文章目錄:
-
一.三大線上百科
1.Wikipedia
2.百度百科
3.互動百科
-
二.Selenium爬取百度百科知識
1.網頁分析
2.代碼實作
-
三.Selenium爬取Wikipedia
1.網頁分析
2.代碼實作
-
四.Selenium爬取互動百科
1.網頁分析
2.代碼實作
- 五.本章小結
下載下傳位址:
- https://github.com/eastmountyxz/Python-zero2one
一.三大線上百科
随着網際網路和大資料的飛速發展,我們需要從海量資訊中挖掘出有價值的資訊,而在收集這些海量資訊過程中,通常都會涉及到底層資料的抓取建構工作,比如多源知識庫融合、知識圖譜建構、計算引擎建立等。其中具有代表性的知識圖譜應用包括谷歌公司的Knowledge Graph、Facebook推出的實體搜尋服務(Graph Search)、百度公司的百度知心、搜狗公司的搜狗知立方等。這些應用的技術可能會有所差別,但相同的是它們在建構過程中都利用了Wikipedia、百度百科、互動百科等線上百科知識。是以本章将教大家分别爬取這三大線上百科。
百科是指天文、地理、自然、人文、宗教、信仰、文學等全部學科的知識的總稱,它可以是綜合性的,包含所有領域的相關内容;也可以是面向專業性的。接下來将介紹常見的三大線上百科,它們是資訊抽取研究的重要語料庫之一。
1.Wikipedia
“Wikipedia is a free online encyclopedia with the aim to allow anyone to edit articles.” 這是Wikipedia的官方介紹。Wikipedia是一個基于維基技術的多語言百科全書協作計劃,用多種語言編寫的網絡百科全書。Wikipedia一詞取自于該網站核心技術“Wiki”以及具有百科全書之意的“encyclopedia”共同創造出來的新混成詞“Wikipedia”,接受任何人編輯。
在所有線上百科中,Wikipedia知識準确性最好,結構化最好,但是Wikipedia本以英文知識為主,涉及的中文知識很少。線上百科頁面通常包括:Title(标題)、Description(摘要描述)、InfoBox(消息盒)、Categories(實體類别)、Crosslingual Links(跨語言連結)等。Wikipedia中實體“黃果樹瀑布”的中文頁面資訊如圖1所示。
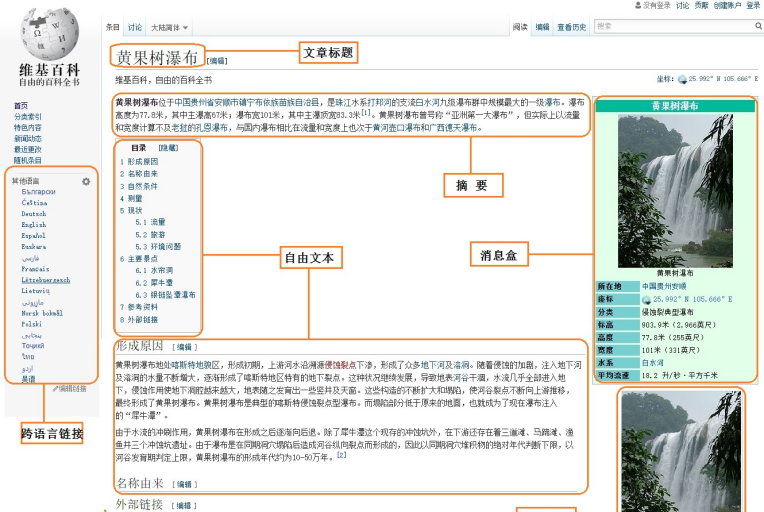
圖1所示的Wikipedia資訊主要包括:
- 文章标題(Article Title):唯一辨別一篇文章(除存在歧義的頁面),即對應一個實體,對應圖中的“黃果樹瀑布”。
- 摘要(Abstract):通過一段或兩段精簡的資訊對整篇文章或整個實體進行描述,它具有重要的使用價值。
- 自由文本(Free Text):自由文本包括全文本内容和部分文本内容。全文本内容是描述整篇文章的所有文本資訊,包括摘要資訊和各個部分的資訊介紹。部分文本内容是描述一篇文章的部分文本資訊,使用者可以自定義摘取。
- 分類标簽(Category Label):用于鑒定該篇文章所屬的類型,如圖中“黃果樹瀑布”包括的分類标簽有“國家5A級旅遊景區”、“中國瀑布”、“貴州旅遊”等。
- 消息盒(InfoBox):又稱為資訊子產品或資訊盒。它采用結構化形式展現網頁資訊,用于描述文章或實體的屬性和屬性值資訊。消息盒包含了一定數量的“屬性-屬性值”對,聚集了該篇文章的核心資訊,用于表征整個網頁或實體。
2.百度百科
百度百科是百度公司推出的一部内容開放、自由的網絡百科全書平台。截至2017年4月,百度百科已經收錄了超過1432萬的詞條,參與詞條編輯的網友超過610萬人,幾乎涵蓋了所有已知的知識領域。
