模闆,使用者根據相應的模闆進行進行開發,即可形成自己的流計算任務,簡化了一些邏輯較簡單的常見ETL、Join任務的開發。任務完成後可通過任務管理平台直接送出,同時使用者自己在本地開發的流計算任務也可以上傳到平台,通過平台執行,平台對任務提供相應的名額檢測。基于Druid引擎,配置 Druid資料源,通過資料源衍生名額,每一個名額其實就是對Druid的一個查詢。使用者可針對名額配置告警。上圖右側的DCube是一個拖拽式資料分析的前端工具,DSQL讓使用者可直接寫SQL的方式輸出Druid的即席查詢能力。
根據配置的名額進行告警,分為兩大類,一類是門檻值告警;一類是模型告警。通常對規律性不太強的數值配置門檻值告警,對規律性較強的名額配置模型告警。如滴滴每天的訂單呼叫量基本上呈現一個早高峰、一個晚高峰,中間較平穩的狀态。通常會選取過去一段時間的資料進行模型訓練,由使用者在得到的預測基線上設定置信區間。如果資料超過置信區間,就會報警。當然,也會存在一些較難處理的特殊情況,比如突然下雨、熱門電影首映結束等導緻的訂單激增,需要額外去考慮一些情況。
上圖為基本工作流,整體工作流程為由MySQL的binlog和日志采集資料,形成原始topic,經過ETL或者多流Join進入清洗後的topic,此時使用者可以使用平台提供的魔闆功能或自行開發流計算任務,我們會為所有流計算任務定制一些預設的實時名額,這些名額和使用者的業務資料都會在Druid中建立datasource。Druid也可通過Hive離線導入資料,離線資料源和實時資料源兩部分組成了Druid的基本資料,之後根據基本資料建構業務名額、任務名額,完成報警配置。如果業務方具備一定開發能力,需要把資料接入到自己的系統,我們也會提供一些Open API。平台為使用者提供了自助式的Druid資料源接入頁面,極大簡化地了Druid資料接入的複雜過程。
Druid查詢采用100% SQL 的Web化配置。Druid原生查詢是DSL,類似JSON格式,但學習成本較高。在支援SQL之後,除了部分使用者自建服務外,平台所有查詢全部遷移到SQL。
在平台化過程中,我們遇到了一些挑戰:一是核心業務與非核心業務共享資源,存在一定風險;二是使用者自助送出任務配置、查詢不合理,造成異常情況,甚至影響整個叢集的穩定性;三是随着業務的快速發展,Druid依賴的元件都需要熱遷移到獨立部署環境。在滴滴内部,由于Druid資料源基本都是使用者自助接入,是以業務增長迅速,一年時間幾乎漲了四倍,這對Druid依賴元件的熱遷移提出了要求。
針對不同重要程度的業務共享資源問題,首先建設 Druid叢集的異地雙活機制,核心資料源的叢集級雙活。其次,通過統一網關對使用者屏蔽多叢集細節,同時根據使用者身份進行查詢路由,實作查詢資源隔離。最後,進行業務分級,核心業務進行叢集級雙活,對查詢資源需求較大但不過分要求實時性的業務配置設定獨立的查詢資源組,其他使用者使用預設資源池。
上圖為基本架構圖,首先我們會有多個查詢節點分布在不同叢集,非核心資料源單寫到公共叢集,核心資料源雙寫到兩個叢集,使用者使用身份驗證key通過網關路由進行查詢。
針對使用者配置與查詢不合理造成的異常,我們主要做了以下三點:一是引擎層面進行bad case防範,例如,druid資料時間字段設定合理的時間視窗限制,如果資料時間範圍異常,我們就會對它進行抛棄;二是對Druid原生API進行封裝,提供更加合理的預設配置,主要針對實時任務時長、任務數量以及記憶體進行配置;三是完善名額監控體系與異常定位手段,保證捕捉到異常查詢。Druid和網關日志通常會通過流計算任務進行處理,然後把它們分别寫入Druid和ES,數值名額會上報到Graphite,通過Grafana進行展示,綜合利用 Druid的聚合分析能力與和ES的明細查詢能力定位異常。
針對依賴元件的熱遷移問題,Druid主要依賴的元件有三個:ZooKeeper、MySQL、HDFS。在過去一年,滴滴完成了三大元件的遷移,主要過程如下:
1、ZooKeeper遷移原理:擴容-叢集分裂-縮容
在滴滴内部,ZK原來是與其他業務共用的,我們需要保證其他業務和Druid都不停服的情況下,把Druid的ZK叢集單獨遷移出來,是以我們采用了上述遷移方案。核心思路就是先擴容,随後利用兩套叢集配置,觸發叢集分裂,最後縮容掉不需要的節點。如圖4所示,這七台ZK配置其實有兩套,第一套是12347五台,第二套是567三台,但它們的leader都是ZK7,此時7個節點同屬一個叢集。當重新開機ZK7之後,兩套配置的ZK節點會分别獨立選取leader,此時進行叢集分裂變成兩個單獨的ZK叢集。
2、MySQL熱遷移實踐
