文章目錄
- 執行個體化
-
- 通過執行個體化修改渲染流程
- 視錐體裁剪
-
- 修改MiniEngine中Frustum為左手坐标系
- 通過一個常量緩沖區實作裁剪
- release幀率對比
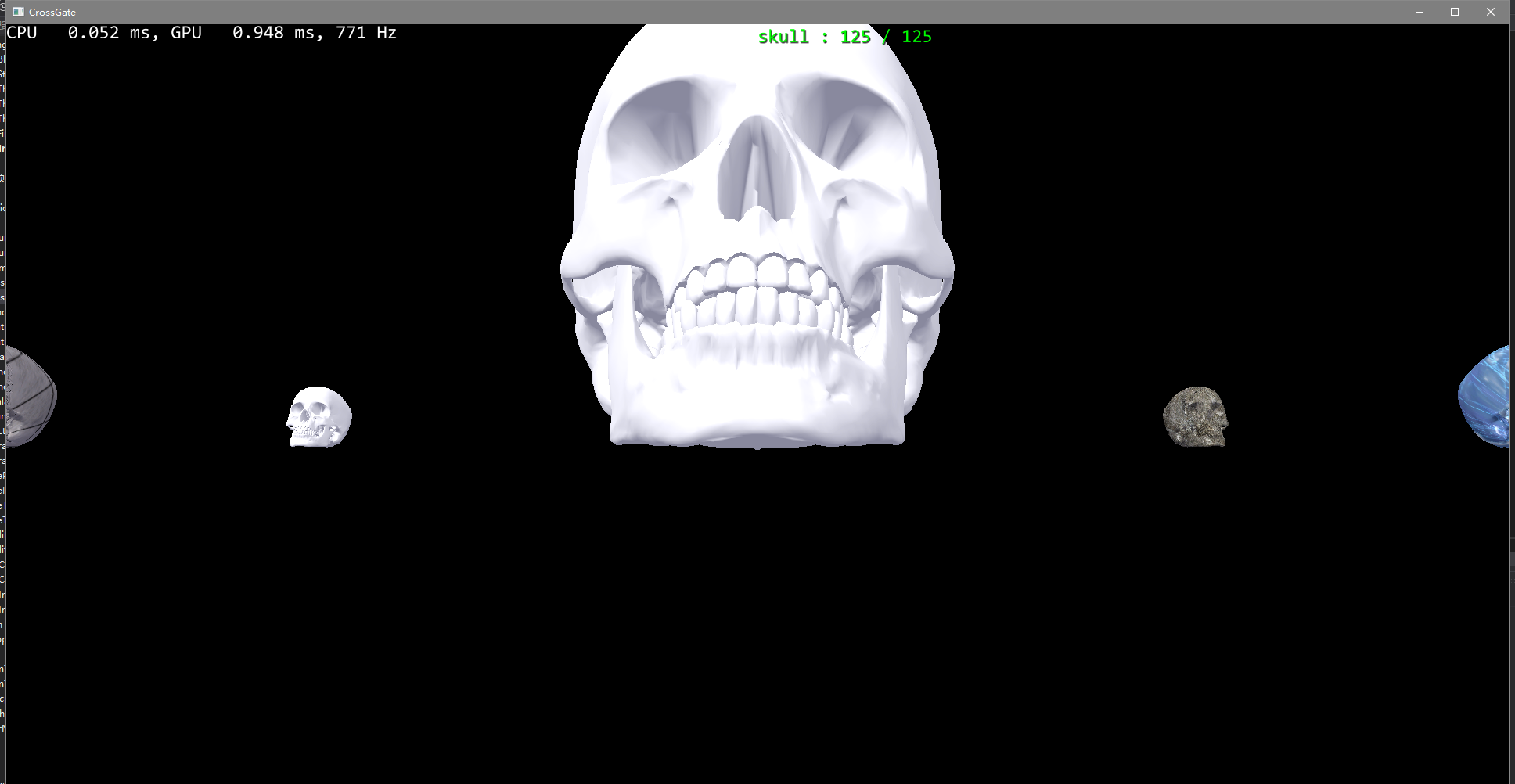
執行個體化
執行個體化實際上就是通過一套頂點和索引,繪制多個物體。
可以為物體設定不同的轉換矩陣,紋理等所需屬性。
簡單流程如下:
- 緩沖區寫入每個渲染目标的的矩陣參數
- 緩沖區寫入每個渲染目标的紋理屬性以及紋理ID
- 緩沖區寫入所需的紋理
那麼通過執行個體化隻需要一次DrawCall就可以把這些目标全部渲染。
通過執行個體化修改渲染流程
在上一篇部落格動态索引中,實際上已經把紋理屬性和紋理都寫入了緩沖區。
渲染流程如下:
- 每個渲染目标有自己獨立的常量資料
- shader中根據頂點的常量資料去拿紋理資料以及對應紋理
在這裡,采用執行個體化的方式,通過shader中的SV_InstanceID參數,我們可以确定目前繪制的是第幾個執行個體化目标。
把每個渲染目标的資料也提前一次性寫入緩沖區。
整體非常的簡單,也沒有什麼坑,這裡就不再細說了。
github:
https://github.com/mversace/DirectX12-MiniEngine-Dragon/tree/63d3490e0cccedd2a01fc5402c53ce9a208252b0
視錐體裁剪
這個的意思就是,利用CPU根據目前的錄影機計算出可以看到的視錐體,然後把與視錐體不相交的渲染目标剔除出渲染隊列。
這可以有效的減少shader運算的負擔。否則的話,渲染流水線依舊會送出這些頂點,直到經過幾何着色階段之後,開始裁剪時才會去除目标,而這會帶來大量的計算開銷。
CPU提前進行視錐體裁剪就是CPU多計算一點,來提高整體的運作效率。
修改MiniEngine中Frustum為左手坐标系
MiniEngine中在Camera類中本身有剔除類Frustum(被删掉了,這次加回來)
我們需要修改Frustum這個類中構造透視視錐體的代碼,來比對左手坐标系
void Frustum::ConstructPerspectiveFrustum( float HTan, float VTan, float NearClip, float FarClip )
{
// 已改為左手坐标系
const float NearX = HTan * NearClip;
const float NearY = VTan * NearClip;
const float FarX = HTan * FarClip;
const float FarY = VTan * FarClip;
// 視錐體,計算近遠兩個面的4個頂點
m_FrustumCorners[ kNearLowerLeft ] = Vector3(-NearX, -NearY, NearClip); // Near lower left
m_FrustumCorners[ kNearUpperLeft ] = Vector3(-NearX, NearY, NearClip); // Near upper left
m_FrustumCorners[ kNearLowerRight ] = Vector3( NearX, -NearY, NearClip); // Near lower right
m_FrustumCorners[ kNearUpperRight ] = Vector3( NearX, NearY, NearClip); // Near upper right
