1 賽題名稱
基于文本挖掘的企業隐患排查品質分析模型
2 賽題背景
企業自主填報安全生産隐患,對于将風險消除在事故萌芽階段具有重要意義。企業在填報隐患時,往往存在不認真填報的情況,“虛報、假報”隐患内容,增大了企業監管的難度。采用大資料手段分析隐患内容,找出不切實履行主體責任的企業,向監管部門進行推送,實作精準執法,能夠提高監管手段的有效性,增強企業安全責任意識。
3 賽題任務
本賽題提供企業填報隐患資料,參賽選手需通過智能化手段識别其中是否存在“虛報、假報”的情況。
看清賽題很關鍵,大家需要好好了解賽題目标之後,再去做題,可以避免很多彎路。
資料簡介
本賽題資料集為脫敏後的企業填報自查隐患記錄。
4 資料說明
訓練集資料包含“【id、level_1(一級标準)、level_2(二級标準)、level_3(三級标準)、level_4(四級标準)、content(隐患内容)和label(标簽)】”共7個字段。
其中“id”為主鍵,無業務意義;“一級标準、二級标準、三級标準、四級标準”為《深圳市安全隐患自查和巡查基本指引(2016年修訂版)》規定的排查指引,一級标準對應不同隐患類型,二至四級标準是對一級标準的細化,企業自主上報隐患時,根據不同類型隐患的四級标準開展隐患自查工作;“隐患内容”為企業上報的具體隐患;“标簽”辨別的是該條隐患的合格性,“1”表示隐患填報不合格,“0”表示隐患填報合格。
預測結果檔案results.csv
| 列名 | 說明 |
|---|---|
| id | 企業号 |
| label | 正負樣本分類 |
- 檔案名:results.csv,utf-8編碼
- 參賽者以csv/json等檔案格式,送出模型結果,平台進行線上評分,實時排名。
5 評測标準
本賽題采用F1 -score作為模型評判标準。
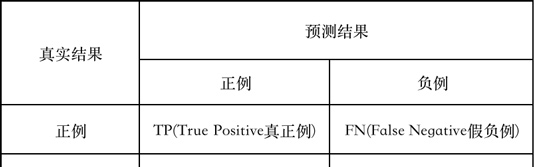
精确率P、召回率 R和 F1-score計算公式如下所示:

6 資料分析
- 檢視資料集
訓練集資料包含“【id、level_1(一級标準)、level_2(二級标準)、level_3(三級标準)、level_4(四級标準)、content(隐患内容)和label(标簽)】”共7個字段。測試集沒有label字段
-
标簽分布
我們看下資料标簽數量分布,看看有多少在劃水哈哈_
sns.countplot(train.label)
plt.xlabel('label count') 複制
在訓練集12000資料中,其中隐患填報合格的有10712條,隐患填報不合格的有1288條,差不多是9:1的比例,說明我們分類任務标簽分布式極其不均衡的。
-
文本長度分布
我們将
level_
content
train['text']=train['content']+' '+train['level_1']+' '+train['level_2']+' '+train['level_3']+' '+train['level_4']
test['text']=test['content']+' '+test['level_1']+' '+test['level_2']+' '+test['level_3']+' '+test['level_4']
train['text_len']=train['text'].map(len)
test['text'].map(len).describe() 複制
然後檢視下文本最大長度分布
count 18000.000000
mean 64.762167
std 22.720117
min 27.000000
25% 50.000000
50% 60.000000
75% 76.000000
max 504.000000
Name: text, dtype: float64 複制
train['text_len'].plot(kind='kde') 複制
7 基于BERT的企業隐患排查品質分析模型
完整代碼可以聯系作者擷取
7.1 導入工具包
import random
import numpy as np
import pandas as pd
from bert4keras.backend import keras, set_gelu
from bert4keras.tokenizers import Tokenizer
from bert4keras.models import build_transformer_model
from bert4keras.optimizers import Adam, extend_with_piecewise_linear_lr
from bert4keras.snippets import sequence_padding, DataGenerator
from bert4keras.snippets import open
from keras.layers import Lambda, Dense 複制
Using TensorFlow backend. 複制
7.2 設定參數
set_gelu('tanh') # 切換gelu版本 複制
num_classes = 2
maxlen = 128
batch_size = 32
config_path = '../model/albert_small_zh_google/albert_config_small_google.json'
checkpoint_path = '../model/albert_small_zh_google/albert_model.ckpt'
dict_path = '../model/albert_small_zh_google/vocab.txt'
# 建立分詞器
tokenizer = Tokenizer(dict_path, do_lower_case=True) 複制
7.3 定義模型
# 加載預訓練模型
bert = build_transformer_model(
config_path=config_path,
checkpoint_path=checkpoint_path,
model='albert',
return_keras_model=False,
) 複制
output = Lambda(lambda x: x[:, 0], name='CLS-token')(bert.model.output)
output = Dense(
units=num_classes,
activation='softmax',
kernel_initializer=bert.initializer
)(output)
model = keras.models.Model(bert.model.input, output)
model.summary() 複制
Model: "model_2"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
Input-Token (InputLayer) (None, None) 0
__________________________________________________________________________________________________
Input-Segment (InputLayer) (None, None) 0
__________________________________________________________________________________________________
Embedding-Token (Embedding) (None, None, 128) 2704384 Input-Token[0][0]
__________________________________________________________________________________________________
Embedding-Segment (Embedding) (None, None, 128) 256 Input-Segment[0][0]
