神經網絡參數的調節和選取一般都比較玄學,需要有比較豐富的經驗才能訓練出比較
SOTA
的網絡。下面總結出幾個比較常見且實用的訓練技巧。
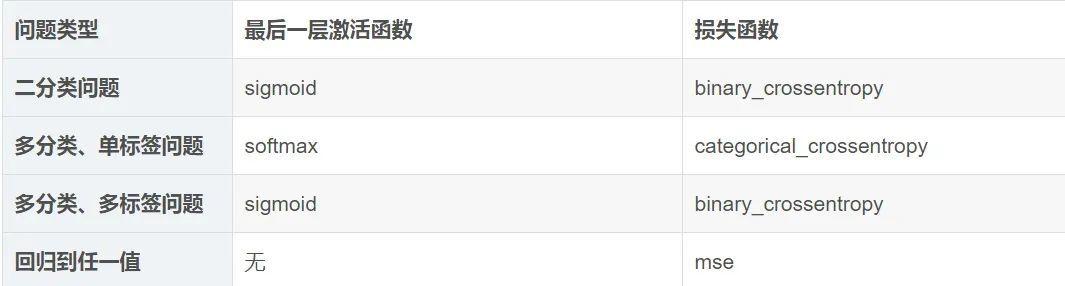
為模型選擇正确的最後一層激活和損失函數
batch_size的選擇
使用大的batch size有害身體健康。更重要的是,它對測試集的error不利。一個真正的朋友不會讓你使用大于32的batch size。直說了吧:2012年來人們開始轉而使用更大batch size的原因隻是我們的GPU不夠強大,處理小于32的batch size時效率太低。這是個糟糕的理由,隻說明了我們的硬體還很辣雞。也就是最好的實驗表現都是在batch size處于2~32之間得到的。因為batch_size越小時每次更新時由于沒有使用全量資料而僅僅使用batch内資料,進而人為給訓練帶來了噪聲,而這個操作卻往往能夠帶領算法走出局部最優(鞍點)。當模型訓練到尾聲,想更精細化地提高成績(比如論文實驗/比賽到最後),有一個有用的trick,就是設定batch size為1,即做純SGD,慢慢把error磨低。
一些技巧
一旦得到了具有統計功效的模型,問題就變成了:模型是否足夠強大?它是否具有足夠多的層和參數來對問題進行模組化?例如,隻有單個隐藏層且隻有兩個單元的網絡,在 MNIST 問題上具有統計功效,但并不足以很好地解決問題。請記住,機器學習中無處不在的對立是優化和泛化的對立,理想的模型是剛好在欠拟合和過拟合的界線上,在容量不足和容量過大的界線上。為了找到這條界線,你必須穿過它。要搞清楚你需要多大的模型,就必須開發一個過拟合的模型,這很簡單。
- 添加更多的層。
- 讓每一層變得更大。
- 訓練更多的輪次。
要始終監控訓練損失和驗證損失,以及你所關心的名額的訓練值和驗證值。如果你發現模型在驗證資料上的性能開始下降,那麼就出現了過拟合。下一階段将開始正則化和調節模型,以便盡可能地接近理想模型,既不過拟合也不欠拟合。
模型正則化與調節超參數
這一步是最費時間的:你将不斷地調節模型、訓練、在驗證資料上評估(這裡不是測試資料)、再次調節模型,然後重複這一過程,直到模型達到最佳性能。你應該嘗試以下幾項:
1)添加 dropout。
2)嘗試不同的架構:增加或減少層數。
3)添加
L1
和 / 或
L2
正則化。
4) 嘗試不同的超參數(比如每層的單元個數或優化器的學習率),以找到最佳配置。
5)(可選)反複做特征工程:添加新特征或删除沒有資訊量的特征。
請注意:每次使用驗證過程的回報來調節模型,都會将有關驗證過程的資訊洩露到模型中。如果隻重複幾次,那麼無關緊要;但如果系統性地疊代許多次,最終會導緻模型對驗證過程過拟合(即使模型并沒有直接在驗證資料上訓練)。這會降低驗證過程的可靠性。
一旦開發出令人滿意的模型配置,你就可以在所有可用資料(訓練資料 + 驗證資料)上訓練最終的生産模型,然後在測試集上最後評估一次。如果測試集上的性能比驗證集上差很多,那麼這可能意味着你的驗證流程不可靠,或者你在調節模型參數時在驗證資料上出現了過拟合。在這種情況下,你可能需要換用更加可靠的評估方法,比如重複的 K 折驗證。