pandas作為python進行資料分析的常用第三方庫,它是基于numpy建立的,使得運用numpy的程式也能更好地使用pandas。
1 pandas資料結構
1.1 Series
注:由于pandas與numpy關系密切,是以在代碼中經常将二者一同導入使用。
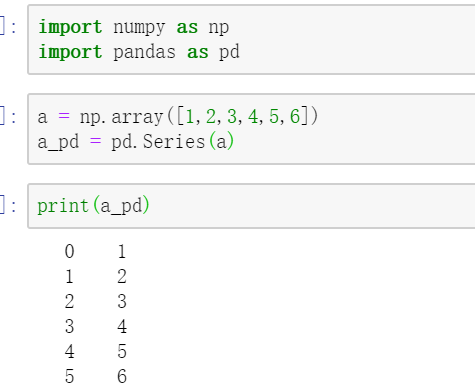
上圖中,先利用numpy建立一個一維數組,再利用pandas的内置方法将其轉換為pandas的序列類型Series。可以看到,pandas會自動将原有資料轉換成一列,并添加行的索引。
1.2 DataFrame
pandas的第二種也是最具代表性的資料結構就是DataFrame。

顯然,DataFrame就是矩陣類型的資料,隻不過pandas中會給矩陣添加行列索引,以便使用與查找元素。
2 建立DataFrame
由于Series可以視為DataFrame的一種簡單情況,是以後面将主要介紹DataFrame,關于Series的情況可以類比過去。
從前一小節可以看到,pandas的資料可以通過運用内置方法轉換numpy建立的資料得到,但也可以直接在pandas庫内建立DataFrame。
建立DataFrame時,可以手動給資料添加行列名,否則pandas會自動添加形如“0,1,2,3”的行列名。
由于pandas基于numpy制作,是以numpy中的一些常用方法可以直接移植過來。
pandas中也有shape方法檢視矩陣大小。
3 查找DataFrame的元素
因為pandas中的矩陣允許自定義行列名,是以定位其中的元素分為如下幾種方式:使用行列名稱,使用行列位置,名稱位置混合。
3.1 行列名稱定位
3.2 行列位置定位
3.3 名稱位置混合定位
一般常用的還是前兩種定位手段,混合定位了解即可。
小結:作為pandas系列的開篇,本文就介紹到此,沿用numpy系列的模式,後面的博文将介紹pandas中關于DataFrame的常用方法。