在SQL中支援行比對模式的match_recognize寫法, 是oracle 從12c開始推出的, 功能很強大,文法看起來有點複雜, 跟普通的SQL差別挺大.
oracle在介紹這個新寫法的時候, 舉了一個擷取股票V型圖(2個峰值一個谷值)的例子(網上有很多介紹,都是用的這個例子), 但是除了這個例子以為, 較少見到其他應用案例, 這裡抛磚引玉, 介紹幾個用match_recognize解決問題的方法 , 僅供參考.
示例(1) : 去除連續的重複狀态, 隻保留第一條, 如下圖, 劃紅線的是需要去除的記錄
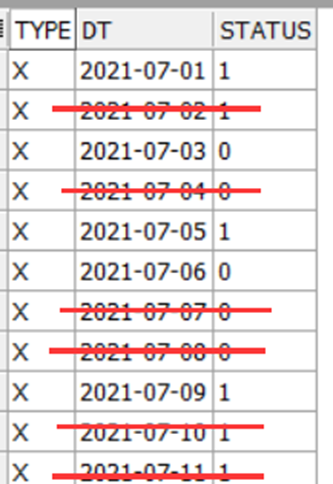
這個問題如果用分析函數實作起來也比較簡單, 下面是用match_recognize實作的方法:
with d (type,dt,status)as
( select 'X' ,date '2021-7-1','1' from dual
union all select 'X' ,date '2021-7-2','1' from dual
union all select 'X' ,date '2021-7-3','0' from dual
union all select 'X' ,date '2021-7-4','0' from dual
union all select 'X' ,date '2021-7-5','1' from dual
union all select 'X' ,date '2021-7-6','0' from dual
union all select 'X' ,date '2021-7-7','0' from dual
union all select 'X' ,date '2021-7-8','0' from dual
union all select 'X' ,date '2021-7-9','1' from dual
union all select 'X' ,date '2021-7-10','1' from dual
union all select 'X' ,date '2021-7-11','1' from dual
)
SELECT *
FROM d
MATCH_RECOGNIZE (
PARTITION BY type
ORDER BY dt
measures
dt as dt,
status as status
one ROW PER MATCH
PATTERN ( A )
DEFINE
A as status<>prev(status) or prev(status) is null
);
還有其他寫法, 也能得到相同結果, 下面是itpub開發版版主蘇大師的寫法:
with d (type,dt,status)as
( select 'X' ,date '2021-7-1','1' from dual
union all select 'X' ,date '2021-7-2','1' from dual
union all select 'X' ,date '2021-7-3','0' from dual
union all select 'X' ,date '2021-7-4','0' from dual
union all select 'X' ,date '2021-7-5','1' from dual
union all select 'X' ,date '2021-7-6','0' from dual
union all select 'X' ,date '2021-7-7','0' from dual
union all select 'X' ,date '2021-7-8','0' from dual
union all select 'X' ,date '2021-7-9','1' from dual
union all select 'X' ,date '2021-7-10','1' from dual
union all select 'X' ,date '2021-7-11','1' from dual
)
SELECT *
FROM d
MATCH_RECOGNIZE (
PARTITION BY type
ORDER BY dt
ALL ROWS PER MATCH
PATTERN ( (A|{-B-})+ )
DEFINE
A as status<>last(status,1) or prev(status) is null
);
大家可以比較一下二者的差別.
示例(2): 得到後面記錄值比目前記錄值大的記錄個數, 比如下面結果集

左邊兩列是原始記錄, 最後一列是match_recognize後得到的結果. 第一條記錄的val是4, 下面9條件記錄當中, 都比4大, cnt就是9; 第二條val是10, 下面比10大的記錄有12和14, cnt就是2, 以此類推.
with gen as
(select rownum as ID, round(dbms_random.value(3,15)) as val
from dual connect by level<=10
)
select * from gen
match_recognize(
order by id
measures
first(a.id) as id,
first(a.val) as val,
final count(b.*) as cnt
one row per match
after match skip to next row
pattern (a (b|c)* )
define
b as b.val>a.val,
c as c.val<=a.val
);
(實作這個功能的寫法有多種, 這裡隻談match_recognize的寫法)
示例(3): 得到所有員工及全部下屬的工資總和
select * from
(
select level lvl, ename, sal
from scott.emp
start with mgr is null
connect by mgr = prior empno
)
match_recognize
(
measures
a.lvl lvl, a.ename ename,a.sal sal,
sum(sal) as sum_sal
after match skip to next row
pattern(a b*)
define b as lvl > a.lvl
);
結果集:
其中第一條記錄 lvl=1, 下面所有記錄的lvl都<1,sum_sal相當于整個公司的工資總和 ; 第二條記錄lvl=2, 到下一個lvl=2前的所有記錄之和=10875(2975+3000+1100+3000+800 ), 以此類推.
示例(4) : 合并連續區間
with tmp(id ,page) as
(select 1 ,3 from dual union all select 2,4 from dual union all
select 4,8 from dual union all select 3,5 from dual union all
select 5,9 from dual union all select 6,16 from dual union all
select 7,15 from dual union all select 8,18 from dual
)
SELECT *
FROM tmp
MATCH_RECOGNIZE
(
ORDER BY page
MEASURES
A.page as firstpage,
LAST(page) as lastpage,
COUNT(*) cnt
ONE ROW PER MATCH
AFTER MATCH SKIP PAST LAST ROW
PATTERN (A B*)
DEFINE B AS page = PREV(page)+1
);
結果集(左邊是合并前):
其中: 3~5是連續的3個值; 8~9 是連續的2個值...
