Swin Transformer V2: Scaling Up Capacity and Resolution
作者:elfin
論文位址: https://arxiv.org/abs/2111.09883
如V2名字所言,這裡增大了模型的備援和輸入的分辨率!
V1論文解析參
V1主要的貢獻是shifted window,transformer部分也加入了圖像的相對位置偏置,為什麼是相對位置偏置,這個問題在NLP方向有足夠的研究表面相對位置比絕對位置work的更好。位置資訊對于transformer這種結構至關重要,因為它對序列位置不敏感,這是結構設計上的硬傷,而序列模組化位置是非常重要的,這是由源資料特點就決定的!關于transformer有許多改進,包括對輸入的前處理、attention追加偏置資訊等。我們注意到模型要做的就是兩件事:token内模組化和token間模組化!QKV的設計是在self-attention上實作了token間模組化,前進行中往往使用了token内模組化,即以\(QW^{Q}\)的形式先對token内資訊提取,與attention機制互補!V1、V2都是采用了這種形式!那麼我們為什麼不采用形如\(W^{Q}Q\)的計算方式進行token間的模組化呢?首先這裡與attention的性能重合,其次不能與attention互補,并且參數量會有指數級的增長,計算量相應增加,這是一個不nice的操作...
Swin Transformer的三個主要創新點:
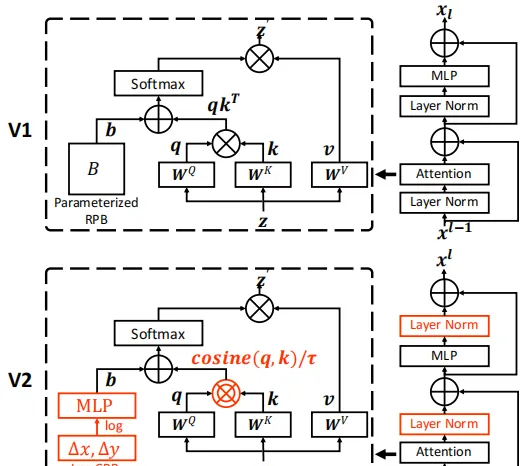
- res-post-norm:後置的标準化處理,文中指将LN層放在殘差分支的末端而不是開頭;
- 餘弦注意力:将原transformer的Q、K點積生成注意力換成餘弦的注意力計算模式;
- log-CPB: 對數間隔連續位置偏置,替換了原來的相對位置偏置,以應對視窗尺寸變換很大的情況,在視窗尺寸變化較大時對數縮放會将差異變的很小,使模型可控!
Swin Transformer結合的三個主要新技術點:
- zero-optimizer:零優化技術;https://dl.acm.org/doi/10.5555/3433701.3433727
- activation check pointing:
- self-attention:自注意力的新實作.
目錄
- 摘要
- 一、介紹
- 二、相關工作
- 三、Swin Transformer V2
- 3.1 Swin Transformer的簡短說明
- 3.2 擴充模型容量
- 3.3 擴充視窗分辨率
- 3.4 自監督預訓練
- 3.5 節省GPU記憶體的實作
- 四、我誇我自己階段
摘要
大規模NLP模型已經被證明可以顯著提高語言任務的性能,并且沒有飽和的迹象。他們還展示了驚人的少樣本(few-shot)學習能力,就像人類一樣。本文旨在探索計算機視覺中的大規模模型。我們解決了大型視覺模型訓練和應用中的三個主要問題,包括訓練不穩定性、預訓練和微調之間的分辨率差距以及對标記資料的饑餓感。提出了三種主要技術:1) 殘差後範數法結合餘弦注意提高訓練穩定性; 2) 一種對數間隔連續位置偏差方法,用于有效地将使用低分辨率圖像預先訓練的模型傳輸到具有高分辨率輸入的下遊任務;3) 一種自我監督的預訓練方法SimMIM,用于減少對大量标記圖像的需求。通過這些技術,本文成功地訓練了一個30億參數的Swin Transformer V2模型,這是迄今為止最大的稠密視覺模型,并使其能夠使用高達1536×1536分辨率的圖像進行訓練。它在ImageNet-V2圖像分類、COCO目标檢測、ADE20K語義分割和Kinetics-400視訊動作分類等4項具有代表性的視覺任務上創造了新的性能記錄。還要注意的是,我們的訓練效率遠遠高于谷歌的十億級視覺模型,後者消耗的标簽資料少了40倍,訓練時間少了40倍。
這裡微軟十分嚣張地内涵了谷歌,雖然我們不知道大佬是錨定的那個項目(猜測他說的應該是scaling vision transformer: https://arxiv.org/pdf/2106.04560.pdf),但是較好的模型還是有不少的,這裡我就随便拿一個來比劃比劃:
Model# Params(M)GFLOPsTop1 Acc(%)DatasetswindowsVAN-Large44.89.083.9ImageNetSwinV2-S5011.583.7ImageNet-1k8 x 8SwinV2-S5012.684.1ImageNet-1k16 x 16ConvNeXt-S508.983.1ImageNet-1k
這裡我們可以看出SwinV2-S比VAN-Large模型多了\(\frac{1}{3}\)的計算量,精度提升了千分之二,兩種模型性能相當!
