分析師:Enno
案例資料集是線上零售業務的交易資料,采用Python為程式設計語言,采用Hadoop存儲資料,采用Spark對資料進行處理分析,并使用Echarts做資料可視化。由于案例公司商業模式類似新零售,或者說有向此方向發展利好的趨勢,是以本次基于利于公司經營與發展的方向進行資料分析。
一、概念介紹
用大資料對産品的開發、生産、銷售、流通等進行效能更新,優化整合線上線下資源,全方位提升使用者體驗的零售模式,這就是新零售。
1、新零售不僅僅是銷售。
除了營銷層面,新零售幾乎涉及了産品的研發、設計、生産、品控、排程、包裝、物流、品牌、服務、體驗等各個環節。是以絕對不能把新零售僅僅定義在營銷和銷售的層面上,不僅僅是賣東西,除了賣東西,涉及到了企業經營的幾乎所有方面,其最終目的是對内提升企業效能,對外增強客戶體驗。
2、新零售的核心是使用者體驗。
不管是線下還是線上,不管什麼形式,什麼業态,不管是不是電子商務,隻要不能在“多快好省”4個方面提升消費者的使用者體驗,那就不是新零售,就是僞新零售。
新零售會圍繞“選擇更多、配送更快、品質更好、價格更省”4個次元來提升使用者體驗,盒馬鮮生為什麼火,因為現場買完就下鍋明顯滿足了後面3個“更快 更好 更省”;便利蜂、無人售貨機等新零售為什麼快速擴張?更快。
3、資料驅動。
比如,今年雙十一,平台上的大資料會根據你在雙十一前放到購物筐裡但沒下單的商品,憑借你在平台上的購物習慣和頻次,判斷你在雙十一期間下單的數量和商品類别,然後提前發貨到離你家最近的倉儲點。未來随着無人機等工具的發展,有可能你剛下完單,11樓視窗無人機就會載着貨敲你家窗戶。另外大資料還可以根據使用者的下單資料确定産品的顔色、樣式,分析出最可能熱賣的産品,直接主導研發過程。
二、案例與需求分析
采用Python為程式設計語言,采用Hadoop存儲資料,采用Spark對資料進行處理分析,并使用Echarts做資料可視化。由于案例公司商業模式類似新零售,或者說有向此方向發展利好的趨勢,是以本次基于利于公司經營與發展的方向進行資料分析。
工作流程如下:
1、環境搭建:本次作業使用的環境和軟體如下:
(1)Linux作業系統:Ubuntu 18.04
(2)Python:3.5.2
(3)Hadoop:3.1.3
(4)Spark:2.4.0
(5)Bottle:v0.12.18
2、資料預處理:進行資料清洗,過濾掉有缺失值的記錄
3、資料處理:
(1)篩選出10個客戶數最多的國家
(2)篩選出10個銷量最高的國家
(3)統計各個國家的總銷售額分布情況
(4)統計銷量最高的10個商品
(5)統計商品描述的熱門關Top300
(6)統計退貨訂單數最多的10個國家
(7)統計月銷售額随時間的變化趨勢
(8)統計日銷量随時間的變化趨勢
(9)統計各國的購買訂單量和退貨訂單量的關系
(10)統計商品的平均單價與銷量的關系
4、結果可視化
使用Bottle啟動web服務,結合Echarts可視化架構完成統計結果的展示
5、拓展分析
(1)營運管理與決策
(2)優化企業供應鍊資源配置
(3)财務資料分析
三、工作詳細過程
1、環境搭建:
Bottle是一個快速、簡潔、輕量級的基于WSIG的微型Web架構,此架構除了Python的标準庫外,不依賴任何其他子產品。安裝方法是,打開Linux終端,執行如下指令:
sudo apt-get install python3-pip
pip3 install bottle 此外,我還安裝了jupyter notebook,個人覺得比較友善快捷。
2、資料預處理:
資料集時間跨度為2010-12-01到2011-12-09,每個記錄由8個屬性組成,具體的含義如下表:
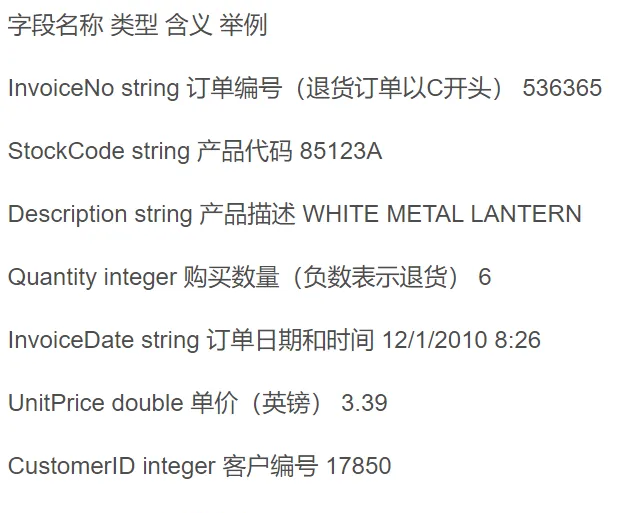
首先,将資料集上傳至hdfs上,指令如下:

接着,使用如下指令進入pyspark的互動式程式設計環境,對資料進行初步探索和清洗:
(1)讀取在HDFS上的檔案,以csv的格式讀取,得到DataFrame對象。
(2)檢視資料集的大小,輸出541909,不包含标題行。
(3)列印資料集的schema,檢視字段及其類型資訊。輸出内容就是上文中的屬性表。
(4)建立臨時視圖data。
(5)由于顧客編号CustomID和商品描述Description均存在部分缺失,是以進行資料清洗,過濾掉有缺失值的記錄。特别地,由于CustomID為integer類型,是以該字段若為空,則在讀取時被解析為0,故用df[“CustomerID”]!=0 條件過濾。
(6)檢視清洗後的資料集的大小,輸出406829。
(6)資料清洗結束。根據作業要求,預處理後需要将資料寫入HDFS。将清洗後的檔案以csv的格式,寫入E_Commerce_Data_Clean.csv中(實際上這是目錄名,真正的檔案在該目錄下,檔案名類似于part-00000),需要確定HDFS中不存在這個目錄,否則寫入時會報“already exists”錯誤。
至此,資料預處理完成。接下來将使用python編寫應用程式,對清洗後的資料集進行統計分析。
3、資料處理
首先,導入需要用到的python子產品。
接着,擷取spark sql的上下文。
最後,從HDFS中以csv的格式讀取清洗後的資料目錄E_Commerce_Data_Clean.csv,程式會取出該目錄下的所有資料檔案,得到DataFrame對象,并建立臨時視圖data用于後續分析。
清洗過後的部分資料展示:
(1)篩選出10個客戶數最多的國家
每個客戶由編号CustomerID唯一辨別,是以客戶的數量為COUNT(DISTINCT CustomerID),再按照國家Country分組統計,根據客戶數降序排序,篩選出10個客戶數最多的國家。得到的countryCustomerDF為DataFrame類型,執行collect()方法即可将結果以數組的格式傳回。
最後調用save方法就可以将結果導出至檔案了,結果如下:
(2)篩選出10個銷量最高的國家
Quantity字段表示銷量,因為退貨的記錄中此字段為負數,是以使用SUM(Quantity)即可統計出總銷量,即使有退貨的情況。再按照國家Country分組統計,根據銷量降序排序,篩選出10個銷量最高的國家。得到的countryQuantityDF為DataFrame類型,執行collect()方法即可将結果以數組的格式傳回。
(3)各個國家的總銷售額分布情況
UnitPrice 字段表示單價,Quantity字段表示銷量,退貨的記錄中Quantity字段為負數,是以使用SUM(UnitPrice*Quantity)即可統計出總銷售額,即使有退貨的情況。再按照國家Country分組統計,計算出各個國家的總銷售額。得到的countrySumOfPriceDF為DataFrame類型,執行collect()方法即可将結果以數組的格式傳回。
(4)銷量最高的10個商品
Quantity字段表示銷量,退貨的記錄中Quantity字段為負數,是以使用SUM(Quantity)即可統計出總銷量,即使有退貨的情況。再按照商品編碼StockCode分組統計,計算出各個商品的銷量。得到的stockQuantityDF為DataFrame類型,執行collect()方法即可将結果以數組的格式傳回。
