第一篇文章,就從一個簡單爬蟲開始吧。 這隻蟲子的功能很簡單,抓取到”煎蛋網xxoo”網頁(http://jandan.net/ooxx/page-1537),解析出其中的妹子圖,儲存至本地。
先放結果:
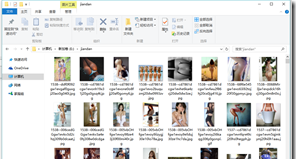
從程式來講,分為三個步驟:
1、發起一個http請求,擷取傳回的response内容;
2、解析内容,分離出有效圖檔的url;
3、根據這些圖檔的url,生成圖檔儲存至本地。
開始詳細說明:
準備工作:HttpClient的Jar包,通路http://hc.apache.org/ 自行下載下傳。
主程式内容:
public class SimpleSpider {
//起始頁碼
private static final int page = 1538;
public static void main(String[] args) {
//HttpClient 逾時配置
RequestConfig globalConfig = RequestConfig.custom().setCookieSpec(CookieSpecs.STANDARD).setConnectionRequestTimeout(6000).setConnectTimeout(6000).build();
CloseableHttpClient httpClient = HttpClients.custom().setDefaultRequestConfig(globalConfig).build();
System.out.println("5秒後開始抓取煎蛋妹子圖……");
for (int i = page; i > 0; i--) {
//建立一個GET請求
HttpGet httpGet = new HttpGet("http://jandan.net/ooxx/page-" + i);
httpGet.addHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.152 Safari/537.36");
httpGet.addHeader("Cookie","_gat=1; nsfw-click-load=off; gif-click-load=on; _ga=GA1.2.1861846600.1423061484");
try {
//不敢爬太快
Thread.sleep(5000);
//發送請求,并執行
CloseableHttpResponse response = httpClient.execute(httpGet);
InputStream in = response.getEntity().getContent();
String html = Utils.convertStreamToString(in);
//網頁内容解析
new Thread(new JianDanHtmlParser(html, i)).start();
} catch (Exception e) {
e.printStackTrace();
}
}
}
} HttpClient是一個非常強大的工具,屬于apache下項目。如果隻是建立一個預設的httpClient執行個體,代碼很簡單,官網手冊上有詳細說明。
可以看到在建立一個GET請求時,加入了請求頭。第一個User-Agent代表所使用浏覽器。有些網站需要明确了解使用者所使用的浏覽器,而有些不需要。個人猜測,部分網站根據使用者使用浏覽器不同顯示不一樣。這裡的煎蛋網,就必須得加入請求頭。第二個Cookie則代表了一些使用者設定,可以沒有。使用chrome的開發者工具就能清楚看到。如果是https加密後的,則需要特殊的抓包工具。

網頁内容解析
public class JianDanHtmlParser implements Runnable {
private String html;
private int page;
public JianDanHtmlParser(String html,int page) {
this.html = html;
this.page = page;
}
@Override
public void run() {
System.out.println("==========第"+page+"頁============");
List<String> list = new ArrayList<String>();
html = html.substring(html.indexOf("commentlist"));
String[] images = html.split("li>");
for (String image : images) {
String[] ss = image.split("br");
for (String s : ss) {
if (s.indexOf("<img src=") > 0) {
try{
int i = s.indexOf("<img src=\"") + "<img src=\"".length();
list.add(s.substring(i, s.indexOf("\"", i + 1)));
}catch (Exception e) {
System.out.println(s);
}
}
}
}
for(String imageUrl : list){
if(imageUrl.indexOf("sina")>0){
new Thread(new JianDanImageCreator(imageUrl,page)).start();
}
}
}
} 這段代碼看起來淩亂,但實際上卻特别簡單。簡單說便是,将response傳回的html字元串解析,截取,找到真正需要的内容(圖檔url),存入到臨時容器中。
生成圖檔類
public class JianDanImageCreator implements Runnable {
private static int count = 0;
private String imageUrl;
private int page;
//存儲路徑,自定義
private static final String basePath = "E:/jiandan";
public JianDanImageCreator(String imageUrl,int page) {
this.imageUrl = imageUrl;
this.page = page;
}
@Override
public void run() {
File dir = new File(basePath);
if(!dir.exists()){
dir.mkdirs();
System.out.println("圖檔存放于"+basePath+"目錄下");
}
String imageName = imageUrl.substring(imageUrl.lastIndexOf("/")+1);
try {
File file = new File( basePath+"/"+page+"--"+imageName);
OutputStream os = new FileOutputStream(file);
//建立一個url對象
URL url = new URL(imageUrl);
InputStream is = url.openStream();
byte[] buff = new byte[1024];
while(true) {
int readed = is.read(buff);
if(readed == -1) {
break;
}
byte[] temp = new byte[readed];
System.arraycopy(buff, 0, temp, 0, readed);
//寫入檔案
os.write(temp);
}
System.out.println("第"+(count++)+"張妹子:"+file.getAbsolutePath());
is.close();
os.close();
} catch (Exception e) {
e.printStackTrace();
}
}
} 根據每個圖檔的src位址建立一個URL對象,再使用位元組流,生成本地檔案。
這個程式相對來說比較簡單,純屬娛樂。如果能讓那些不了解HttpClient的同學對這個庫産生興趣,則功德無量。
github位址:https://github.com/nbsa/SimpleSpider
PS:這個部落格隻提供抓取圖檔的方法,圖檔版權屬于原網站及其網友。請大家尊重原網勞動成果,避免分發、傳播圖檔内容。
轉載于:https://www.cnblogs.com/nbspL/p/4780792.html