Model# Params(M)GFLOPsmIoUDatasetsVAN-Large + UperNet74.7257.750.1ADE20KSwin-S + UperNet81103847.64ADE20KSwin-B + UperNet121184150.4ADE20KSwinV2-L + UperNet24055.9ADE20K
這裡我們沒有V2的語義分割,在V1層面上,明顯V1被VAN模型超越了!即使是SwinV2-L模型的性能,我們有信心VAN的大模型(還沒有釋出)也将有類似的性能!
Top
---
Bottom
一、介紹
擴充語言模型取得了難以置信的成功。它顯著提高了模型在語言任務上的表現[19、24、49、50、52、53],模型展示了與人類相似的驚人的少樣本學習能力[7]。自擁有3.4億個參數的BERT大型模型以來,語言模型在幾年内迅速擴大了1000倍以上,達到5300億個密集參數[50]和1.6萬億個稀疏參數[24]。研究還發現,這些大型語言模型在廣泛的語言任務中,具有越來越強的類似于人類智能的少樣本學習能力[7]。
另一方面,視覺模型的擴充一直滞後。雖然人們早就認識到,較大的視覺模型通常在視覺任務上表現更好[29,60],但最近,絕對模型大小剛剛能夠達到約10-20億個參數[17,27,39,56,80]。更重要的是,與大型語言模型不同,現有的大型視覺模型僅應用于圖像分類任務[17、56、80]。
為了成功地訓練大型和通用的視覺模型,我們需要解決幾個關鍵問題。首先,我們使用大型視覺模型進行的實驗揭示了訓練中的不穩定性問題。我們發現,在大型模型中,跨層激活幅度的差異變得顯著更大。仔細觀察原始架構可以發現,這是由直接添加回主分支的殘差單元的輸出引起的。結果是激活值逐層累積,是以深層的振幅明顯大于早期的振幅。為了解決這個問題,我們提出了一種新的規範化配置,稱為res-post-norm,它将LN層從每個剩餘單元的開頭移動到後端,如圖1所示。我們發現這種新配置在網絡層上産生的激活值要輕得多。我們還提出了一種縮放餘弦注意來取代以前的點積注意。縮放餘弦注意使得計算與塊輸入的振幅無關,并且注意值不太可能陷入極端。在我們的實驗中,提出的兩種技術不僅使訓練過程更加穩定,而且還提高了精度,尤其是對于較大的模型。
fig1 transformer模型架構圖
其次,許多下遊視覺任務,如目标檢測和語義分割,都需要高分辨率的輸入圖像或大的注意窗。低分辨率預訓練和高分辨率微調之間的視窗大小變化可能相當大。目前的常見做法是對位置偏置特征圖進行雙三次插值[22,46]。這個簡單的修複有點特别,結果通常是次優的。我們引入了一種對數間隔連續位置偏差(log-CPB:continuous position bias),它通過在對數間隔坐标輸入上應用一個小型元網絡,為任意坐标範圍生成偏內插補點。由于元網絡采用任何坐标,預先訓練的模型将能夠通過共享元網絡的權重在視窗大小之間自由傳遞。我們方法的一個關鍵設計是将坐标轉換為對數空間,這樣即使目标視窗大小明顯大于訓練前的視窗大小,外推率也可以很低。模型容量和分辨率的擴大也會導緻現有視覺模型的GPU記憶體消耗過高。為了解決記憶體問題,我們結合了一些重要的技術,包括零優化器【54】、激活檢查點【12】和序列self-attention計算的新實作。使用這些技術,可以顯著降低大型模型和分辨率的GPU記憶體消耗,對訓練速度的影響微乎其微。
利用上述技術,我們成功地訓練了一個30億的Swin Transformer模型,并使用Nvidia A100-40G GPU将其有效地轉移到各種圖像分辨率高達1536×1536的視覺任務中。在我們的模型預訓練中,我們還采用了自監督預訓練來減少對超大标記資料的依賴。與之前的實踐(JFT-3B)相比,标簽資料減少了40倍,30億模型在廣泛的視覺基準上達到了最先進的精度。具體而言,它在ImageNet-V2圖像分類驗證集[55]上獲得了84.0%的top-1準确率,在COCO測試開發對象檢測集上獲得了63.1/54.4 bbox/mask AP,在ADE20K語義分割上獲得了59.9mIoU,在Kinetics-400視訊動作分類上獲得了86.8%的top-1準确率,比原Swin Transformer中的最佳數字高出了分别為+NA%、+4.4/+3.3、,+6.3和+1.9,并比之前的最佳記錄高出+0.8%([80])、+1.8/+1.4([74])、+1.5([4])和+1.4%([57])。
