作者veezean
說到監控告警平台,大家應該都不會陌生,對于線上系統而言可以說是個标配,各個公司或項目也都會有搭建自己的監控告警平台的實際訴求。
目前比較主流的監控告警平台實作方案,很多都是基于
Prometheus + Grafana + AlertManager
來實作的。但是實際使用的時候會發現不易實施:
- 在運維部署對接方面存在一些不便,接入新的被監控節點時需要到平台部署機器上去修改配置檔案、甚至重新開機服務來生效
- 配置告警規則等也是基于xml配置,必須要到平台伺服器上去添加檔案,對于一個各項目通用的平台而言,顯然不可能将後端服務位址暴露讓各業務負責人員去自行修改伺服器上的配置檔案
-
Grafana
Grafana
前段時間研究了下基于
Prometheus
建構監控系統相關的概念,并以此為基準設計了一個企業級通用的監控告警平台的方案。這裡分享一下架構的分析過程以及上述問題的解決思路。
平台與業務職責規劃
既然是建構通用平台,就會涉及到平台與業務的職責劃分的問題,這條線究竟按照什麼尺度去畫,究竟将平台做厚還是做薄,将直接決定了平台的整體定位:
- 平台做的太厚重,勢必導緻業務使用的限制增加、且定制化能力減弱,适用範圍受限;
- 平台做的太輕薄,業務雖然有更多的主導權與定制靈活度,但也導緻各個業務需要重複建構相關能力,平台将失去意義。
從建構通用平台的角度而言,很明顯
厚平台
方案更具優勢,可以統一整個公司各個業務的監控水準、可以持續的彙聚能力、積累沉澱。
是以,最終選擇采用
厚平台
模式來建構:
- 內建資料存儲、統計、告警政策、告警推送等能力,業務僅負責埋點資料上報即可。
- 告警能力擴充性強,全業務無差别共享
- 業務接入簡單,但平台實作工作量較大
- 業務可以有限定制,但是需要基于管理界面上去配置規則,受平台規則支援度限制
使用者場景訴求分析
先分析下對監控平台的一個整體的訴求情況、以及監控平台需要支援的一些核心業務場景。
從使用者角度,收集下不同角色的人員的訴求:
管理人員:
- 掌控全局整體情況
- 可以按照不同次元檢視(比如按照部門、按照項目、按照負責人等次元進行檢視)
開發人員:
- 知曉自己負責的項目的狀态
- 若有異常能第一時間收到告警通知
- 可定制自己項目的告警規則與告警接收人員
運維人員:
- 檢視負責的所有機器情況
- 部署接入簡單
- 中間件可以一鍵接入,不要有額外的部署安裝操作
- 監控平台自身的穩定與可靠
總結下來,使用者層面對系統的訴求點主要有:
能用:能檢視整體情況、能劃分權限控制、能接收告警
易用:業務接入簡單、友善自定義規則
選型與整體設計
作為監控平台,目前主流的一個方案就是
Prometheus + Grafana + AlertManager
的配套,本次方案也使用此正常配套。
關鍵設計點:
- 由于
prometheus
prometheus
- 考慮到
prometheus
rest
prometheus
- 通常
Prometheus
最終整體建構的全貌圖如上所示,橙色的部分為使用開源元件實作,綠色部分為自行建構,作為輔助能力,打通平台的輔助操控能力,降低使用者的使用門檻。
關鍵點設計
監控平台管理界面方案
作為與使用者層面打交道的門面,管理界面端的實作既要承載使用者次元的基本使用訴求,更是解決前述說的
Prometheus + Grafana + AlertManager
使用配置與規則定制門檻過高的關鍵一環。
基于
Prometheus
建構的監控平台中,很多都是标配了
Grafana
作為界面展示。但是
Grafana
作為通用開源元件,側重點在
dashboard
展示能力上,其餘一些管理能力較為弱化。
是以在界面的規劃上,采用的政策是繼續以現有的運維平台界面為主,設計整合
grafana
的
dashboard
展示能力。也即對使用者而言,入口都是運維平台Poral,一些規則配置、部署操作等統一由運維平台portal提供,隻是點選檢視某個項目的資料時,跳轉到
Grafana
展示。
分層、分組告警實作機制
作為一個監控告警平台,告警能力自然是最關鍵的一個部分。此部分使用
Prometheus
已有能力。
具體實施時,為了實作告警的按需推送、精準推送,規劃在