我們主要使用Kafka-indexing-service作為實時資料寫入方式。在實時任務執行過程中,會中繼資料不斷更新到MySQL中的。要想對Mysql進行遷移,首先需要保證中繼資料在遷移過程中不變,是以首先要了解該資料寫入流程。在Kafka-indexing-service的實時任務執行過程中,中繼資料更新主要來自于實時任務執行狀态的變化和資料消費相關的部分API調用。實時任務的生命周期包括讀取資料和釋出資料兩個過程,讀取資料是從kafka讀取,在記憶體中建立增量索引;釋出資料過程,就是把實時節點消費的資料下推到曆史節點,其實是通過首先寫到HDFS,然後再由曆史節點加載。隻有在實時任務狀态發生改變時,才會産生中繼資料更新操作。是以,我們開發了實時任務狀态當機API,把所有實時任務的生命周期都當機在資料reading的狀态,此時進行MySQL遷移,遷移完成之後,重新啟動Overlord(一個管理實時任務的節點,所有實時任務的資料狀态變化都由Overlord觸發),實時任務就會繼續進行生命周期疊代。
3、HDFS遷移實踐
剛才提到了HDFS在資料釋出流程中的作用,資料釋出就是指實時節點消費到的資料下推到曆史節點的過程。下推的方式就是先推到HDFS,再由曆史節點從HDFS拉取。Master節點會告訴曆史節點那些資料是需要其拉取的,而從哪裡拉取則是從中繼資料存儲中獲得的,我們需要做的是保證曆史節點可以從兩個HDFS讀取資料,同時滾動重新開機實時節點,保證增量資料寫到新的HDFS,曆史節點從新的HDFS拉取資料。對于存量資料我們隻需要更改中繼資料裡曆史資料的路徑,就可以無縫替換原有HDFS。
接下來簡單介紹Druid平台化建設性能優化部分的工作。首先簡單介紹下Druid的三種資料寫入方式:
1、Standalone Realtime Node
該模式屬于單機資料消費,失敗後無法恢複,且由于其内部實作機制,該模式無法實作HA,這種方式官方也不推薦使用。
2、Tranquility + indexing-service
該方式主要通過Tranquility 程序消費資料,把資料主動push給indexing- service服務,優勢是Tranquility 程序可以幫助管理資料副本、資料實時任務以及生命周期等;其缺點是如果所有副本全部任務失敗,無法恢複資料;必須設定資料遲到容忍視窗,該視窗與任務時長挂鈎,由于任務時長有限,是以很難容忍長時間資料遲到。
3、Kafka-indexing-service
這是Druid比較新的寫入方式,其優勢主要展現在資料可靠性及任務恢複方面,彌補了前兩種方式的不足。其缺點是資料消費過于依賴Overlord服務,Overlord單機性能将會成為叢集規模瓶頸 ;由于Segment與Kafka topic的partition關聯,是以容易造成中繼資料過度膨脹,進而引發性能問題。最終,我們選擇Kafka-indexing-service 模式,并開始解決該模式存在的問題。
該寫入方式面臨的問題經過定位主要有以下三個:一是MySQL查詢性能問題, Overlord提供的多個API需要直接對MySQL進行操作,是以MySQL查詢性能直接影響Overlord并發水準;二是Druid裡所有資料都是JSON存儲格式,反序列化非常耗時;三是 Druid中實時任務狀态都通過ZK釋出,Overlord會監聽ZK上面的節點,而這些監聽器的回調線程執行函數中會涉及一些MySQL操作,當MySQL比較繁忙時, ZK watch回調單線程模型導緻事件處理需要排隊。
針對查詢性能瓶頸,我們主要針對Druid中繼資料存儲索引進行了優化。通過對Segment定時Merge,合理設定資料生命周期來合并精簡中繼資料; 對Druid資料庫連接配接池DBCP2參數進行優化。針對反序列化與watch回調問題,我們主要對Druid任務管理體系進行了較大修改,進行了Overlord Federation改造,引入namespace概念,每一個namespace下的任務又單獨的Overlord管理。這樣增加Overlord水準擴充能力,同時亦可做Overlord級别的資源隔離。
四、展望
目前Druid資料消費能力依賴Kafka topic的partition,未來我們希望引入流計算引擎提升單partition消費能力,解耦對Kafka topic partition的依賴,對資料消費和資料處理進行不同的并發度配置。其次,Overlord大量服務涉及對MySQL的直接操作,易導緻單機性能瓶頸,後續将會對高并發服務進行記憶體化改造。資料下推到HDFS之後,Coordinator(Druid裡資料配置設定角色)決定資料的加載位置,這是一個單線程運作模型,當Overload水準擴充之後,每個時間點産生的Segment數量會有很大提升,Coordinator任務處理單線程模型需要優化。最後, 我們希望把Druid部分元件On-yarn,進而提升資源使用率并簡化運維操作。
版權聲明:本文為CSDN部落客「weixin_34123613」的原創文章,遵循CC 4.0 BY-SA版權協定,轉載請附上原文出處連結及本聲明。
原文連結:https://blog.csdn.net/weixin_34123613/article/details/91894256