通過擴大視覺模型的容量和分辨率,使其在一般視覺任務上具有強大的性能,就像一個好的語言模型在一般NLP任務上的性能一樣,我們旨在促進這方面的更多研究,以便最終縮小視覺模型和語言模型之間的容量差距,并促進這兩個領域的聯合模組化。
二、相關工作
語言網絡和擴充 自[65]的開創性工作以來,transformer一直作為一個标準網絡。自那時起,對這種體系結構進行縮放的探索就開始了,有效的自我監督學習方法的發明,如mask或自回歸語言模組化,加速了這一進展[19(BERT), 52],縮放定律的發現進一步鼓勵了這一進展[36]。從那時起,語言模型的容量在幾年内急劇增加了1000多倍,從BERT-340M到Megatron-Turing-530B[7、49、50、53]和稀疏開關變壓器-1.6T(sparse Switch-Transformer-1.6T)[24]。随着能力的提高,各種國文基準的準确性已大大提高。零樣本或少樣本的表現也得到了顯著改善[7],這是人類通用智能的基礎。
視覺網絡和擴充 CNN一直是标準的計算機視覺網絡[40,41]。自AlexNet[40]以來,體系結構變得越來越深、越來越大,極大地推進了各種視覺任務,并在很大程度上推動了計算機視覺領域的深度學習浪潮,如VGG[60]、GoogleNet[62] 和ResNet。在過去兩年中,CNN架構進一步擴充到大約10億個參數[27,39],然而,絕對性能可能并不那麼令人鼓舞,這可能是由于CNN架構中的歸納偏差限制了模組化能力。
去年,Transformers開始接手一個又一個具有代表性的視覺基準,包括ImageNet-1K圖像級分類基準[22]、COCO區域級目标檢測基準[46]、ADE20K像素級語義分割基準[46、83]、Kinetics-400視訊動作分類基準[2]等,已經提出了許多視覺transformer變體,以在相對較小的範圍内提高精度[14、21、34、42、63、68、71、75、77、78、82]。隻有少數作品試圖放大視覺transformer[17,56,80]。然而,它們依賴于具有分類标簽的巨大圖像資料集(即JFT-3B),并且僅适用于圖像分類問題。
變換跨視窗/核分辨率 對于CNN,以前的工作通常在預訓練和微調期間固定核心大小。全局視覺變換器,如ViT[22],可以全局計算注意力,等效的注意力視窗大小與增加的輸入圖像分辨率成線性比例。對于局部vision Transformer架構,如Swin Transformer[46],視窗大小可以在微調期間固定或更改。允許可變視窗大小在使用中更友善,這樣就可以被可能可變的整個特征圖整除,并調整感受野以獲得更好的精确度。為了處理預訓練和微調之間的可變視窗大小,雙三次插值是預訓練的常見做法[22,46]。在本文中,我們提出了一種對數間隔連續位置偏差方法(log-CPB),該方法可以在低分辨率下更平滑地傳遞預先訓練的模型權重,以處理高分辨率視窗。
偏置項學習 研究NLP中的偏置項,與原始transformer中使用的絕對位置嵌入法相比,相對位置偏置法證明是有益的[53]。在計算機視覺中,相對位置偏差方法更常用[31,46,75],這可能是因為視覺信号的空間關系在視覺模組化中起着更重要的作用。通常的做法是直接将偏置值學習為模型權重。還有一些作品專門研究如何設定和學習偏差項[38,69]。
連續卷積和變體 我們的Log-CPB方法還與早期關于連續卷積和變體的工作有關【30、45、58、67】,這些工作利用元網絡來處理不規則資料點。我們的Log-CPB方法受到了這些努力的啟發,同時解決了在任意視窗大小的視覺transformer中轉移相對位置偏差的不同問題。我們還提出了對數間隔坐标,以減輕在大尺寸變化之間轉換時外推的困難。
綜上,我們了解了V2的技術背景,下面我們将看看作者怎麼完成V2的架構設計
Top
---
Bottom
三、Swin Transformer V2
3.1 Swin Transformer的簡短說明
Swin Transformer是一種通用的計算機視覺主幹,在區域級目标檢測、像素級語義分割和圖像級圖像分類等各種粒度識别任務中取得了優異的性能。Swin Transformer的主要思想是将幾個重要的視覺先驗引入到vanilla Transformer編碼器中,包括層次、位置和平移不變性,這将兩者的優點結合在一起:基本Transformer單元具有強大的模組化能力,視覺先驗使其對各種視覺任務都很友好。
标準化配置 衆所周知,标準化技術[3、35、64、70]對于穩定地訓練更深層次的體系結構至關重要。原始的Swin Transformer繼承了language Transformers[52] 和 vanilla ViT[22] 中的常見做法,在不進行廣泛研究的情況下使用了預标準化配置,如上圖所示。在以下小節中,我們将研究此預設規範化配置是否合适。
