今天這個案例相對比較簡單,算是對基本原理的一個加強了解吧。
客戶提供了一份其他公司做的優化報告,其中有個SQL确實是完成了優化,優化的結果也不錯,但是給出的優化理由卻是不準确的。
下面是報告對該SQL進行分析優化的描述:
SQL代碼如下:
SELECT COUNT(1)
FROM CB_PROBLEM A
LEFT OUTER JOIN CB_PROJECT B ON A.PRJ_SEQ = B.PRJ_SEQ
LEFT OUTER JOIN BS_LINE C ON A.PRB_LINE = C.LINE_SEQ
LEFT OUTER JOIN BP_FLOW D ON A.PRB_FLOW = D.FLOW_SEQ
LEFT OUTER JOIN BP_NODE E ON A.PRB_NODE = E.NODE_SEQ
LEFT OUTER JOIN BS_EFFECT F ON A.EFFECT_LVL = F.VALUE_SEQ
LEFT OUTER JOIN BS_FREQUENCY G ON A.FREQUENCY_LVL = G.VALUE_SEQ
LEFT OUTER JOIN BS_S EVERITY H ON A.SEVERITY_LVL = H.VALUE_SEQ
WHERE A.STATUS != 0
AND A.PRB_ORG IN
(
SELECT ORG_ID
FROM SP_ORG
START WITH ORG_ID IN (:1, ......, :18)
CONNECT BY PRIOR ORG_ID = SUP_ORG
)
AND A.PRJ_SEQ IN
(
SELECT PRJ_SEQ
FROM CB_PROJECT
WHERE 1 = 1 AND PRJ_NAME LIKE '%xxxxxxx%'
);
執行計劃如下(紅字是老虎劉補注):
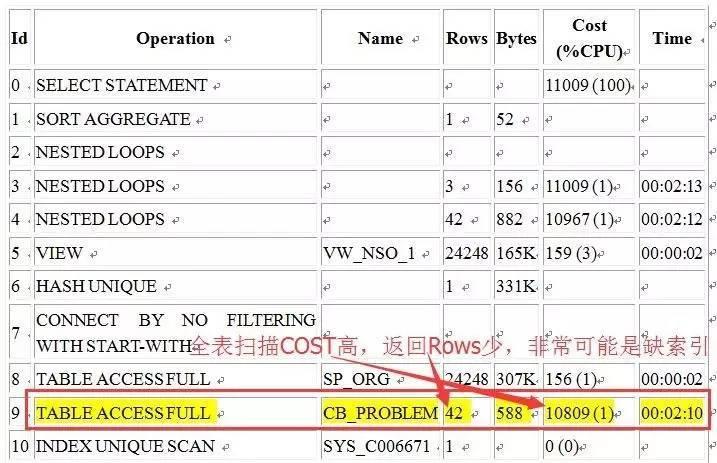
(老虎劉注:看到這個執行計劃有人可能會問,SQL語句中那麼多做left join的表,上面為什麼一個都沒看到?
這是因為最後要的結果是count(1),left join的表如果關聯字段都是唯一的(這個是根據執行計劃判斷出來的),優化器會很聰明的把這些表從執行計劃中消除,結果是等價的)。
其中主表CB_PROBLEM大小為312M,約44萬行資料。SQL平均執行時間為6分鐘。
CB_PROBLEM表目前索引情況:
INDEX_OWNER INDEX_NAME COLUMN_NAME COLUMN_POSITION
------------ --------------------------- -------------- ---------------
ICIMS01 IDX_CB_PROBLEM_PRJ_SEQ PRJ_SEQ 1
ICIMS01 IDX_PROBLEM_ID PRB_ID 1
ICIMS01 IDX_PROBLEM_SEQ PRB_SEQ 1
ICIMS01 IDX_PROBLEM_SEQ PRJ_SEQ 2
ICIMS01 SYS_C006663 PRB_SEQ 1
(老虎劉注: IDX_PROBLEM_SEQ索引首字段與SYS_C006663重複,SYS_C006663索引可以删掉 )
SQL中涉及的字段的選擇性:
COLUMN_NAME NUM_DISTINCT
------------------------ ------------
PRB_ORG 10319
PRJ_SEQ 75264
原報告由此得出的結論是:
可以看出,SQL中出現的字段PRJ_SEQ 已經在多個索引中出現,而且其選擇性也不錯, 為75264,之是以沒走上該字段的索引,是由于該字段對應的子查詢傳回結果過多,達到1萬多行,是以優化器沒有其上的索引。
SQL中還涉及另一個字段PRB_ORG,它的選擇性也不錯,為10319,并且其上沒有索引,經分析,建議在PRB_ORG和PRJ_SEQ上建立複合索引。
create index idx_test on ICIMS01.cb_problem(prb_org,prj_seq) online ;
我們先來看看增加索引後的SQL執行情況:
執行時間隻需要2.73秒,比原來的6分鐘有非常大的提高。執行計劃如下:

下面我們來分析一下為什麼說這個索引建立的理由是錯誤的。
執行計劃中的步驟10由原來的全表掃描變成了索引掃描,這一步是建立索引的功勞。
執行計劃中,SP_ORG表作為初始驅動表,cb_problem表是作為nested loops的被驅動表,與驅動表的關聯字段隻有一個:PRB_ORG,雖然使用的是兩字段聯合索引,但實際上隻用到了第一個字段:PRB_ORG。
接下來cb_problem表又做為nested loops的驅動表,通過PRJ_SEQ字段驅動CB_PROJECT表時,使用的是CB_PROJECT表的關聯字段PRJ_SEQ字段上的索引,與此時的驅動表cb_problem表PRJ_SEQ字段上是否有索引無關。
也就是說,原結論建立兩個字段上的索引,其實隻需要一個字段就夠了,增加一個字段也不會提高索引在這個SQL中的選擇性(有可能在其他SQL同時使用兩個字段做謂詞條件時是高效的)。
總結:
在哪個表上建立索引,建立怎樣的索引才能使SQL執行效率最高,需要徹底搞清楚SQL執行計劃。有時問題解決了,可能還是沒有了解真正的原因。建立索引不是靠猜測,而是經過仔細分析後得出的結果。
兩表關聯做nested loops時,驅動表要求結果集(經過謂詞條件過濾後)要小,表的謂詞條件字段上一般要存在索引(不是關聯字段);被驅動表的關聯字段上要存在索引,這是基本常識。
比如下面這種OLTP系統常見的兩表關聯SQL:
select .... from t1,t2
where t1.object_id = t2.object_id and t1.object_name='T1';
執行計劃應該是t1表做驅動表,使用object_name字段上的索引,選出少量記錄,t2表做被驅動表,object_id字段(關聯字段)上要存在索引。
就這個sql本身而言,t1表的object_id字段上有沒有索引是沒有關系的。在某個客戶現場發現這樣的SQL,建立的是t1表object_id和object_name兩個字段的聯合索引,那就大錯特錯了。
後話:
優化後的執行計劃,根據顯示的估值行數,驅動表的行數還是比較高,前兩個表到底是做nested loops 還是做hash join好一些還不好說(沒有測試過),如果是hash join更好一些,那麼上面那個索引其實也沒有建立的必要了。