__________________________________________________________________________________________________
Embedding-Token-Segment (Add) (None, None, 128) 0 Embedding-Token[0][0]
Embedding-Segment[0][0]
__________________________________________________________________________________________________
Embedding-Position (PositionEmb (None, None, 128) 65536 Embedding-Token-Segment[0][0]
__________________________________________________________________________________________________
Embedding-Norm (LayerNormalizat (None, None, 128) 256 Embedding-Position[0][0]
__________________________________________________________________________________________________
Embedding-Mapping (Dense) (None, None, 384) 49536 Embedding-Norm[0][0]
__________________________________________________________________________________________________
Transformer-MultiHeadSelfAttent (None, None, 384) 591360 Embedding-Mapping[0][0]
Embedding-Mapping[0][0]
Embedding-Mapping[0][0]
Transformer-FeedForward-Norm[0][0
Transformer-FeedForward-Norm[0][0
Transformer-FeedForward-Norm[0][0
Transformer-FeedForward-Norm[1][0
Transformer-FeedForward-Norm[1][0
Transformer-FeedForward-Norm[1][0
Transformer-FeedForward-Norm[2][0
Transformer-FeedForward-Norm[2][0
Transformer-FeedForward-Norm[2][0
Transformer-FeedForward-Norm[3][0
Transformer-FeedForward-Norm[3][0
Transformer-FeedForward-Norm[3][0
Transformer-FeedForward-Norm[4][0
Transformer-FeedForward-Norm[4][0
Transformer-FeedForward-Norm[4][0
__________________________________________________________________________________________________
Transformer-MultiHeadSelfAttent (None, None, 384) 0 Embedding-Mapping[0][0]
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward-Norm[0][0
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward-Norm[1][0
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward-Norm[2][0
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward-Norm[3][0
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward-Norm[4][0
Transformer-MultiHeadSelfAttentio
__________________________________________________________________________________________________
Transformer-MultiHeadSelfAttent (None, None, 384) 768 Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
__________________________________________________________________________________________________
Transformer-FeedForward (FeedFo (None, None, 384) 1181568 Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
Transformer-MultiHeadSelfAttentio
__________________________________________________________________________________________________
Transformer-FeedForward-Add (Ad (None, None, 384) 0 Transformer-MultiHeadSelfAttentio
Transformer-FeedForward[0][0]
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward[1][0]
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward[2][0]
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward[3][0]
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward[4][0]
Transformer-MultiHeadSelfAttentio
Transformer-FeedForward[5][0]
__________________________________________________________________________________________________
Transformer-FeedForward-Norm (L (None, None, 384) 768 Transformer-FeedForward-Add[0][0]
Transformer-FeedForward-Add[1][0]
Transformer-FeedForward-Add[2][0]
Transformer-FeedForward-Add[3][0]
Transformer-FeedForward-Add[4][0]
Transformer-FeedForward-Add[5][0]
__________________________________________________________________________________________________
CLS-token (Lambda) (None, 384) 0 Transformer-FeedForward-Norm[5][0