相對位置偏置 這是Swin V1的關鍵技術點,關于相對位置偏置在V1中我們詳細地解釋過了,現在再回顧一次。
相對位置偏置初始化
# 2*Wh-1 * 2*Ww-1, nH
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads))
trunc_normal_(self.relative_position_bias_table, std=.02)
self.relative_position_bias_table使用了截斷正太分布進行初始化,标準差為0.02。這裡我們要注意相對位置偏置是一個nn.Parameter的參數,也即相對位置偏置是逐漸學習得到!
\(M\)辨別視窗的大小,那麼初始化的偏置矩陣是\(\hat{B} \in \mathbb{R}^{\left( 2M-1\right)\times \left( 2M-1\right)}\),為什麼是\(\left( 2M-1\right)\times \left( 2M-1\right)\)?後面再說明這個問題!
WindowAttention層最主要的就是相對位置偏置的編碼部分比較複雜,其他操作都是我們熟悉的torch層,是以,這裡仔細研究其處理過程。
擷取相對位置偏置
相對位置偏置\(B\)是從\(\hat{B}\)的一個token。是以\(\hat{B}\)存儲了所有的偏置,\(B\)要通過索引擷取。下面是索引的生成:
coords:記錄了視窗的坐标,原點為視窗左上角;
coords_flatten:記錄了坐标的平鋪;sahpe為 ( 2, \(M^{2}\));
relative_coords:記錄了視窗内的像素的相對位置;如像素 \(patch_{a}\) 有\(M^{2}\)個相對位置,因為視窗内有\(M^{2}\)個像素。
注:這裡我第一次看的時候能夠了解,後面在面試過程中被問到是如何實作的,我的記憶是有較大偏差的,這導緻了面試的不成功。再次看部落格時,發現自己有點看不懂這些操作。為了更直白展示,下面我們詳細展示源碼及其示例。
# 假設M為5x5的
>>> coords_h = torch.arange(5) # 縱坐标張量tensor([0, 1, 2, 3, 4])
>>> coords_w = torch.arange(5) # 橫坐标張量tensor([0, 1, 2, 3, 4])
>>> coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
>>> coords
tensor([[[0, 0, 0, 0, 0],
[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[4, 4, 4, 4, 4]],
[[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4]]])
# 即coords[:, i, j]可以擷取window内第i行第j列元素相對視窗左上角的相對坐标
>>> coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
# 此時coords_flatten記錄了window内所有像素點平鋪後對應的坐标,如:coords_flatten[:, i*J+j]表示第i行第j列元素相對視窗左上角的相對坐标,J是列的次元
# 上面的coords_flatten是相對左上角的坐标,即絕對位置坐标,但是我們需要相對位置坐标,每一個點都有Wh*Ww個相對位置。而我們又有Wh*Ww個點,是以應該有(Wh*Ww) x (Wh*Ww)個坐标
>>> relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
# relative_coords.shape=[2, 25, 25],張量太大不友善展示,那麼為什麼上式可以實作相對位置坐标呢?
# 這是因為coords_flatten[:, :, None]的次元為shape=[2, 25, 1]相當于從25個點中循環選擇一個像素點的坐标;coords_flatten[:, None, :]的shape=[2, 1, 25]相當于循環每一個像素點的坐标被前面循環中的坐标相減。注意這裡比較白話,但也可能有點繞,這個是廣播機制,可以檢視torch、numpy是如何廣播的!