百度百科旨在創造一個涵蓋各領域知識的中文資訊收集平台。百度百科強調使用者的參與和奉獻精神,充分調動網際網路使用者的力量,彙聚廣大使用者的頭腦智慧,積極進行交流和分享。同時,百度百科實作與百度搜尋、百度知道的結合,從不同的層次上滿足使用者對資訊的需求。

與Wikipedia相比,百度百科所包含中文知識最多最廣,但是準确性相對較差。百度百科頁面也包括:Title(标題)、Description(摘要描述)、InfoBox(消息盒)、Categories(實體類别)、Crosslingual Links(跨語言連結)等。圖2為百度百科“Python”網頁知識,該網頁的消息盒為中間部分,采用鍵值對(Key-value Pair)的形式,比如“外文名”對應的值為“Python”,“經典教材”對應的值為“Head First Python”等。
3.互動百科
互動百科(www.baike.com)是中文百科網站的開拓與領軍者,緻力于為數億中文使用者免費提供海量、全面、及時的百科資訊,并通過全新的維基平台不斷改善使用者對資訊的創作、擷取和共享方式。截止到2016年年底,互動百科已經發展成為由超過1100萬使用者共同打造的擁有1600萬詞條、2000萬張圖檔、5萬個微百科的百科網站,新媒體覆寫人群1000餘萬人,手機APP使用者超2000萬。
相對于百度百科而言,互動百科的準确性更高、結構化更好,在專業領域上知識品質較高,故研究者通常會選擇互動百科作為主要語料之一。圖3顯示的是互動百科的首頁。
互動百科的資訊分為兩種形式存儲,一種是百科中結構化的資訊盒,另一種是百科正文的自由文本。對于百科中的詞條文章來說,隻有少數詞條含有結構化資訊盒,但所有詞條均含有自由文本。資訊盒是采用結構化方式展現詞條資訊的形式,一個典型的百科資訊盒展示例子如圖4,顯示了Python的InfoBox資訊,采用鍵值對的形式呈現,比如Python的“設計人”為“Guido van Rossum”。
下面分别講解Selenium技術爬取三大線上百科的消息盒,三大百科的分析方法略有不同。Wikipedia先從清單頁面分别擷取20國集團(簡稱G20)各國家的連結,再依次進行網頁分析和資訊爬取;百度百科調用Selenium自動操作,輸入各種程式設計語言名,再進行通路定位爬取;互動百科采用分析網頁的連結url,再去到不同的景點進行分析及資訊抓取。
二.Selenium爬取百度百科知識
百度百科作為最大的中文線上百科或中文知識平台,它提供了各行各業的知識,可以供研究者從事各方面的研究。雖然詞條的準确率不是最好,但依然可以為從事資料挖掘、知識圖譜、自然語言處理、大資料等領域的學者提供很好的知識平台。
1.網頁分析
本小節将詳細講解Selenium爬取百度百科消息盒的例子,爬取的主題為10個國家5A級景區,其中景區的名單定義在TXT檔案中,然後再定向爬取它們的消息盒資訊。其中網頁分析的核心步驟如下:
(1) 調用Selenium自動搜尋百科關鍵詞
首先,調用Selenium技術通路百度百科首頁,網址為:
- https://baike.baidu.com
圖5為百度百科首頁,其頂部為搜尋框,輸入相關詞條如“故宮”,點選“進入詞條”,可以得到故宮詞條的詳細資訊。
然後,在浏覽器滑鼠選中“進入詞條”按鈕,右鍵滑鼠點選“審查元素”,可以檢視該按鈕對應的HTML源代碼,如圖6所示。注意,不同浏覽器檢視網頁控件或内容對應源代碼的稱呼是不同的,圖中使用的是360安全浏覽器,稱呼為“審查元素”,而Chrome浏覽器稱為“檢查”,QQ浏覽器稱為“檢查”等。
“進入詞條”對應的HTML核心代碼如下所示:
調用Selenium函數可以擷取輸入框input控件。
-
find_element_by_xpath
("//form[@id=‘searchForm’]/input")