示例(5) : 計算連續3天(第一條記錄和第三條記錄間隔不超過3天)的記錄和
在公衆号文章 73-找到業務高峰時段的sql示例(報表開發類)中, 我在留言部分分别補充了分析函數和model的寫法, 這裡再補充一個match_recognize的寫法, 這個寫法不需要補齊不存在的"天", 用模拟資料示範如下:
with gen (id, val) as
(select 1, 3 from dual union all select 2, 2 from dual union all select 3,5 from dual union all
select 5, 3 from dual union all select 8, 2 from dual union all select 9,5 from dual union all
select 10, 3 from dual union all select 12, 2 from dual union all select 13,5 from dual union all
select 14, 3 from dual union all select 15, 2 from dual union all select 16,5 from dual union all
select 20, 3 from dual union all select 21, 2 from dual union all select 23,5 from dual
)
select bid,bid+2 as eid,sum3 from gen
match_recognize(
order by id
measures
first (a.id) as bid,
sum(val) as sum3
one row per match
after match skip to next row
pattern (A B*)
define
B as b.id<=a.id+2
);
結果集(左邊是原始資料, 右邊是match_recognize後的結果):
得到了右邊的結果集後, 可以再做深入加工(比如再選出top 5等)
示例(6) : 來自itpub 蘇大師的每周一題
http://www.itpub.net/thread-2117353-1-1.html
create table qz_game_log (
seq integer primary key
, log varchar2(10)
);
insert into qz_game_log values (117, 'GO');
insert into qz_game_log values (118, 'LEFT');
insert into qz_game_log values (119, 'LEFT');
insert into qz_game_log values (120, 'RIGHT');
insert into qz_game_log values (121, 'LEFT');
insert into qz_game_log values (122, 'FINISH');
insert into qz_game_log values (123, 'GO');
insert into qz_game_log values (124, 'RIGHT');
insert into qz_game_log values (125, 'RIGHT');
insert into qz_game_log values (126, 'LEFT');
insert into qz_game_log values (127, 'CRASH');
insert into qz_game_log values (128, 'GO');
insert into qz_game_log values (129, 'RIGHT');
insert into qz_game_log values (130, 'LEFT');
insert into qz_game_log values (131, 'RIGHT');
insert into qz_game_log values (132, 'LEFT');
insert into qz_game_log values (133, 'RIGHT');
insert into qz_game_log values (134, 'FINISH');
commit;
每個遊戲都是從GO開始,然後是一系列的LEFT或者RIGHT移動,然後以 FINISH 或者 CRASH 終止。
成功結束的遊戲以FINISH而不是CRASH終止,我想要檢視所有成功遊戲的LEFT/RIGHT移動步驟,
從哪個SEQ開始到哪個SEQ截止,還想知道總共多少步,其中RIGHT幾步,LEFT幾步。
GO和FINISH不計算在遊戲的移動步驟之内。
所要求的輸出:
FROM_SEQ TO_SEQ MOVES RIGHTS LEFTS
---------- ---------- ---------- ---------- ----------
118 121 4 1 3
129 133 5 3 2
原作者給出的兩個寫法, 值得學習:
寫法 1)
select min(seq) as from_seq
, max(seq) as to_seq
, count(*) as moves
, count(case cls when 'RIGHT' then 1 end) as rights
, count(case cls when 'LEFT' then 1 end) as lefts
from qz_game_log
match_recognize (
measures
match_number() as mno
, classifier() as cls
ALL ROWS PER MATCH
pattern ({-GO-} (LEFT|RIGHT)+ {-FINISH-})
define
GO as log = 'GO'
, LEFT as log = 'LEFT'
, RIGHT as log = 'RIGHT'
, FINISH as log = 'FINISH'
)
GROUP BY mno
order by from_seq;
寫法 2)
select from_seq, to_seq, moves, rights, lefts
from qz_game_log
match_recognize (
measures
min(MOVE.seq) as from_seq
, max(MOVE.seq) as to_seq
, count(MOVE.seq) as moves
, count(RIGHT.seq) as rights
, count(LEFT.seq) as lefts
one row per match
pattern (GO (LEFT|RIGHT)+ FINISH)
SUBSET
MOVE = (LEFT, RIGHT)
define
GO as log = 'GO'
, LEFT as log = 'LEFT'
, RIGHT as log = 'RIGHT'
, FINISH as log = 'FINISH'
)
order by from_seq;
寫法 3) 這是我嘗試的一個寫法(殊途同歸,性能上應該沒啥差別):
select * from qz_game_log
match_recognize(
order by seq
measures
least(first(l.seq) , first(r.seq) ) as from_seq,
greatest(last(l.seq) , last(r.seq) ) as to_seq,
count(l.*)+count(r.*) as moves,
count(r.*) as rights,
count(l.*) as lefts
one row per match
pattern
( strt (L|R)+ fini )
define
strt as log='GO',
L as log='LEFT',
R as log='RIGHT',
fini as log='FINISH'
);
用match_recognize實作行與行之間比對的相關的案例還有很多, 也有一些實作複雜的業務邏輯. 這裡列舉一些簡單的例子, 讓大家對match_recognize的用法有一個大緻的了解.
match_recognize在金融行業應該有較多的應用場景(比如股票分析和可疑交易分析), 開發人員在熟悉這個功能後, 就可以輕松的用SQL實作複雜的業務邏輯.