>>> relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
# 坐标軸轉換這個好了解,将最後一個軸表示橫縱坐标x,y的相對坐标,relative_coords[i,j,:]表示平鋪後第i個像素相對于第j個像素的相對坐标
>>> relative_coords[:, :, 0] += 5 - 1 # 将相對位置坐标重置為從0開始
# 加上5 - 1相對位置坐标就從0開始了是因為,對于縱坐标而言,最大是4,最小是0,是以最小的相對位置坐标是-4
>>> relative_coords[:, :, 1] += 5 - 1 # 橫坐标同理
>>> relative_coords[:, :, 0] *= 2 * 5 - 1 # 為什麼要乘以 2 * 5 - 1(2* self.window_size[1] - 1)?見下面的詳解
>>> relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww 得到兩兩像素間的相對位置偏置的索引
為什麼要乘以 2 * 5 - 1(2 self.window_size[1] - 1)?*
首先我們考慮2* self.window_size[1] - 1是什麼?以及相對位置偏置我們要怎麼表示?
- 區間[0, 2* self.window_size[1] - 1)是橫坐标(寬度所在軸)的相對位置取值範圍;原來的取值範圍是[1-self.window_size[1], self.window_size[1]-1],加上self.window_size[1] -1後就是[0, 2* self.window_size[1] - 2], 即2* self.window_size[1] - 1是取不到的,是以在寬度這個軸上不同的相對位置坐标有2* self.window_size[1] - 1個!
- 我們想要的是相對位置偏置,偏置是由self.relative_position_bias_table表格決定的,relative_position_index是索引,是以我們自然是希望兩兩之間的相對位置索引不一樣(因為兩兩之間相對位置不一樣)。這裡relative_coords橫縱坐标直接相加也可以得到索引,但是這個是以将大量重複。假設我們以寬度所在軸為基準進行處理,由上一條表訴我們直到乘以2* self.window_size[1] - 1,縱坐标就擴大了2* self.window_size[1] - 1倍,此時不同行間的縱坐标內插補點就是2* self.window_size[1] - 1,這意味這相鄰行間可以辨別2* self.window_size[1] - 1個資料,relative_coords.sum(-1)就恰好将所有間隔補齊了!用白話說就是我們希望索引是連續的,那麼不同的relative_coords坐标有多少呢?應該有\((2* self.window_size[1] - 1)^{2}\)個!這裡我們要考慮空間相對位置,比如右下角這種位置關系最終得到的索引應該是一樣的,是以為了歸納這種關系,作者采用了将高這個軸的坐标乘以寬的取值範圍,再加上寬、高的坐标值得到索引,直覺觀察為:
[[40,39,38,37,36,31,30,29,28,27,22,21,20,19,18,13,12,11,10, 9, 4, 3, 2, 1, 0],
[41,40,39,38,37,32,31,30,29,28,23,22,21,20,19,14,13,12,11,10, 5, 4, 3, 2, 1],
[42,41,40,39,38,33,32,31,30,29,24,23,22,21,20,15,14,13,12,11, 6, 5, 4, 3, 2],
[43,42,41,40,39,34,33,32,31,30,25,24,23,22,21,16,15,14,13,12, 7, 6, 5, 4, 3],
[44,43,42,41,40,35,34,33,32,31,26,25,24,23,22,17,16,15,14,13, 8, 7, 6, 5, 4],
[49,48,47,46,45,40,39,38,37,36,31,30,29,28,27,22,21,20,19,18,13,12,11,10, 9],
[50,49,48,47,46,41,40,39,38,37,32,31,30,29,28,23,22,21,20,19,14,13,12,11,10],
[51,50,49,48,47,42,41,40,39,38,33,32,31,30,29,24,23,22,21,20,15,14,13,12,11],
[52,51,50,49,48,43,42,41,40,39,34,33,32,31,30,25,24,23,22,21,16,15,14,13,12],
[53,52,51,50,49,44,43,42,41,40,35,34,33,32,31,26,25,24,23,22,17,16,15,14,13],
[58,57,56,55,54,49,48,47,46,45,40,39,38,37,36,31,30,29,28,27,22,21,20,19,18],
[59,58,57,56,55,50,49,48,47,46,41,40,39,38,37,32,31,30,29,28,23,22,21,20,19],
