文章目錄
- PaddleHub創意賽:AI人像摳圖及圖像合成
- 一、安裝環境(這裡面有幾個坑)
- 二、接下來就``開始P圖
- 1. 引入包
- 2. 加載預訓練模型(挺厲害的不得不說)
- 3. 圖像合成
PaddleHub創意賽:AI人像摳圖及圖像合成
本項目根據DeepLabv3+模型一鍵摳圖示例,主要采用PaddleHub DeepLabv3+模型(deeplabv3p_xception65_humanseg)和python圖像處理庫opencv、PIL等完成。在最新作中,作者通過encoder-decoder進行多尺度資訊的融合,同時保留了原來的空洞卷積和ASSP層, 其骨幹網絡使用了Xception模型,提高了語義分割的健壯性和運作速率,在 PASCAL VOC 2012 dataset取得新的state-of-art performance,該PaddleHub Module使用百度自建資料集進行訓練,可用于人像分割,支援任意大小的圖檔輸入。在完成一鍵摳圖之後,通過圖像合成,實作扣圖比賽任務。
PaddleHub 是基于 PaddlePaddle 開發的預訓練模型管理工具,可以借助預訓練模型更便捷地開展遷移學習工作,目前的預訓練模型涵蓋了圖像分類、目标檢測、詞法分析、語義模型、情感分析、視訊分類、圖像生成、圖像分割、文本稽核、關鍵點檢測等主流模型。
PaddleHub官網:PaddleHub官網
PaddleHub項目位址:PaddleHub github
更多PaddleHub預訓練模型應用可見:教程合集課程
NOTE: 如果您在本地運作該項目示例,需要首先安裝PaddleHub。如果您線上運作,需要首先fork該項目示例。之後按照該示例操作即可。
一、安裝環境(這裡面有幾個坑)
!pip install paddlehub==1.6.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
!hub install deeplabv3p_xception65_humanseg==1.0.0 雖然說這樣就可以了,但是你會發現,你打開本地運作環境以後會出錯???
以下為出錯的内容
JSONDecodeError("Expecting value", s, err.value) from None json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0) 既然如此我們就進源碼看一下到底怎麼回事
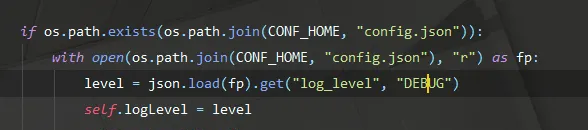
最主要就是這個東西出了問題,在Github上的issue裡面說了,在最新版裡面已經解決,但其實在windows裡面,仍然存在該類問題
然後分析代碼後我得知,原來在C槽當中,缺失了config.json檔案,然後把這個放到這個根目錄的檔案裡面去.paddle/conf/config.json,如果沒有就自己建立一個
{
"server_url": [
"http://paddlepaddle.org.cn/paddlehub"
],
"resource_storage_server_url": "https://bj.bcebos.com/paddlehub-data/",
"debug": false,
"log_level": "DEBUG"
} 然後還有一個坑就是,虛拟環境裡面運作可能會出錯,是以最好在Pycharm真實環境運作
二、接下來就``開始P圖
1. 引入包
# 測試圖檔路徑和輸出路徑
test_path = 'image/test/'
output_path = 'image/out/'
# 待預測圖檔
test_img_path = ["test.jpg"]
test_img_path = [test_path + img for img in test_img_path]
img = mpimg.imread(test_img_path[0])
# 展示待預測圖檔
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.axis('off')
plt.show() 這是效果圖!!

2. 加載預訓練模型(挺厲害的不得不說)
通過加載PaddleHub DeepLabv3+模型(deeplabv3p_xception65_humanseg)實作一鍵摳圖
module = hub.Module(name="deeplabv3p_xception65_humanseg")
input_dict = {"image": test_img_path}
# execute predict and print the result
results = module.segmentation(data=input_dict)
for result in results:
print(result)
# 預測結果展示
out_img_path = 'humanseg_output/' + os.path.basename(test_img_path[0]).split('.')[0] + '.png'
img = mpimg.imread(out_img_path)
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.axis('off')
plt.show() 測試結果還挺不錯的!!!但是在處理其他圖檔還有瑕疵,比如手裡拿了手機,可能會給你P調
3. 圖像合成
# 合成函數
def blend_images(fore_image, base_image, output_path):
"""
将摳出的人物圖像換背景
fore_image: 前景圖檔,摳出的人物圖檔
base_image: 背景圖檔
"""
# 讀入圖檔
base_image = Image.open(base_image).convert('RGB')
fore_image = Image.open(fore_image).resize(base_image.size)
# 圖檔權重合成
scope_map = np.array(fore_image)[:,:,-1] / 255
scope_map = scope_map[:,:,np.newaxis]
scope_map = np.repeat(scope_map, repeats=3, axis=2)
res_image = np.multiply(scope_map, np.array(fore_image)[:,:,:3]) + np.multiply((1-scope_map), np.array(base_image))
#儲存圖檔
res_image = Image.fromarray(np.uint8(res_image))
res_image.save(output_path)
return res_image
output_path_img = output_path + 'blend_res_img.jpg'
blend_images('humanseg_output/test.png', 'image/test/bg.jpg', output_path_img)
# 展示合成圖檔
plt.figure(figsize=(10,10))
img = mpimg.imread(output_path_img)
plt.imshow(img)
plt.axis('off')
plt.show()