論文位址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Fan_Camouflaged_Object_Detection_CVPR_2020_paper.pdf
1.整體結構:
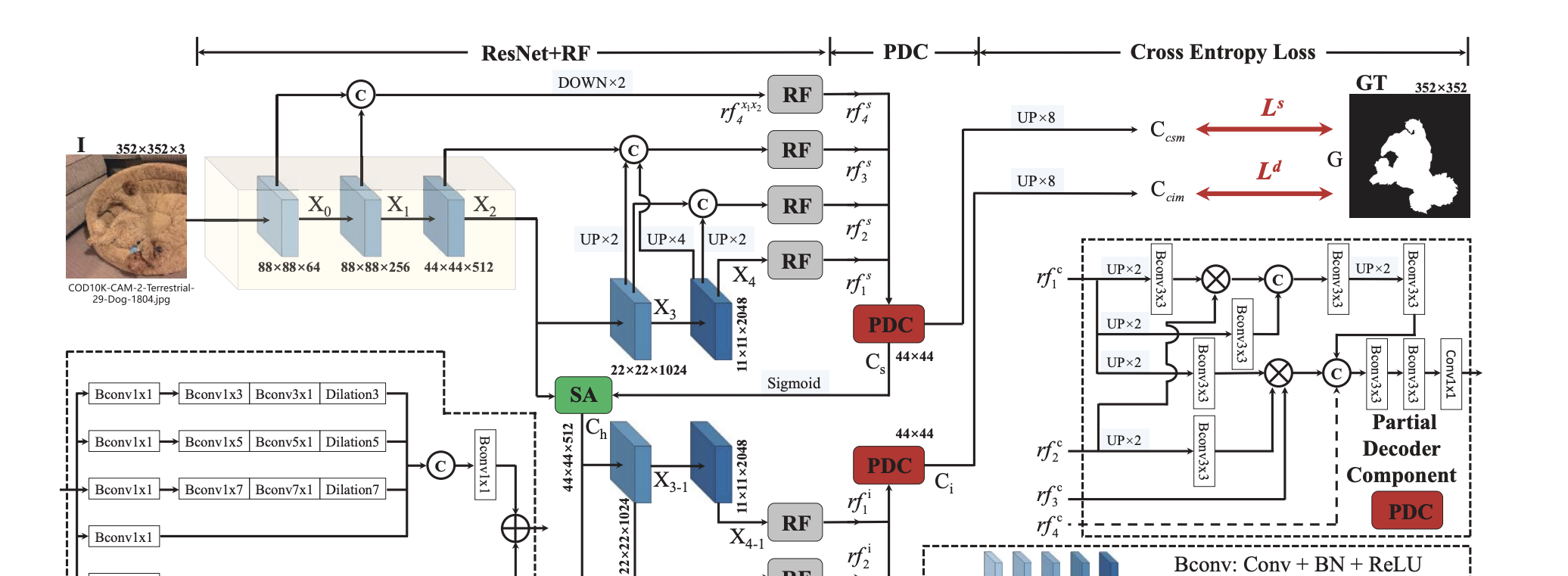
架構主要包括兩個子產品:搜尋子產品 (SearchModule, SM) 和識别子產品 (Identification Module, IM)。前者負責搜尋被僞裝的物體,而後者則用于精确檢測物體。
2. 搜尋子產品(Search Module,SM)
本文 在搜尋階段(通常是在較小的、局部空間中)使用 RF 子產品來整合更具鑒别性的特征表示。具 體而言,對于輸入圖像 I∈R W×H×3,可利用 ResNet50模型提取出一組特征 {Xk} 4 k=0。為了保留更 多資訊,本文将第二層特征層的步長參數設定為 1, 使其和輸入圖像具有相同的分辨率。是以,每一層 分辨率為 {[ H k , W k ], k = 4, 4, 8, 16, 32} 。 最新研究 顯示,更淺的卷積層中的低級 特征保留了用于建構物體邊緣的空間資訊,而深層 的深層卷積層的特征保留了用于定位目标的語義信 息。由于神經網絡本身的固有的特性,本文将提取 的特征進行分層:低層 {X0, X1},中層 X2 和高層 {X3, X4},并通過拼接、上采樣和下采樣等操作進行 組合。與 [79] 不同,本文的 SINet 采用稠密連接配接策 略 [27] 來儲存來自不同特征層的更多資訊,然後使 用改進的 RF [42] 元件來擴大感受野。例如,先使用 拼接操作來融合低級特征 {X0, X1},然後将分辨率 下采樣為原始一半。再将融合後的新特征 rf x1x2 4 進 一步輸入到 RF 元件生成 rf s 4 特征。
RF子產品的前世解讀:
RF的靈感來源于

群智感受野(pRF)屬性的規律。 (A)pRF大小可以看作人類視網膜圖中偏心率的函數,其中兩個趨勢是明顯的:(1)pRF大小随着每個圖中的偏心率而增加,以及(2)圖之間的pRF大小有差異。 (B)基于(A)中的參數的pRF的空間陣列:每個圓的半徑是在适當的偏心率下的表觀RF尺寸。
翻譯一下就是:人視野的一個特點,離視線中心越遠,人的感受野越大,越靠近視線中間,人感受野越小;人對不同物體的感受野大小不同
通過将多個分支與不同的卷積核和膨脹卷積組合來建構RFB子產品。 多個卷積核類似于不同大小的pRF,而膨脹卷積為每個分支配置設定單獨的偏心率以模拟pRF的大小和偏心率之間的比率。 通過将所有分支合并進行1*1卷積變換,産生RF的最終空間陣列,其機理類似于上邊所示的人類視覺系統
3.識别子產品 ((Identification Module, IM)
本文采 用密集連接配接方式對部分解碼元件 (Partial Decoder Component,PDC) 進行了擴充。具體來講,PDC 整合了來自 SM 的四個特征層。可通過以下公式來 計算粗糙的僞裝圖 Cs: Cs = P Ds(rf s 1 , rf s 2 , rf s 3 , rf s 4 ), (1) 其中 {rf s k = rfk, k = 1, 2, 3, 4}。現有文獻已 表明,注意力機制可以有效地消除無關特征的幹擾。 是以引入搜尋注意力 (Search Attention,SA) 子產品 來增強中間特征層 X2 并獲得增強的僞裝圖 Ch: Ch = fmax(g(X2, σ, λ), Cs), (2) 其中 g(·) 是 SA 函數,即為典型的歸一化後的高斯 濾波器,其标準差為:σ = 32,核尺寸為:λ = 4, fmax(·) 是一個最大化函數,用來突出僞裝圖 Cs 初 始的僞裝區域。 為了全面擷取高層特征,本文進一步使用 PDC 來聚合另外三層的特征,并通過 RF 進行增強,以 獲得最終的僞裝圖 Ci: Ci = P Di(rfi 1 , rfi 2 , rfi 3 ), (3)
PDC到SA再到PDC子產品的結構與下圖思路相似:https://arxiv.org/pdf/1904.08739.pdf
參考部落格:
https://blog.csdn.net/spellindover/article/details/107443980
(如有侵權,聯系必删)