[60,59,58,57,56,51,50,49,48,47,42,41,40,39,38,33,32,31,30,29,24,23,22,21,20],
[61,60,59,58,57,52,51,50,49,48,43,42,41,40,39,34,33,32,31,30,25,24,23,22,21],
[62,61,60,59,58,53,52,51,50,49,44,43,42,41,40,35,34,33,32,31,26,25,24,23,22],
[67,66,65,64,63,58,57,56,55,54,49,48,47,46,45,40,39,38,37,36,31,30,29,28,27],
[68,67,66,65,64,59,58,57,56,55,50,49,48,47,46,41,40,39,38,37,32,31,30,29,28],
[69,68,67,66,65,60,59,58,57,56,51,50,49,48,47,42,41,40,39,38,33,32,31,30,29],
[70,69,68,67,66,61,60,59,58,57,52,51,50,49,48,43,42,41,40,39,34,33,32,31,30],
[71,70,69,68,67,62,61,60,59,58,53,52,51,50,49,44,43,42,41,40,35,34,33,32,31],
[76,75,74,73,72,67,66,65,64,63,58,57,56,55,54,49,48,47,46,45,40,39,38,37,36],
[77,76,75,74,73,68,67,66,65,64,59,58,57,56,55,50,49,48,47,46,41,40,39,38,37],
[78,77,76,75,74,69,68,67,66,65,60,59,58,57,56,51,50,49,48,47,42,41,40,39,38],
[79,78,77,76,75,70,69,68,67,66,61,60,59,58,57,52,51,50,49,48,43,42,41,40,39],
[80,79,78,77,76,71,70,69,68,67,62,61,60,59,58,53,52,51,50,49,44,43,42,41,40]]
為了說明,下面我們以下圖圖示進行說明:

Swin Transformer V2
- 主隊角線(40所在的紅色曲線)全是40,這意味着所有的關系是一緻的,那麼它代表了什麼位置關系呢?根據index張量的坐标我們知道它辨別的是\((i,i)\)的關系,即任意token自己與自己的相對位置!
- 緊挨主對角線的橙色曲線即辨別\((i,i+1)\)的關系,即任意token與下一個token的關系;但是我們注意這條線上可不是全為39,這裡出現了35!35出現的位置不難發現全是token在空間中換行的位置!
- 這裡要重點關注38所在是綠色曲線,它辨別的是token與之後兩位的token之間的關系;同時這裡面有34,而且數量比之前較多,這是為什麼?實際上,我們的相對位置主要關注了兩個方面:1)token1領先token2幾個位置;2) token1與token2間相差幾行!
\((2M-1)^{2}\)種偏置的證明
這種相對位置的偏置應該講解的比較清楚了,現在就回到之前的問題了,為什麼是\((2M-1)^{2}\) ?前面說了有\((2M-1)^{2}\)
- 我們用\((i,j)\)辨別\(token_{i}\)與\(token_{j}\)之間的關系,那麼所有的關系可以辨別如下:
(i, i-M*M+1), (i, i-1), (i,i), (i, i+1), ..., (i, i+M*M-1)
這裡我們将關系分為了\(2M^{2}-1\)類,但是這明顯不等于\((2M-1)^{2}\)
至此,我們完全證明了對于視窗大小為M的transformer結構,相對位置偏置應該有\((2M-1)^{2}\)個!
- 當\(i!=j\)時,\((i,j)\)就一定會跨行,同一類中的跨行如果不同步,則類中應該有兩種關系,因為同一類中,\(j-i\)是一個常數,是以我們需要知道\(2M^{2}-1\)類中有多少是不同步跨行的,通過一個簡單的減法我們知道,應該是有\(2M^{2}-4M+2\)個類有兩種關系!那麼這個資料是如何得出的?
- 當\(j-i=k \times M, k \in Z\),\(Z\)表示整數集,類中不會出現兩種關系!因為\(token_{i}\)與\(token_{j}\)換行是同步的!\(j-i=k \times M, k \in Z\)換一種表達方式就是token同列!同列的情況,共有\((2M^{2}-1) //M=2M-1\)類沒有兩種關系!
- 另一種不會出現兩種關系的發生在token邊界,如上圖中的右上角與左下角,分别會有\(M\)類不會有兩種關系(為什麼?這應該是易得吧!自己想想),但是這兩個角包含了兩種同列的情況,是以這裡我們有\(2M-2\)個類不會有兩種關系!
是以隻有一種關系的類有\((2M-2) + (2M-1) = 4M-3\)個,是以,關系的種類共有:
\[2 \times (2M^{2} -1) - (4M-3) =4M^{2} -4M + 1 = (2M-1)^{2}
\]
結合V1論文解讀,我們似乎從兩個角度對相對位置編碼進行了解讀,相信已經說的比較清楚了!