然後自動輸入“故宮”,擷取按鈕“進入詞條”并自動點選,這裡采用的方法是在鍵盤上輸入Enter鍵即可通路“故宮”界面,核心代碼如下所示:
driver.get("http://baike.baidu.com/")
elem_inp=driver.find_element_by_xpath("//form[@id='searchForm']/input")
elem_inp.send_keys(name)
elem_inp.send_keys(Keys.RETURN)
複制
(2) 調用Selenium通路“故宮”頁面并定位消息盒
第一步完成後,進入“故宮”頁面然後找到中間消息盒InfoBox部分,右鍵滑鼠并點選“審查元素”,傳回結果如圖7所示。
消息盒核心代碼如下:
消息盒主要采用<屬性-屬性值>的形式存儲,詳細概括了“故宮”實體的資訊。例如,屬性“中文名稱”對應值為“北京故宮”,屬性“外文名稱”對應值為“Fobidden City”。對應的HTML部分源代碼如下。
整個消息盒位于< div class=“basic-info J-basic-info cmn-clearfix” >标簽中,接下來是< dl >、< dt >、< dd >一組合HTML标簽,其中消息盒div布局共包括兩個< dl >…</ dl >布局,一個是記錄消息盒左邊部分的内容,另一個< dl >記錄了消息盒右部分的内容,每個< dl >标簽裡再定義屬性和屬性值,如圖8所示。
注意:使用dt、dd最外層必須使用dl包裹,< dl >标簽定義了定義清單(Definition List),< dt >标簽定義清單中的項目,< dd >标簽描述清單中的項目,此組合标簽叫做表格标簽,與table表格組合标簽類似。
接下來調用Selenium擴充包的find_elements_by_xpath()函數分别定位屬性和屬性值,該函數傳回多個屬性及屬性值集合,再通過for循環輸出已定位的多個元素值。代碼如下:
elem_name=driver.find_elements_by_xpath("//div[@class='basic-info J-basic-info cmn-clearfix']/dl/dt")
elem_value=driver.find_elements_by_xpath("//div[@class='basic-info J-basic-info cmn-clearfix']/dl/dd")
for e in elem_name:
print(e.text)
for e in elem_value:
print(e.text)
複制
此時,使用Selenium技術爬取百度百科國家5A級景區的分析方法就講解完了,下面是這部分完整的代碼及一些難點。
2.代碼實作
注意,接下來我們嘗試定義多個Python檔案互相調用實作爬蟲功能。完整代碼包括兩個檔案,即:
- test10_01_baidu.py:定義了主函數main并調用getinfo.py檔案
- getinfo.py:通過getInfobox()函數爬取消息盒
test10_01_baidu.py
# -*- coding: utf-8 -*-
"""
test10_01_baidu.py
定義了主函數main并調用getinfo.py檔案
By:Eastmount CSDN 2021-06-23
"""
import codecs
import getinfo #引用子產品
#主函數
def main():
#檔案讀取景點資訊
source = open('data.txt','r',encoding='utf-8')
for name in source:
print(name)
getinfo.getInfobox(name)
print('End Read Files!')