__________________________________________________________________________________________________
dense_7 (Dense) (None, 2) 770 CLS-token[0][0]
==================================================================================================
Total params: 4,595,202
Trainable params: 4,595,202
Non-trainable params: 0
__________________________________________________________________________________________________ 複制
# 派生為帶分段線性學習率的優化器。
# 其中name參數可選,但最好填入,以區分不同的派生優化器。
# AdamLR = extend_with_piecewise_linear_lr(Adam, name='AdamLR')
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=Adam(1e-5), # 用足夠小的學習率
# optimizer=AdamLR(learning_rate=1e-4, lr_schedule={
# 1000: 1,
# 2000: 0.1
# }),
metrics=['accuracy'],
) 複制
7.4 生成資料
def load_data(valid_rate=0.3):
train_file = "../data/train.csv"
test_file = "../data/test.csv"
df_train_data = pd.read_csv("../data/train.csv")
df_test_data = pd.read_csv("../data/test.csv")
train_data, valid_data, test_data = [], [], []
for row_i, data in df_train_data.iterrows():
id, level_1, level_2, level_3, level_4, content, label = data
id, text, label = id, str(level_1) + '\t' + str(level_2) + '\t' + \
str(level_3) + '\t' + str(level_4) + '\t' + str(content), label
if random.random() > valid_rate:
train_data.append( (id, text, int(label)) )
else:
valid_data.append( (id, text, int(label)) )
for row_i, data in df_test_data.iterrows():
id, level_1, level_2, level_3, level_4, content = data
id, text, label = id, str(level_1) + '\t' + str(level_2) + '\t' + \
str(level_3) + '\t' + str(level_4) + '\t' + str(content), 0
test_data.append( (id, text, int(label)) )
return train_data, valid_data, test_data 複制
train_data, valid_data, test_data = load_data(valid_rate=0.3) 複制
valid_data 複制
[(5,
'工業/危化品類(現場)—2016版\t(一)消防檢查\t2、防火檢查\t8、易燃易爆危險物品和場所防火防爆措施的落實情況以及其他重要物資的防火安全情況;\t防爆櫃裡面稀釋劑,機油費混裝',
0),
(3365,
'三小場所(現場)—2016版\t(一)消防安全\t2、消防通道和疏散\t2、疏散通道、安全出口設定應急照明燈和疏散訓示标志。\t4樓消防樓梯安全出口訓示牌壞',
0),
...] 複制
len(train_data) 複制
8403 複制
class data_generator(DataGenerator):
"""資料生成器
"""
def __iter__(self, random=False):
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
for is_end, (id, text, label) in self.sample(random):
token_ids, segment_ids = tokenizer.encode(text, maxlen=maxlen)
batch_token_ids.append(token_ids)
batch_segment_ids.append(segment_ids)
batch_labels.append([label])
if len(batch_token_ids) == self.batch_size or is_end:
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = sequence_padding(batch_segment_ids)
batch_labels = sequence_padding(batch_labels)
yield [batch_token_ids, batch_segment_ids], batch_labels
batch_token_ids, batch_segment_ids, batch_labels = [], [], [] 複制
# 轉換資料集
train_generator = data_generator(train_data, batch_size)
valid_generator = data_generator(valid_data, batch_size) 複制
valid_data 複制
[(5,
'工業/危化品類(現場)—2016版\t(一)消防檢查\t2、防火檢查\t8、易燃易爆危險物品和場所防火防爆措施的落實情況以及其他重要物資的防火安全情況;\t防爆櫃裡面稀釋劑,機油費混裝',
0),
(8,
'工業/危化品類(現場)—2016版\t(一)消防檢查\t2、防火檢查\t2、安全疏散通道、疏散訓示标志、應急照明和安全出口情況;\t已整改',
1),
(3365,
'三小場所(現場)—2016版\t(一)消防安全\t2、消防通道和疏散\t2、疏散通道、安全出口設定應急照明燈和疏散訓示标志。\t4樓消防樓梯安全出口訓示牌壞',
0),
...] 複制
7.5 訓練和驗證
evaluator = Evaluator()
model.fit(
train_generator.forfit(),
steps_per_epoch=len(train_generator),
epochs=2,
callbacks=[evaluator]
) 複制
model.load_weights('best_model.weights')
# print(u'final test acc: %05f\n' % (evaluate(test_generator)))
print(u'final test acc: %05f\n' % (evaluate(valid_generator))) 複制
final test acc: 0.981651 複制
print(u'final test acc: %05f\n' % (evaluate(train_generator))) 複制
完整代碼可以聯系作者擷取