Top
---
Bottom
擴大模型容量和視窗分辨率
當我們放大Swin transformer的容量和視窗分辨率時,我們觀察到兩個問題。
- 放大模型容量時的不穩定性問題。當我們将原始Swin Transformer模型從小尺寸放大到大尺寸時,深層的激活值會顯著增加。振幅最高和最低的層之間的差異達到了1e4的極值。當我們将其進一步擴大到一個巨大的規模(6.58億個參數)時,它無法完成教育訓練。
- 跨視窗分辨率轉換模型時性能降低。如表1第一行所示,當我們通過雙三次插值方法在更大的圖像分辨率和視窗大小下直接測試預訓練的ImageNet-1K模型(256×256圖像,8×8視窗大小)的精度時,精度顯著降低。這值得我們重新檢查原始Swin Transformer中的相對位置偏差方法。
Top
---
Bottom
3.2 擴充模型容量
如第3.1節所述,V1(和大多數視覺transformer)在每個塊的開頭采用了一個LayerNorm層,繼承自vanilla ViT。當我們擴大模型容量時,在深層觀察到激活值顯著增加(殘差分支在合并前沒有标準化處理,殘差會逐層累積到主分支上)。事實上,在預标準化配置中,每個剩餘塊的輸出激活值直接合并回主分支,導緻主分支的振幅在更深的層越來越大。不同層次的振幅差異較大,導緻訓練不穩定。
後置标準化
為了緩解這個問題,我們建議使用殘差後标準化方法,如圖1所示。在這種方法中,每個剩餘塊的輸出在合并回主分支之前被标準化,并且當層變深時,主分支的振幅不會累積。如圖2所示,這種方法的激活幅度比原始預規範化配置中的激活幅度小得多。
在我們最大的模型訓練中,我們在主分支上每隔6個transformer塊引入一個額外的LayerNorm層,以進一步穩定訓練。
縮放餘弦注意力
在原始的self-attention計算中,像素對的注意力attenion被計算為查詢和關鍵向量的點積。我們發現,當這種方法用于大型視覺模型時,一些塊和頭的學習注意圖通常由幾個像素對控制,尤其是在res-post-norm配置中。為了緩解這個問題,我們提出了一種縮放餘弦注意方法,該方法通過縮放餘弦函數計算像素i和j的注意力:
\[Sim\left ( \mathbf{q}_{i}, \mathbf{k}_{j} \right ) = cos\left ( \mathbf{q}_{i}, \mathbf{k}_{j} \right ) / \tau + B_{ij}
\]
其中\(B_{ij}\)是像素\(i\)與像素\(j\)之間的相對位置偏置;\(\tau\)是一個可學習的縮放參數,不在層間、多頭間共享,一般設定其大于0.01. 餘弦函數是自然歸一化的,是以可以具有較低的注意力值。
Top
---
Bottom
3.3 擴充視窗分辨率
本節我們介紹對數空間連續位置偏置方法,是以,相對位置偏差可以在視窗分辨率之間平滑傳遞。
連續相對位置偏置
連續相對位置偏差法不是直接優化偏差參數,而是在相對坐标上采用一個小型元網絡
\[B(\Delta x, \Delta y) = \mathcal{g}(\Delta x, \Delta y)
\]
這裡的小型元網絡\(\mathcal{g}\)一般采用2層MLP和一個ReLU激活。也即新的偏置是由原偏置學習得到,那為什麼不直接學習,還要參考尺度不一樣的預訓練模型呢?(參考表1我們就知道,如果直接參數化訓練,不使用預訓練模型的偏置參數,那麼視窗在往高分辨率上推廣時,性能會下降)
元網絡\(\mathcal{g}\)生成任意相對坐标的偏內插補點,是以可以自然地轉移到具有任意變化視窗大小的微調任務。在推理過程中,可以預先計算每個相對位置的偏內插補點,并将其存儲為模型參數,以便推理與原始參數化偏差方法相同。
對數坐标
在很大程度上改變視窗大小時,需要外推大部分相對坐标範圍。為了解決這個問題,我們使用對數空間代替線性空間:
\[\begin{aligned}
\hat{\Delta x} &= sign(x) \cdot log (1+\left| \Delta x \right|)\\
\hat{\Delta y} &= sign(y) \cdot log (1+\left| \Delta y \right|)
\end{aligned}
\]
其中,\(\Delta x, \Delta y\)是線性空間縮放後的坐标,\(\hat{\Delta x}, \hat{\Delta y}\)是對數空間的坐标!