source.close()
if __name__ == '__main__':
main()
複制
在代碼中調用“import getinfo”代碼導入getinfo.py檔案,導入之後就可以在main函數中調用getinfo.py檔案中的函數和屬性,接着我們調用getinfo.py檔案中的getInfobox()函數,執行爬取消息盒的操作。
getinfo.py
# coding=utf-8
"""
getinfo.py:擷取資訊
By:Eastmount CSDN 2021-06-23
"""
import os
import codecs
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#getInfobox函數: 擷取國家5A級景區消息盒
def getInfobox(name):
try:
#通路百度百科并自動搜尋
driver = webdriver.Firefox()
driver.get("http://baike.baidu.com/")
elem_inp = driver.find_element_by_xpath("//form[@id='searchForm']/input")
elem_inp.send_keys(name)
elem_inp.send_keys(Keys.RETURN)
time.sleep(1)
print(driver.current_url)
print(driver.title)
#爬取消息盒InfoBox内容
elem_name=driver.find_elements_by_xpath("//div[@class='basic-info J-basic-info cmn-clearfix']/dl/dt")
elem_value=driver.find_elements_by_xpath("//div[@class='basic-info J-basic-info cmn-clearfix']/dl/dd")
"""
for e in elem_name:
print(e.text)
for e in elem_value:
print(e.text)
"""
#建構字段成對輸出
elem_dic = dict(zip(elem_name,elem_value))
for key in elem_dic:
print(key.text,elem_dic[key].text)
time.sleep(5)
return
except Exception as e:
print("Error: ",e)
finally:
print('\n')
driver.close()
複制
比如爬取過程Firefox浏覽器會自動搜尋“故宮”頁面,如下圖所示:
最終輸出結果如下圖所示:
内容如下:
https://baike.baidu.com/item/北京故宮
北京故宮_百度百科
https://baike.baidu.com/item/%E5%8C%97%E4%BA%AC%E6%95%85%E5%AE%AB
北京故宮_百度百科
中文名 北京故宮
地理位置 北京市東城區景山前街4号 [91]
開放時間 4.1-10.31:08:20-17:00(停止售票16:00,最晚入園16:10) ;11.1-3.31:08:30-16:30(停止售票15:30,最晚入園15:40) ;除法定節假日外每周一閉館 [6] [91]
景點級别 AAAAA級
門票價格 60元旺季/40元淡季 [7]
占地面積 72萬平方米(建築面積約15萬平方米)
保護級别 世界文化遺産;第一批全國重點文物保護機關
準許機關 聯合國教科文組織;中華人民共和國國務院
批 号 III-100
主要藏品 清明上河圖、乾隆款金瓯永固杯、酗亞方樽
别 名 紫禁城 [8]
官方電話 010-85007057 [92]
複制
Python運作結果如下所示,其中data.txt檔案中包括了常見的幾個景點。
- 北京故宮
- 黃果樹瀑布
- 頤和園
- 八達嶺長城
- 明十三陵
- 恭王府
- 北京奧林匹克公園
- 黃山
上述代碼屬性和屬性值通過字典進行組合輸出的,核心代碼如下:
elem_dic = dict(zip(elem_name,elem_value))
for key in elem_dic:
print(key.text,elem_dic[key].text)
複制
同時,讀者可以嘗試調用本地的無界面浏覽器PhantomJS進行爬取的,調用方法如下:
webdriver.PhantomJS(executable_path="C:\...\phantomjs.exe")
複制
課程作業:
- 作者這裡教大家爬取了消息盒,同時百科知識的摘要及正文也非常重要,讀者不妨嘗試分别爬取。這些語料都将成為您後續文本挖掘或NLP領域的必備儲備,比如文本分類、實體對齊、實體消歧、知識圖譜建構等。
三.Selenium爬取Wikipedia
