某物流客戶系統查詢快遞單的SQL,IO消耗為TOP 1:
SQL代碼如下:
select id,
op_code,
to_char(create_time, :"SYS_B_1") as create_time,
……
from T_EXP_OP_RECORD_CONTAINER A
where status <> :"SYS_B_4" and ID = :1 and rownum = :"SYS_B_5";
其中T_EXP_OP_RECORD_CONTAINER 表是一個在Create_time字段按天一級分和op_code字段按地區二級分區的分區表,ID字段儲存的是快遞單号資訊,字段上存在索引。
SQL代碼中出現了"SYS_B_n" 字樣的綁定變量,這是因為資料庫參數的cursor_sharging被設定為FORCE(強烈建議保持預設值EXACT),SQL中使用的常量值被強制轉換成了綁定變量。rownum=後面的常量被強制轉換成了綁定變量,這個值根據常識可以判斷為1,因為隻有1才有意義。
快遞單号基本上是唯一的,這樣的SQL,正常執行時間應該在1毫秒左右。
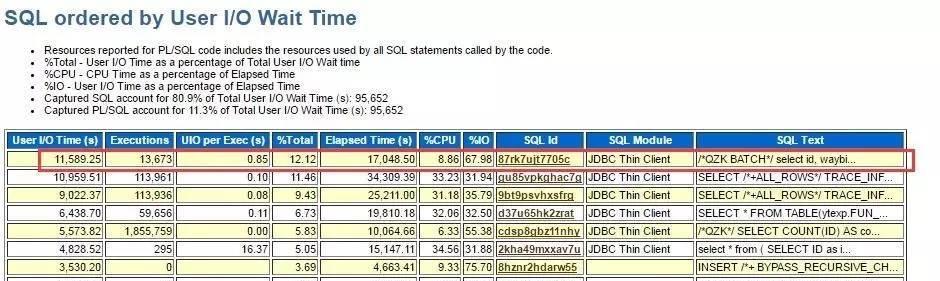
而下圖使用awrsqrpt收集的SQL實際執行情況是:每次執行耗時1.236秒。

SQL執行計劃如下:
看到上面的執行計劃後,就會明白平均執行時間是1秒多就正常了:這個查詢要到6030個local index裡面檢索資料,平均每個local index至少要掃描3個buffers 才能判斷記錄是否存在,因為有rownum=1 謂詞條件,最好的情況是掃描local index的第一個分支就找到了結果,不再繼續掃描下去;最差的情況是掃描到local index的最後一個分支才找到結果,或是沒有找到結果。
一般情況下,local index索引的使用,需要配合分區字段一起做謂詞條件,才能隻掃描少數的索引分支。而這個SQL由于業務原因,不能增加分區字段作為謂詞條件。這種情況就需要将local index改成Global index,才會使SQL性能達到最佳。
但是,因為該表非常龐大(表和索引占用的空間達到T級),需要定期删除(轉移)曆史分區,隻保留最近一年的資料,如果建立的是global index,删除曆史分區後,需要對global index進行重建,維護時間視窗很難完成(有多個類似表)。這是個兩難的問題。
針對快遞業務的特點,老虎劉給出的建議是:
1、仍使用local index,重建表,減少分區數量:按天分區改為按月分區,不要子分區;
2、因為很少有使用者會查詢1個月以上的快遞單,該表隻保留最近2個月分區資料,其他資料轉移到曆史分區,正常情況隻需要最多掃描2個分區,而不是原來的6030個分區。
3、通過plsql實作查詢:目前分區沒有查詢到結果,再去查詢曆史分區。這樣也能保證超過2個月的快遞單也能正常查詢。
總結:
分區表,到底選擇global index還是local index,需要根據具體的業務和運維的實際需求而定。不需要删除曆史分區資料的分區表,可以建立global index(如基礎資料表);需要定期删除曆史分區的分區表,最好是建立local index,如果遇到分區字段無法成為查詢條件時,建議盡量減少分區數,避免過多的local index 掃描,影響SQL性能。