通過使用對數間隔坐标,當我們跨視窗分辨率傳遞相對位置偏差時,所需的外推比将遠小于使用原始線性間隔坐标的外推比。例如,使用原始坐标将預先訓練的8×8視窗大小轉換為微調的16×16視窗大小,輸入坐标範圍将為[−7, 7]×[−7,7]推廣至[−15, 15]×[−15, 15]. 外推比為原始範圍的\(\frac{8}{7} \simeq 1.14\)倍(增加了1.14倍)。使用對數間隔坐标,輸入範圍為[−2.079, 2.079] × [−2.079,2.079]推廣至[−2.773, 2.773] × [−2.773, 2.773]. 外推比為原始範圍的0.33倍,比使用原始線性間隔坐标的外推比小約4倍。
表1比較了不同位置偏差計算方法的推廣性能。可以看出,對數間隔CPB(連續位置偏差)方法表現最好,尤其是當轉移到較大的視窗大小時。
注意,這裡模型的參數是偏置,索引是超參數,使用對數空間連續位置偏置方法可以外推不同大小的偏置矩陣,而索引這種超參數完全可以使用代碼生成而不受影響,生成方式和前面詳細講解的相對位置編碼的索引一模一樣!
Top
---
Bottom
3.4 自監督預訓練
更大的模型更需要資料。為了解決資料匮乏的問題,以前的大型視覺模型通常使用巨大的标記資料集,如JFT-3B[17、56、80] (B=10億)。在這項工作中,我們開發了一種自我監督的預訓練方法SimMIM[72] (SimMIM是他們團隊提出的一個模型),以緩解對标記資料的需求。通過這種方法,我們僅使用7000萬個标記圖像(JFT-3B中的1/40),就成功地訓練了一個30億參數的強大Swin-Transformer模型,該模型在4個具有代表性的視覺基準上達到了最先進水準(SOTA)。
SimMIM模型論文:https://arxiv.org/abs/2111.09886
SimMIM模型代碼:https://github.com/microsoft/simmim
論文解析:
- https://zhuanlan.zhihu.com/p/435389007
- 本人論文精讀:(todo)
3.5 節省GPU記憶體的實作
另一個問題在于,當容量和分辨率都很大時,正常實作的GPU記憶體消耗難以承受。為了解決記憶體問題,我們采用以下實作:
- 零備援優化器(ZeRO)[54]。在優化器的通用資料并行實作中,将模型參數和優化狀态廣播到每個GPU。這種實作對GPU記憶體消耗非常不友好,例如,當使用AdamW優化器和fp32權重/狀态時,30億個參數的模型将消耗48G GPU記憶體。使用零優化器,模型參數和相應的優化狀态将被拆分并分布到多個GPU,進而顯著減少記憶體消耗。我們采用DeepSpeed架構,并在實驗中使用ZeRO stage-1選項。這種優化對訓練速度幾乎沒有影響。(2018年在優化領域就提出的技術)
- 激活檢查點[12]。Transformer層中的特征圖也會消耗大量GPU記憶體,這會在圖像和視窗分辨率較高時造成瓶頸。激活檢查點技術(亞線性記憶體優化技術的一種)可以顯著減少記憶體消耗,同時訓練速度降低30%。(簡單了解就是忽略激活層,不儲存其中間狀态,反向傳播時再計算)
- 順序self-attention計算。要在非常大的分辨率上訓練大型模型,例如,視窗大小為32×32、分辨率為1536×1536的圖像,即使使用上述兩種優化技術,正常A100 GPU(40GB記憶體)仍然無法負擔。我們發現,在這種情況下,自我注意子產品構成了一個瓶頸。為了緩解這個問題,我們按順序實作了自我注意計算,而不是使用以前的批處理計算方法。該優化應用于前兩個stage的層,對整體訓練速度影響不大。
通過這些實作,我們成功地使用英偉達A100-40G GPU訓練了一個3B模型,用于COCO目标檢測,輸入圖像分辨率為1536×1536,Kinetics-400動作分類,輸入分辨率為320×320×8。
四、我誇我自己階段
圖像分類性能
如你所見,CoAtNet模型這個被譽為作弊的模型,性能那确實是強!谷歌的實力這是看的見的!這裡V2也還是可以!
目标檢測性能
這裡給了基于COCO目标檢測、執行個體分割的結果,一句話V2最牛皮!\(I(W)\)分别表示圖像、視窗的分辨率;\(ms\)辨別了多尺度的測試被應用!
語義分割性能
如圖所示,語義分割腦殼我們常用UperNet,好像不用它世界就不完美一樣!這裡\(mIoU\)幾乎達到60%,不得不說确實是牛皮!
動作分類性能
預訓練模型的強大我們可以感受到...
V2關鍵技術消融實驗
後置标準化、縮放餘弦注意力技術的消融實驗,明顯兩個都加效果更好,這些技術都是work的!
這個實驗說明後置處理是更好的,實際使用過程種,殘差分支後置Norm确實是效果更好,相信這個技術會有更廣的前景!
不同圖像分辨率下、不同視窗尺寸下的預訓練模型性能表現,和table1對比就知道了!
Top
---
Bottom
完!