客戶生産系統上的SQL, 表越來越大, 執行時間越來越長, 不過隻要能跑出結果, 隻要不是慢到無法接受, 使用者基本上都忍了.
很多客戶的系統都是這樣, 業務SQL消耗了過多的系統資源, 執行效率還很差, 大部分都有很大的優化空間, 隻是很多人首先會想到更換進階硬體, 不知道優化才是正道(有個客戶的EBS業務執行幾個小時後報ora-01555錯誤, 硬體已經很進階了, SQL優化是唯一出路)
SQL代碼(已經過簡化脫敏處理):
select a.*, b.INPTBR as inst_no
from pa_agency a
left join
(
select tc.inptbr, tc.fragid
from book1 tc
union
select tcs.inptbr, tcs.fragid
from book2 tcs
) b
on a.agenid = b.fragid;
執行計劃(執行時間38秒):
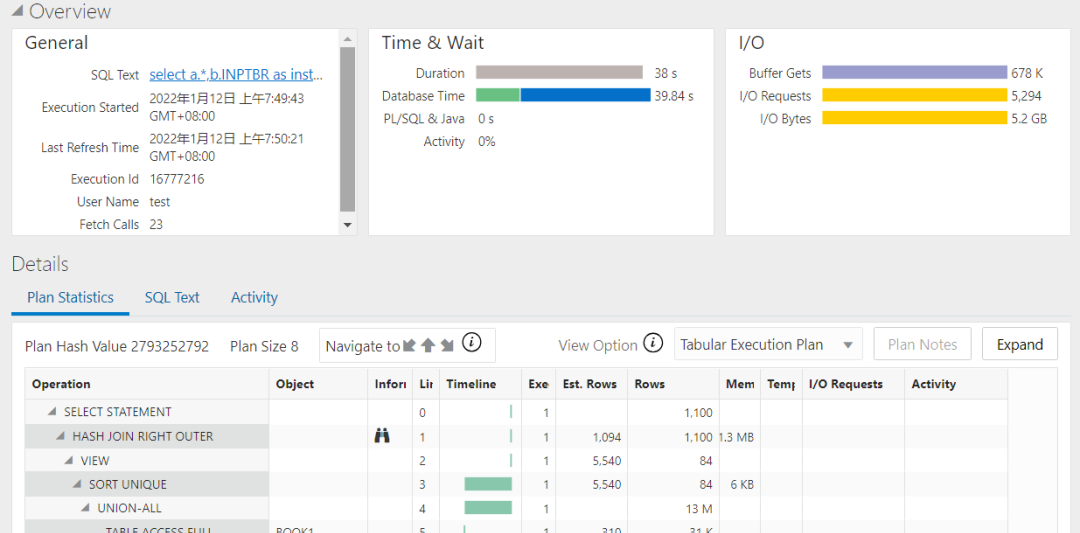
已知b結果集中fragid沒有重複值. 3個表的記錄數都顯示在上圖的執行計劃中.請思考一下這個SQL該如何提高執行效率.
思考時間....................................................
我把這個SQL作為練習題放到了學員微信群給大家練手, 有學員已經給出了一個比較好的優化方法, 下面分别把學員的方法和我的方法列出來:
首先都是要分别建立book1和boo2兩表fragid字段上的索引.
其次是需要對sql進行改寫.
學員的改寫方法:
select a.*,
nvl((select inptbr
from book1 tc
where a.agenid = tc.fragid
and rownum = 1
),
(select inptbr
from book2 tcs
where a.agenid = tcs.fragid
and rownum = 1
)) as inptbr
from pa_agency a;
我的改寫方法:
select a.*,
(select inptbr from
(
select tc.inptbr,tc.fragid
from book1 tc
union all
select tcs.inptbr,tcs.fragid
from book2 tcs
) b where a.agenid=b.fragid
and rownum =1
) as inst_no
from pa_agency a ;
兩種方法都可以大幅提升sql執行效率(預計一秒内可以執行完), 兩種方法的效率也有一些細微差别, 不知道你能不能看出來?
在我的之前的這篇公衆号文章中, 也有類似的優化思路 : <74-這類SQL優化,oracle輸給了mysql,如何補救?> , 有的東西并不一定都是壞的, 有時我們反而可以用它來做優化.
(本篇完)