線上百科是網際網路中存在公開的最大資料量的使用者生成資料集合,這些資料具有一定的結構,屬于半結構化資料,最知名的三大線上百科包括Wikipedia 、百度百科、互動百科。首先,作者将介紹Selenium爬取Wikipedia的執行個體。
1.網頁分析
第一個執行個體作者将詳細講解Selenium爬取20國家集團(G20)的第一段摘要資訊,具體步驟如下:
(1) 從G20清單頁面中擷取各國超連結
20國集團清單網址如下,Wikipedia采用國家英文單詞首寫字母進行排序,比如“Japan”、“Italy”、“Brazil”等,每個國家都采用超連結的形式進行跳轉。
- https://en.wikipedia.org/wiki/Category:G20_nations
首先,需要擷取20個國家的超連結,然後再去到具體的頁面進行爬取。選中一個國家的超連結,比如“China”,右鍵滑鼠并點選“檢查”按鈕,可以擷取對應的HTML源代碼,如下所示。
其中超連結位于< div class=“mw-category-group” >布局的< ul >< li >< a >節點下,對應代碼:
調用Selenium的find_elements_by_xpath()函數擷取節點class屬性為“mw-category-group”的超連結,它将傳回多個元素。定位超連結的核心代碼如下:
driver.get("https://en.wikipedia.org/wiki/Category:G20_nations")
elem=driver.find_elements_by_xpath("//div[@class='mw-category-group']/ul/li/a")
for e in elem:
print(e.text)
print(e.get_attribute("href"))
複制
函數find_elements_by_xpth()先解析HTML的DOM樹形結構并定位到指定節點,并擷取其元素。然後定義一個for循環,依次擷取節點的内容和href屬性,其中e.text表示節點的内容,例如下面節點之間的内容為China。
<a href="/wiki/China" title="China">China</a>
複制
同時,e.get_attribute(“href”)表示擷取節點屬性href對應的屬性值,即“/wiki/China”,同理,e.get_attribute(“title”)可以擷取标題title屬性,得到值“China”。
此時将擷取的超連結存儲至變量中如下圖,再依次定位到每個國家并擷取所需内容。
(2) 調用Selenium定位并爬取各國頁面消息盒
接下來開始通路具體的頁面,比如中國:
- https://en.wikipedia.org/wiki/China
如圖所示,可以看到頁面的URL、标題、摘要、内容、消息盒等,其中消息盒在途中右部分,包括國家全稱、位置等。
下面采用<屬性-屬性值>對的形式進行描述,很簡明精準地概括了一個網頁實體,比如<首都-北京>、<人口-13億人>等資訊。通常擷取這些資訊之後,需要進行預處理操作,之後才能進行資料分析,後面章節将詳細講解。
通路到每個國家的頁面後,接下來需要擷取每個國家的第一段介紹,本小節講解的爬蟲内容可能比較簡單,但是講解的方法非常重要,包括如何定位節點及爬取知識。詳情頁面對應的HTML核心部分代碼如下:
浏覽器審查元素方法如圖所示。
正文内容位于屬性class為“mw-parser-output”的< div >節點下。在HTML中,< P >标簽表示段落,通常用于辨別正文,< b >标簽表示加粗。擷取第一段内容即定位第一個< p >節點即可。核心代碼如下:
driver.get("https://en.wikipedia.org/wiki/China")
elem=driver.find_element_by_xpath("//div[@class='mw-parser-output']/p[2]").text
print elem
複制
注意,正文第一段内容位于第二個< p >段落,故擷取p[2]即可。同時,如果讀者想從源代碼中擷取消息盒,則需擷取消息盒的位置并抓取資料,消息盒(InfoBox)内容在HTML對應為如下節點,記錄了網頁實體的核心資訊。
<table class="infobox gegraphy vcard">...</table>
複制
2.代碼實作
完整代碼參考檔案test10_02.py,如下所示:
# coding=utf-8
#By:Eastmount CSDN 2021-06-23
import time
import re
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.get("https://en.wikipedia.org/wiki/Category:G20_nations")