Prometheus
配置采集探針資料的時候,為每個探針配置對應的标簽資料,比如項目組、系統、子產品、環境類型等等資訊。這樣就可以進一步按照項目組或者系統次元進行推送給相關人員。
此處規劃是在
prometheus
拉取探針服務的地方進行配置追加強定分組tag資訊,而不是由各個探針的名額項中自己上報,主要也是從平台統一控制次元進行考量。
對接告警通道設計
Prometheus實作告警有2種可選方案:
- 對接
Prometheus AlarmManager
- 對接
Grafana
Grafana
Grafana
其實,不管是
Prometheus AlertManager
還是
Grafana
,其配置都需要遵循一定的規則,對于沒接觸過的人而言,還是有一定的使用門檻的,而且兩種配置起來都很不友善,尤其是
AlertManager
,還得登入部署伺服器上去新增或修改配置檔案 —— 這個作為一個平台,顯然是不可接受的。
是以,從功能與便捷性角度考慮,標明使用
AlertManager
實作告警能力。作為對其弊端的補償,規劃建構管理配置服務,并在平台統一Portal上提供無門檻易用的配置能力,如下:
使用者通過界面上配置好之後,變更的配置檔案經由管理配置服務中轉,自動寫入
AlertManager
對應配置檔案中,由此避免人為修改
AlertManager
服務端配置檔案可能引發的問題。
AlarmManage預置的告警通道主要有郵箱、釘釘、企業微信、或者
webhook
等。出于可自由定制、以及後續可自由定制的角度觸發,此處選擇采用
webhook
的方式:
- 新開發一個
webhook
- 對接收到的告警資訊進行處理後,調用目前監控平台提供的微信告警推送接口,推送給使用者。
部署與運維管理政策
基于
Prometheus
的機制,資料上報采用探針的方式暴露相關接口,然後
Prometheus
定時輪詢拉取。
對于探針的部署,考慮可選
正常模式
與
集中模式
兩種。
正常模式:
各業務、各中間件節點自行部署自己的探針服務。
集中模式:
各中間件的探針服務集中部署,打通web端配置邏輯,根據自動部署探針服務。
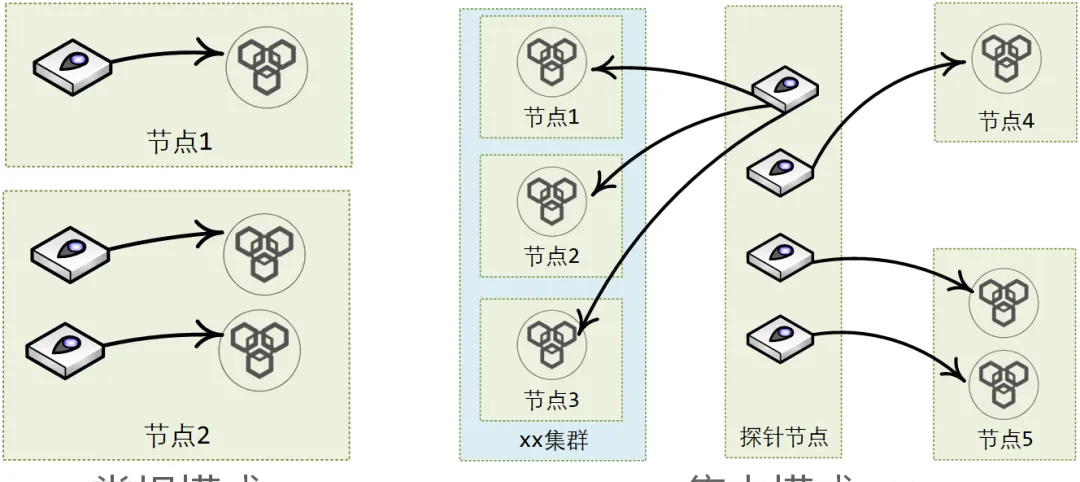
從實施工作量上進行評估,最終敲定混合使用兩種模式:
- 中間件監控,采用集中部署,作為平台能力一部分,集中監管。
- 各業務監控,采用正常模式,各個業務自行定制提供探針服務并部署。
關于中間探針集中部署:
- 将各常見中間件的exporter包安裝到伺服器上
- 根據web傳過來的被監控中間件的類型
- 執行指令,z啟動對應探針
- 為了後續可維護,将啟動指令寫入腳本檔案中,設定開機自啟動
- 相關配置資訊、每個exporter綁定的port資訊以及監控的中間件資訊,儲存到DB中,便于維護。
高可用設計
作為一個用來監控其他服務是否正常的告警平台,其自身的高可用性顯然是必須要考慮的事情。一旦監控平台挂掉,業務出問題可能就無法第一時間通知到責任人,很容易引發線上事故。
對整個平台的高可用設計,采用分子產品不同的政策:
Prometheus
高可用:冗備方案。部署2套
prometheus
程序,兩套
prometheus
采集相同的探針節點,擁有完全相同的配置資料。
可擴充:分片政策。當監控對象數量太多時,将監控對象分片,每個分片部署一套(2個程序)
prometheus
服務,實作水準無限制擴充。
AlarmManager
高可用、可擴充:叢集部署。多個
prometheus
程序發送到
AlarmManager Cluster
中的重複告警資訊,最終隻會有1條告警會被發送出去。
配置部署服務
高可用、可擴充:叢集部署。部署多個程序節點,對外提供統一通路位址。
探針服務
非監控平台主體,不做高可用保證,當機會有告警,滿足要求。
總體回顧
回顧下整個方案的分析與設計過程,其實整體邏輯很簡單,選型确定之後,根據選型結果,以及選型與目标訴求之間的差異度,考慮如何抹平兩者之間的差異。也即所謂的“不忘初心、以始為終”。
![linux下安裝tuxedo[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)