背景
在位元組跳動的實時計算場景中,我們有很多任務(數量 2k+)會直接服務于線上,其輸出時延和穩定性會直接影響線上産品的使用者體驗,這類任務通常具有如下特點:
- 流量大,并發高(最大的任務并行度超過 1w)
- 拓撲類似于多流 Join,将各個資料源做整合輸出給下遊,不依賴 Checkpoint
- 沒有使用 Checkpoint 并且對短時間内的小部分資料丢失不敏感(如 0.5%),但對資料輸出的持續性要求極高
在 Flink 現有的架構設計中,多流 Join 拓撲下單個 Task 失敗會導緻所有 Task 重新部署,耗時可能會持續幾分鐘,導緻作業的輸出斷流,這對于線上業務來說是不可接受的。
針對這一痛點,我們提出單點恢複的方案,通過對 network 層的增強,使得在機器下線或者 Task 失敗的情況下,以短時間内故障 Task 的部分資料丢失為代價,達成以下目标:
- 作業不發生全局重新開機,隻有故障 Task 發生 Failover
- 非故障 Task 不受影響,正常為線上提供服務
解決思路
當初遇到這些問題的時候,我們提出的想法是說能不能在機器故障下線的時候,隻讓在這台機器上的 Tasks 進行 Failover,而這些 Tasks 的上下遊 Tasks 能恰好感覺到這些失敗的 Tasks,并作出對應的措施:
- 上遊:将原本輸出到 Failed Tasks 的資料直接丢棄,等待 Failover 完成後再開始發送資料。
- 下遊:清空 Failed Tasks 産生的不完整資料,等待 Failover 完成後再重建立立連接配接并接受資料
根據這些想法我們思考得出幾個比較關鍵點在于:
- 如何讓上下遊感覺 Task Failed ?
- 如何清空下遊不完整的資料 ?
- Failover 完成後如何與上下遊重建立立連接配接 ?
基于以上考慮我們決定基于已有的 Network 層線程模型,修改上下遊對于 Task Failed 後的處理邏輯,讓非故障的 Tasks 短時間内完成對失敗 Task 的感覺操作,進而使得作業持續穩定地輸出。
目前架構
注:我們的實作基于 Flink-1.9,1.11 後的網絡模型加入了 Unaligned Checkpoint 的特性,可能會有所變化。
我們先将 Flink 的上下遊 Task 通信模型簡單抽象一下:
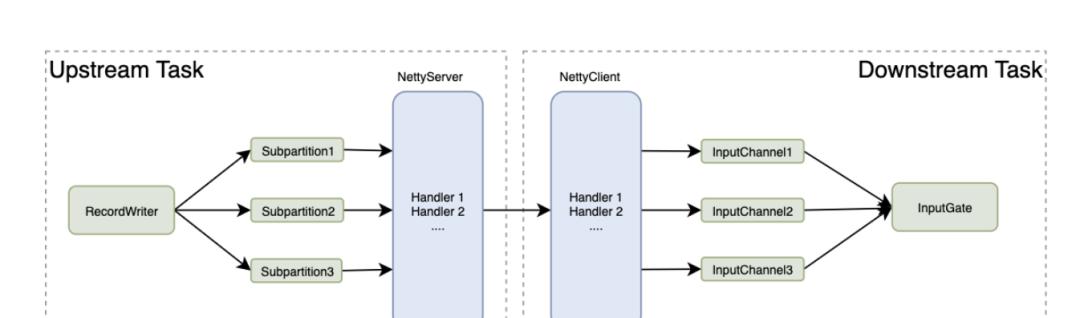
Figure. 上下遊通信模型
上下遊 Task 感覺彼此狀态的邏輯,分三種情況考慮:
- Task 因為邏輯錯誤或 OOM 等原因 Fail,Task 自身會主動釋放 network resources,給上遊發送 channel close 資訊,給下遊發送 Exception。
- TaskManager 程序被 Yarn Kill,TCP 連接配接會被作業系統正常關閉,上遊 Netty Server 和下遊 Netty Client 可以感覺到連接配接狀态變化。
- 機器斷電當機,這個情況下作業系統不會正确關閉 TCP 連接配接,是以 Netty 的 Server 和 Client 可能互相感覺不到,這個時候我們在 deploy 新的 Task 後需要做一些強制更新的處理。
可以看到,在大部分情況下,Task 是可以直接感覺到上下遊 Task 的狀态變化。了解了基礎的通信模型之後,我們可以按照之前的解決思路繼續深入一下,分别在上遊發送端和下遊接收端可以做什麼樣改進來實作單點恢複。
優化方案
根據我們的解決思路,我們來繪制一下單個 Task 挂了之後,整個 Job 的通信流程:

Figure. 單點恢複流程
Map(1) 失敗之後:
- 将 Map(1) 失敗的資訊通知 Source(1) 、Sink(1) 和 JobManager。
- JobManager 開始申請新的資源準備 Failover,同時上遊 Source(1) 和下遊 Sink(1) 切斷和 Map(1) 的資料通道,但是 Source(1) 和 Sink(1) 和其他 Task 的資料傳輸仍正常進行。
- Map(1)' 被成功排程,和上遊建立連接配接,JobManager 通知 Sink(1) 和 Map(1)' 建立連接配接,資料傳輸通道被恢複。
從這個流程,我們可以将優化分為三個子產品,分别為上遊發送端、下遊接收端和 JobManager。
上遊發送端的優化
我們再細化一下上遊發送端的相關細節,
Figure. 上遊資料發送流程
(1) Netty Server 收到 Client 發送的 Partition Request 後,在對應的 Subpartition 注冊讀取資料的 SubpartitionView 和 Reader。
(2) RecordWriter 發送資料到不同的 Subpartitions,每個 Subpartition 内部維護一個 buffer 隊列,并将讀取資料的 Reader 放入到 Readers Queue 中。(Task 線程)
(3) Netty 線程讀取 Readers Queue,取出對應的 Reader 并讀取對應 Subpartition 中的 buffer 資料,發送給下遊。(Netty 線程)
我們的期望是上遊發送端在感覺到下遊 Task 失敗之後,直接将發送到對應 Task 的資料丢棄。那麼我們的改動邏輯,在這個示意圖中,就是 Subpartition 通過 Netty Server 收到下遊 Task Fail 的消息後,将自己設定為 Unavailable,然後 RecordWriter 在發送資料到指定 Subpartition 時,判斷是否可用,如果不可用則直接将資料丢棄。而當 Task Failover 完成後重新與上遊建立連接配接後,再将該 Subpartition 置為 Available,則資料可以重新被消費。
發送端的改動比較簡單,得益于 Flink 内部對 Subpartition 的邏輯做了很好的抽象,并且可以很容易的通過參數來切換 Subpartition 初始化的類型,我們在這裡參考 PipelinedSubpartition 的實作,根據上述的邏輯,實作了我們自己的 Subpartition 和對應的 View。
下遊接收端的優化
同樣,我們來細化一下下遊接收端的細節:
Figure. 下遊資料接收流程
仔細來看,其實和上遊的線程模型頗有類似之處:
(1) InputGate 初始化所有的 Channel 并通過 Netty Client 和上遊 Server 建立連接配接。
(2) InputChannel 接收到資料後,緩存到 buffer 隊列中并将自己的引用放入到 Channels Queue 裡。(Netty 線程)
(3) InputGate 通過 InputProcessor 的調用,從 Queue 裡拉取 Channel 并讀取 Channel 中緩存的 buffer 資料,如果 buffer 不完整(比如隻有半條 record),那麼則會将不完整的 buffer 暫存到 InputProcessor 中。(Task 線程)
這裡我們期望下遊接收端感覺到上遊 Task 失敗之後,能将對應 InputChannel 的接收到的不完整的 buffer 直接清除。不完整的 buffer 存儲在 InputProcessor 中,那麼我們如何讓 InputProcessor 知道哪個 Channel 出現了問題?
