在特征空間增強資料集
- 論文标題:DATASET AUGMENTATION IN FEATURE SPACE
- 發表會議:ICLR workshop 2017
- 組織機構:University of Guelph
一句話評價:
一篇簡單的workshop文章,但是有一些啟發性的實驗結論。
簡介
最常用的資料增強方法,無論是CV還是NLP中,都是直接對原始資料進行各種處理。比如對圖像的剪切、旋轉、變色等,對文本資料的單詞替換、删除等等。對于原始資料進行處理,往往是高度領域/任務相關的,即我們需要針對資料的形式、任務的形式,來設計增強的方法,這樣就不具有通用性。比如對于圖像的增強方法,就沒法用在文本上。是以,本文提出了一種“領域無關的”資料增強方法——特征空間的增強。具體的話就是對可學習的樣本特征進行 1) adding noise, 2) interpolating, 3) extrapolating 來得到新的樣本特征。
文本提到的一個想法很有意思:
When traversing along the manifold it is more likely to encounter realistic samples in feature space than compared to input space. 在樣本所在的流形上移動,在特征空間上會比在原始輸入空間上移動,更容易遇到真實的樣本點。
我們知道,對原始的資料進行資料增強,很多時候就根本不是真實可能存在的樣本了,比如我們在NLP中常用的對文本進行單詞随機删除,這樣得到的樣本,雖然也能夠提高對模型學習的魯棒性,但這種樣本實際上很難在真實樣本空間存在。本文提到的這句話則提示我們,如果我們把各種操作,放在高維的特征空間進行,則更可能碰到真實的樣本點。文章指出,這種思想,Bengio等人也提過:“higher level representations expand the relative volume of plausible data points within the feature space, conversely shrinking the space allocated for unlikely data points.” 這裡我們暫且不讨論這個說法背後的原理,先不妨承認其事實,這樣的話就啟示我們,在特征空間進行資料增強,我們有更大的探索空間。
具體方法
其實這個文章具體方法很簡單,它使用的是encoder-decoder的架構,在(預訓練好的)encoder之後的樣本特征上進行增強,然後進行下遊任務。是以是先有了一個表示模型來得到樣本的特征,再進行增強,而不是邊訓練邊增強。架構結構如下:
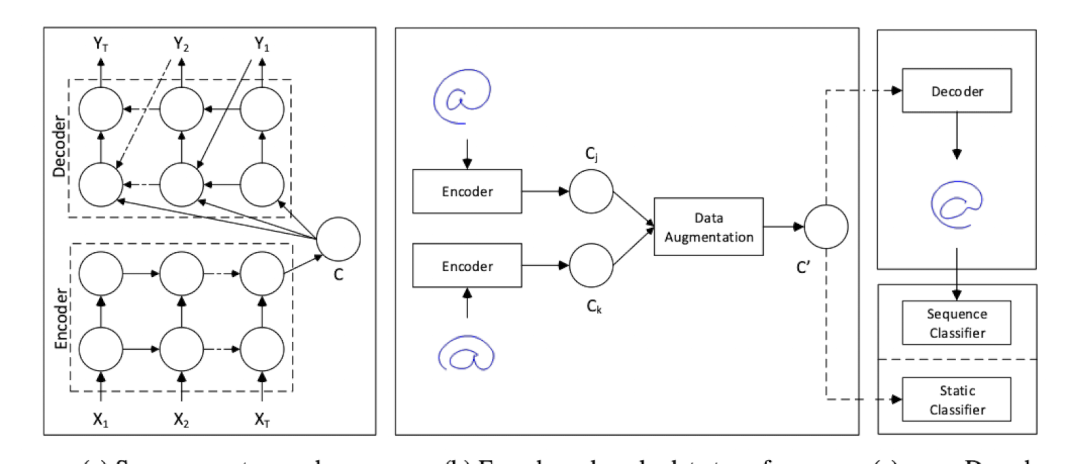
下面我們來看作者具體是怎麼增強的:
1. Adding Noise(加噪音)
直接在encoder得到的特征上添加高斯噪聲:
c^{'}_i = c_i + \gamma X, X \sim \mathcal{N}(0,\sigma ^2_i)
2. Interpolation(内插值)
在同類别點中,尋找K個最近鄰,然後任意兩個鄰居間,進行内插值:
c^{'} = (c_k - c_j)\lambda + c_j
3. Extrapolating(外插值)
跟内插的唯一差別在于插值的位置:
c^{'} = (c_j - c_k)\lambda + c_j
下圖表示了内插跟外插的差別:

在文本中,内插和外插都選擇\lambda = 0.5 .論文作者為了更加形象地展示這三種增強方式,使用正弦曲線(上的點)作為樣本,來進行上述操作,得到新樣本:
作者還借用一個手寫字母識别的資料集進行了可視化,進一步揭示interpolation和extrapolation的差別:
作者沒有具體說可視化的方法,猜測是通過autoencoder來生成的。可以看到,extrapolation得到的樣本,更加多樣化,而interpolation則跟原來的樣本對更加接近。
實驗
下面我們來看看使用這三種方式的增強效果。本文的實驗部分十分混亂,看得人頭大,是以我隻挑一些稍微清楚一些的實驗來講解。
實驗1:一個阿拉伯數字語音識别任務
實驗1
實驗2:另一個序列資料集
注:interpolation和extrapolation都是在同類别間進行的。
實驗結果:
- Adding Noise,效果一般。
- Interpolation,降低性能!
- Extrapolation,效果最好!
實驗3:跟在input space進行增強對比
實驗結果:
- 在特征空間進行extrapolation效果更好
- 特征空間的增強跟input空間的增強可以互補
實驗4:把增強的特征重構回去,得到的新樣本有用嗎
這個實驗還是有一點意思的,一個重要的結論就是,在特征空間這麼增強得到的特征,重構回去,屁用沒有。可以看到,都比最基礎的baseline要差,但是如果把測試集都換成重構圖,那麼效果就不錯。這其實不能怪特征增強的不好,而是重構的不好,因為重構得到的樣本,跟特征真實代表的樣本,肯定是有差距的,是以效果不好時可以了解的。
重要結論&讨論
綜上所有的實驗,最重要的實驗結論就是:在特征空間中,添加噪音,或是進行同類别的樣本的interpolation,是沒什麼增益的,甚至interpolation還會帶來泛化性能的降低。相反,extrapolation往往可以帶來較為明顯的效果提升。這個結論還是很有啟發意義的。
究其原因,interpolation實際上制造了更加同質化的樣本,而extrapolation得到的樣本則更加有個性,卻還保留了核心的特征,更大的多樣性有利于提高模型的泛化能力。
作者在結尾還提到他們做過一些進一步的探究,發現了一個有意思的現象:對于類别邊界非常簡單的任務(例如線性邊界、環狀邊界),interpolation是有幫助的,而extrapolation則可能有害。這也是可以了解的,因為在這種場景下,extrapolation很容易“越界”,導緻增強的樣本有錯誤的标簽。但是現實場景中任務多數都有着複雜的類别邊界,是以extrapolation一般都會更好一些。作者認為,interpolation會讓模型學習到一個更加“緊密”、“嚴格”的分類邊界,進而讓模型表現地過于自信,進而泛化性能不佳。
總之,雖然這僅僅是一篇workshop的論文,實驗也做的比較混亂,可讀性較差,但是揭示的一些現象以及背後原理的探讨還是十分有意義的。經典的資料增強方法mixup也部分收到了這篇文章的啟發,是以還是值得品味的。