m_FrustumCorners[ kFarLowerLeft ] = Vector3( -FarX, -FarY, FarClip); // Far lower left
m_FrustumCorners[ kFarUpperLeft ] = Vector3( -FarX, FarY, FarClip); // Far upper left
m_FrustumCorners[ kFarLowerRight ] = Vector3( FarX, -FarY, FarClip); // Far lower right
m_FrustumCorners[ kFarUpperRight ] = Vector3( FarX, FarY, FarClip); // Far upper right
const float NHx = RecipSqrt( 1.0f + HTan * HTan );
const float NHz = NHx * HTan;
const float NVy = RecipSqrt( 1.0f + VTan * VTan );
const float NVz = NVy * VTan;
// 計算視錐體的6個面,存儲的是法向量以及面上的一個點
m_FrustumPlanes[kNearPlane] = BoundingPlane( 0.0f, 0.0f, 1.0f, NearClip );
m_FrustumPlanes[kFarPlane] = BoundingPlane( 0.0f, 0.0f, -1.0f, FarClip );
m_FrustumPlanes[kLeftPlane] = BoundingPlane( NHx, 0.0f, NHz, 0.0f );
m_FrustumPlanes[kRightPlane] = BoundingPlane( -NHx, 0.0f, NHz, 0.0f );
m_FrustumPlanes[kTopPlane] = BoundingPlane( 0.0f, -NVy, NVz, 0.0f );
m_FrustumPlanes[kBottomPlane] = BoundingPlane( 0.0f, NVy, NVz, 0.0f );
}
還有點修改,詳見log記錄。
MiniEngine中設計的還是比較巧妙的,原版本是Camera中的矩陣存儲了錄影機深度比例。我們後來修改後采用了dx的api,這個比例就沒有了,是以給Frustum的構造函數額外傳一個參數提供這個比例,以生成正确的視錐體。
通過一個常量緩沖區實作裁剪
龍書中是設定了一個上傳緩沖區,動态的将渲染目标的一些參數拷貝進去。拷貝的量有點大,我這裡采用另外一種方式來實作。
- 設定一個常量緩沖區,隻記錄可視目标的idx
- shader中根據這個idx來取值
這種方式,對于每次拷貝的資料量稍微小點。
這個稍微改下就可以了。
有個點需要注意,shader中的數組,數組中的每個值都會至少配置設定float4的空間(vs2019圖像調試經常崩潰無法定位,研究了很久才找到問題)
是以我們傳入的資料要适配這種格式。
cbuffer cbPass1 : register(b1)
{
int gDrawObjs[128]; // 數組中的每個元素都會被封裝為float4,d3d12龍書727頁
};
相應的修改C++中渲染目标之類的結構體,稍微調整下。
release幀率對比
debug下不明顯,release下效率差距極大