(5)商品描述的熱門關Top300
Description字段表示商品描述,由若幹個單詞組成,使用LOWER(Description)将單詞統一轉換為小寫。此時的結果為DataFrame類型,轉化為rdd後進行詞頻統計,再根據單詞出現的次數進行降序排序,流程圖如下:
得到的結果為RDD類型,為其制作表頭wordCountSchema,包含word和count屬性,分别為string類型和integer類型。調用createDataFrame()方法将其轉換為DataFrame類型的wordCountDF,将word為空字元串的記錄剔除掉,調用take()方法得到出現次數最多的300個關鍵詞,以數組的格式傳回。
(6)退貨訂單數最多的10個國家
InvoiceNo字段表示訂單編号,是以訂單總數為COUNT(DISTINCT InvoiceNo),由于退貨訂單的編号的首個字母為C,例如C540250,是以利用WHERE InvoiceNo LIKE ‘C%’子句即可篩選出退貨的訂單,再按照國家Country分組統計,根據退貨訂單數降序排序,篩選出10個退貨訂單數最多的國家。得到的countryReturnInvoiceDF為DataFrame類型,執行collect()方法即可将結果以數組的格式傳回。
(7)月銷售額随時間的變化趨勢
統計月銷售額需要3個字段的資訊,分别為訂單日期InvoiceDate,銷量Quantity和單價UnitPrice。由于InvoiceDate字段格式不容易處理,例如“8/5/2011 16:19”,是以需要對這個字段進行格式化操作。由于統計不涉及小時和分鐘數,是以隻截取年月日部分,并且當數值小于10時補前置0來統一格式,期望得到年、月、日3個獨立字段。先實作formatData()方法,利用rdd對日期、銷量和單價字段進行處理。
流程圖如下:
由于要統計的是月銷售額的變化趨勢,是以隻需将日期轉換為“2011-08”這樣的格式即可。而銷售額表示為單價乘以銷量,需要注意的是,退貨時的銷量為負數,是以對結果求和可以表示銷售額。RDD的轉換流程如下:
得到的結果為RDD類型,為其制作表頭schema,包含date和tradePrice屬性,分别為string類型和double類型。調用createDataFrame()方法将其轉換為DataFrame類型的tradePriceDF,調用collect()方法将結果以數組的格式傳回。
(8)日銷量随時間的變化趨勢
由于要統計的是日銷量的變化趨勢,是以隻需将日期轉換為“2011-08-05”這樣的格式即可。先調用上例的formatData()方法對日期格式進行格式化。RDD的轉換流程如下:
得到的結果為RDD類型,為其制作表頭schema,包含date和saleQuantity屬性,分别為string類型和integer類型。調用createDataFrame()方法将其轉換為DataFrame類型的saleQuantityDF,調用collect()方法将結果以數組的格式傳回。
(9)各國的購買訂單量和退貨訂單量的關系
InvoiceNo字段表示訂單編号,退貨訂單的編号的首個字母為C,例如C540250。利用COUNT(DISTINCT InvoiceNo)子句統計訂單總量,再分别用WHERE InvoiceNo LIKE ‘C%’和WHERE InvoiceNo NOT LIKE ‘C%’統計出退貨訂單量和購買訂單量。接着按照國家Country分組統計,得到的returnDF和buyDF均為DataFrame類型,分别表示退貨訂單和購買訂單,如下所示:
再對這兩個DataFrame執行join操作,連接配接條件為國家Country相同,得到一個DataFrame。但是這個DataFrame中有4個屬性,包含2個重複的國家Country屬性和1個退貨訂單量和1個購買訂單量,為減少備援,對結果篩選3個字段形成buyReturnDF。如下所示:
最後執行collect()方法即可将結果以數組的格式傳回。
(10)商品的平均單價與銷量的關系
由于商品的單價UnitPrice是不斷變化的,是以使用平均單價AVG(DISTINCT UnitPrice)來衡量一個商品。再利用SUM(Quantity)計算出銷量,将結果按照商品的編号進行分組統計,執行collect()方法即可将結果以數組的格式傳回。
最後,将所有的函數整合在變量 m中,通過循環調用上述所有方法并導出json檔案到目前路徑的static目錄下。
最後利用如下指令運作分析程式:
4、結果可視化
結果可視化使用百度開源的免費資料展示架構Echarts。Echarts是一個純Javascript的圖表庫,可以流暢地運作在PC和移動裝置上,相容目前絕大部分浏覽器,底層依賴輕量級的Canvas類庫ZRender,提供直覺,生動,可互動,可高度個性化定制的資料可視化圖表。
編寫python程式,實作一個簡單的web伺服器,代碼如下:
bottle伺服器對接收到的請求進行路由,規則如下:
(1)通路/static/時,傳回靜态檔案
(2)通路/.html時,傳回網頁檔案
(3)通路/時,傳回首頁index.html
伺服器的9999端口監聽來自任意ip的請求(前提是請求方能通路到這台伺服器)。
首頁index.html的主要代碼如下(由于篇幅較大,隻截取主要的部分)
圖表頁通過一個iframe嵌入到首頁中。以第一個統計結果的網頁countryCustomer.html為例,展示主要代碼:
若列印出以下資訊則表示web服務啟動成功。接着,可以通過使用浏覽器通路網頁的方式檢視統計結果。
可視化結果如下:
四、拓展分析
為了使銷售情況更直覺,我進行了熱力圖繪制,能夠明顯看出目前公司的業務闆塊分布,也友善後續的更多分析。
代碼如下:
地圖如下:
- 營運管理與決策
- 拓展業務闆塊
從熱力圖可以看出業務主要在英國本地,加拿大,澳洲,巴西,沙特阿拉伯等國家,而美國、亞洲、俄羅斯、非洲等地幾乎沒有業務,而其實美國、亞洲等地潛力巨大,可以通過宣傳廣告等營銷方式嘗試将商品銷售至這些國家。
- 鞏固原有客人
目前公司顧客主要集中在英國本地及周邊的歐洲國家,且顧客數量懸殊巨大,
需要鑽研顧客喜好或提升品質保留原有客人,以及使在擁有顧客的國家能夠吸引更多消費者。
可以看到看到有些商品即使價格較高,銷量仍然很高,可以考慮适當調整價格,賺取更多利潤;還有有些商品銷量過低,可以調整價格,或者停止生産。
上半年銷量較低,可以在上半年多運用營銷手段提高銷量。
根據熱門商品以及熱門關鍵詞預測生産商品。
- 針對性削減業務
有一些進貨量不多,退貨量還大的國家,可以計算利潤,可以停止或減少在這些地區的銷售業務。
2、優化企業供應鍊資源配置
物流資源主要配置設定給英國本地,加拿大,澳洲,巴西,沙特阿拉伯。
由于銷量大的地區退貨量也大,是以要傾斜物流資源,最好可以有辦法将物流成本降低,比如跟當地物流形成合作。
在上半年貨品産量可以稍小,下半年貨物可以遞增緩步增加産量,下半年以生産禮品為重點
3、财務資料分析
在此可看到各個國家銷售額,若有更多例如商品成本、物流成本等資料還可以進行如資産品質分析、 利潤品質分析、 資本結構分析、 現金流分析等更多詳細的分析,但由于有些資料涉及公司隐私爬取不到,是以在此分析結束。
關于分析師