簡單的方案是說,我們在 InputChannel 中直接調用 InputGate 或者 InputProcessor,做 buffer 清空的操作,但是這樣引入一個問題,由于 InputChannel 收到 Error 是在 Netty 線程,而 InputProcessor 的操作是在 Task 線程,這樣跨線程的調用打破了已有的線程模型,必然會引入鎖和調用時間的不确定性,增加架構設計的複雜度,并且因為 InputProcessor 會對每一條 record 都有調用,稍有不慎就會帶來性能的下降。
我們沿用已有的線程模型,Client 感覺到上遊 Task 失敗的消息之後告知對應的 Channel,Channel 向自己維護的 receivedBuffers 的末尾插入一個 UnavailableEvent,并等待 InputProcessor 拉取并清空對應 Channel 的 buffer 資料。示意圖如下所示,紅色的子產品是我們新增的部分:
Figure. 下遊改動示意圖
JobManager 重新開機政策的優化
JobManager 重新開機政策可以參考社群已有的 RestartIndividualStrategy,比較重要的差別是,在重新 deploy 這個失敗的 Task 後,我們需要通過 ExecutionGraph 中的拓撲資訊,找到該 Task 的下遊 Tasks,并通過 Rpc 調用讓下遊 Tasks 和這個新的上遊 Tasks 重建立立連接配接。
這裡實作有一個難點是如果 JobManager 去 update 下遊的 Channel 資訊時,舊的 Channel 對應的 buffer 資料還沒有被清除怎麼辦?我們這裡通過新增 CachedChannelProvider 來處理這一邏輯:
Figure. 更新 Partition
如圖所示,以 Channel - 1 為例,如果 JobManager 更新 Channel 的 Rpc 請求到來時 Channel 處于不可用狀态,那麼我們直接利用 Rpc 請求中攜帶的 Channel 資訊來重新初始化 Channel。以 Channel - 3 為例,如果 Rpc 請求到來時 Channel 仍然可用,那麼我們将 Channel 資訊暫時緩存起來,等 Channel - 3 中所有資料消費完畢後,通知 CachedChannelProvider,然後再通過 CachedChannelProvider 去更新 Channel。
這裡還需要特别提到一點,在位元組跳動内部我們實作了預留 TaskManager 的功能,當 Task 出現 Failover 時,能夠直接使用 TaskManager 的資源,大大節約了 Failover 過程資料丢失的損耗。
實作中的關鍵點
整個解決的思路其實是比較清晰的,相信大家也比較容易了解,但是在實作中仍然有很多需要注意的地方,舉例如下:
- 上面提到 JobManager 發送的 Rpc 請求如果過早,那麼會暫時緩存下來等待 Channel 資料消費完成。而此時作業的狀态是未知的,可能一直處于僵死的狀态(比如卡在了網絡 IO 或者 磁盤 IO 上),那麼 Channel 中的 Unavailable Event 就無法被 InputProcessor 消費。這個時候我們通過設定一個定時器來做兜底政策,如果沒有在定時器設定的時間内完成 Channel 的重新初始化,那麼該 Task 就會自動下線,走單點恢複的 Failover 流程。
- 網絡層作為 Flink 内線程模型最複雜的一個子產品,我們為了減少改動的複雜度和改動的風險,在設計上沒有新增或修改 Netty 線程和 Task 線程之間通信的模型,而是借助于已有的線程模型來實作單點恢複的功能。但在實作過程中因為給 Subpartition 和 Channel 增加了類似 isAvailable 的狀态位,是以在這些狀态的修改上需要特别注意線程可見性的處理,避免多線程讀取狀态不一緻的情況發生。
收益
目前在位元組跳動内部,單點恢複功能已經上線了 1000+ 作業,在機器下線、網絡抖動的情況下,下遊在上遊作業做 Failover 的過程幾乎沒有感覺。
接下來我們以下面這個作業拓撲為例,在作業正常運作時我們手動 Kill 一個 Container,來看看不同并行度作業開啟單點恢複的效果:
Figure. 測試作業拓撲
我們在 1000 和 4000 并行度的作業上進行測試,每個 slot 中有 2 個 Source 和 1 個 Joiner 共 3 個 Task,手動 Kill 一個 Container 後,從故障恢複時間和斷流影響兩個次元進行收益計算:
結論: 可以看到,在 4000 個 Slot 的作業裡,如果不開啟單點恢複,作業整體的 Failover 時間為 81s,同時對于下遊服務來說,上遊服務斷流 81s,這在實時服務線上的場景中明顯是不可接受的。而開啟了單點恢複和預留資源後,Kill 1 個 Container 隻會影響 4 個 Slot,且 Failover 的時間隻有 5s,同時對于下遊服務來說,上遊服務産生的資料減少 4/4000=千分之一,持續 5s,效果是非常顯而易見的。
版權聲明:本文為部落客轉載文章,遵循<a href="http://creativecommons.org/licenses/by-sa/4.0/" target="_blank" rel="external nofollow" target="_blank" rel="noopener"> CC 4.0 BY-SA </a>版權協定,轉載請附上原文出處連結和原文聲明。
原文連結:https://blog.csdn.net/ByteDanceTech/article/details/108722605