elem = driver.find_elements_by_xpath("//div[@class='mw-category-group']/ul/li/a")
name = [] #國家名
urls = [] #國家超連結
#爬取連結
for e in elem:
print(e.text)
print(e.get_attribute("href"))
name.append(e.text)
urls.append(e.get_attribute("href"))
print(name)
print(urls)
#爬取内容
for url in urls:
driver.get(url)
elem = driver.find_element_by_xpath("//div[@class='mw-parser-output']/p[1]").text
print(elem)
複制
其中,爬取的資訊如圖所示。
PS:該部分大家簡單嘗試即可,更推薦爬取百度百科、互動百科和搜狗百科。
四.Selenium爬取互動百科
幾年過去,互動百科變成了快懂百科,但還好網頁結構未變化。
1.網頁分析
目前,線上百科已經發展為衆多科研工作者從事語義分析、知識圖譜建構、自然語言處理、搜尋引擎和人工智能等領域的重要語料來源。互動百科作為最熱門的線上百科之一,為研究者提供了強大的語料支援。
本小節将講解一個爬取互動百科最熱門的十個程式設計語言頁面的摘要資訊,通過該執行個體加深讀者使用Selenium爬蟲技術的印象,更加深入地剖析網絡資料爬取的分析技巧。不同于Wikipedia先爬取詞條清單超連結再爬取所需資訊、百度百科輸入詞條進入相關頁面再進行定向爬取,互動百科采用的方法是:
- 設定不同詞條的網頁url,再去到該詞條的詳細界面進行資訊爬取
由于互動百科搜尋不同詞條對應的超連結是存在一定規律的,即采用 “常用url+搜尋的詞條名” 方式進行跳轉,這裡我們通過該方法設定不同的詞條網頁。具體步驟如下:
(1) 調用Selenium分析URL并搜尋互動百科詞條
我們首先分析互動百科搜尋詞條的一些規則,比如搜尋人物“貴州”,對應的超鍊為:
- http://www.baike.com/wiki/貴州
對應頁面如圖所示,從圖中可以看到,頂部的超連結URL、詞條為“貴州”、第一段為“貴州”的摘要資訊、“右邊為對應的圖檔等資訊。
同理,搜尋程式設計語言“Python”,對應的超連結為:
- http://www.baike.com/wiki/Python
可以得出一個簡單的規則,即:
- http://www.baike.com/wiki/詞條
可以搜尋對應的知識,如程式設計語言“Java”對應為:
- http://www.baike.com/wiki/Java
(2) 通路熱門Top10程式設計語言并爬取摘要
2016年,Github根據各語言過去12個月送出的PR數量進行排名,得出最受歡迎的Top10程式設計語言分别是:JavaScript、Java、Python、Ruby、PHP、C++、CSS、C#、C和GO語言。
然後,需要分布擷取這十門語言的摘要資訊。在浏覽器中選中摘要部分,右鍵滑鼠點選“審查元素”傳回結果如圖所示,可以在底部看到摘要部分對應的HTML源代碼。
新版本的“快懂百科”内容如下圖所示:
“Java”詞條摘要部分對應的HTML核心代碼如下所示:
調用Selenium的find_element_by_xpath()函數,可以擷取摘要段落資訊,核心代碼如下。
driver = webdriver.Firefox()
url = "http://www.baike.com/wiki/" + name
driver.get(url)
elem = driver.find_element_by_xpath("//div[@class='summary']/div/span")
print(elem.text)
複制
這段代碼的基本步驟是:
- 首先調用webdriver.Firefox()驅動,打開火狐浏覽器。
- 分析網頁超連結,并調用driver.get(url)函數通路。
- 分析網頁DOM樹結構,調用driver.find_element_by_xpath()進行分析。
- 輸出結果,部分網站的内容需要存儲至本地,并且需要過濾掉不需要的内容等。
下面是完整的代碼及詳細講解。
2.代碼實作
完整代碼為blog10_03.py如下所示,主函數main()中循環調用getgetAbstract()函數爬取Top10程式設計語言的摘要資訊。
# coding=utf-8
#By:Eastmount CSDN 2021-06-23
import os
import codecs
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
#擷取摘要資訊
def getAbstract(name):
try:
#建立檔案夾及檔案
basePathDirectory = "Hudong_Coding"
if not os.path.exists(basePathDirectory):
os.makedirs(basePathDirectory)
baiduFile = os.path.join(basePathDirectory,"HudongSpider.txt")
#檔案不存在建立,存在則追加寫入
if not os.path.exists(baiduFile):
info = codecs.open(baiduFile,'w','utf-8')
else:
info = codecs.open(baiduFile,'a','utf-8')
url = "http://www.baike.com/wiki/" + name
print(url)
driver.get(url)
elem = driver.find_elements_by_xpath("//div[@class='summary']/div/span")
content = ""
for e in elem:
content += e.text
print(content)
info.writelines(content+'\r\n')
except Exception as e:
print("Error: ",e)
finally:
print('\n')
info.write('\r\n')
#主函數
def main():
languages = ["JavaScript", "Java", "Python", "Ruby", "PHP",
"C++", "CSS", "C#", "C", "GO"]
print('開始爬取')
for lg in languages:
print(lg)
getAbstract(lg)
print('結束爬取')
if __name__ == '__main__':
main()
複制
其中“JavaScript”和“Java”程式設計語言的抓取結果如圖所示,該段代碼爬取了熱門十門語言在互動百科中的摘要資訊。
程式成功抓取了各個程式設計語言的摘要資訊,如下圖所示:
同時将資料存儲至本地TXT檔案中,這将有效為NLP和文本挖掘進行一步分析提供支撐。
寫到這裡,幾種常見的百科資料抓取方法就介紹完畢了,希望您喜歡。
五.總結
線上百科被廣泛應用于科研工作、知識圖譜和搜尋引擎建構、大小型公司資料內建、Web2.0知識庫系統中,由于其公開、動态、可自由通路和編輯、擁有多語言版本等特點,它深受科研工作者和公司開發人員的喜愛,常見的線上百科包括Wikipedia、百度百科和互動百科等。
本文結合Selenium技術分别爬取了Wikipedia的段落内容、百度百科的消息盒和互動百科的摘要資訊,并采用了三種分析方法,希望讀者通過該章節的案例掌握Selenium技術爬取網頁的方法。
- 消息盒爬取
- 文本摘要爬取
- 網頁多種跳轉方式
- 網頁分析及爬取核心代碼
- 檔案儲存
Selenium用得更廣泛的領域是自動化測試,它直接運作在浏覽器中(如Firefox、Chrome、IE等),就像真實使用者操作一樣,對開發的網頁進行各式各樣的測試,它更是自動化測試方向的必備工具。希望讀者能掌握這種技術的爬取方法,尤其是目标網頁需要驗證登入等情形。
該系列所有代碼下載下傳位址:
- https://github.com/eastmountyxz/Python-zero2one
參考文獻
- [1] [譯]Selenium Python文檔:目錄 - Tacey Wong - 部落格園
- [2] Baiju Muthukadan Selenium with Python Selenium Python Bindings 2 documentation
- [3] https://github.com/baijum/selenium-python
- [4] http://blog.csdn.net/Eastmount/article/details/47785123
- [5] Selenium實作自動登入163郵箱和Locating Elements介紹 - Eastmount
- [6] Selenium常見元素定位方法和操作的學習介紹 - Eastmount
- [7]《Python網絡資料爬取及分析從入門到精通(爬取篇)》Eastmount
- [8] 楊秀璋. 實體和屬性對齊方法的研究與實作[J]. 北京理工大學碩士學位論文,2016:15-40.
- [9] 徐溥. 旅遊領域知識圖譜建構方法的研究和實作[J]. 北京理工大學碩士學位論文,2016:7-24.
- [10] 胡芳魏. 基于多種資料源的中文知識圖譜建構方法研究[J]. 華東理工大學博士學位論文,2014:25-60.
- [11] 楊秀璋. [python爬蟲] Selenium常見元素定位方法和操作的學習介紹 - CSDN部落格[EB/OL]. (2016-07-10)[2017-10-14].