如果你想學習分布式系統,Cassandra可以說是一個好的開始。 Cassandra借鑒了兩篇重要的論文中的思想:Google的BigTable和Amazon的Dynamo。它的存儲基于BigTable,分布式基于Dynamo。這篇文章将嘗試解釋整體架構中的一些細節。
資料模型(Data Model)
在關系型資料庫中的一些常見術語在Cassandra中則有不同的定義。如果你能暫時忘記正常的定義,則閱讀本文可能會更加順利。
列(Colunmn)
“列”由一個name,一個相關的value和一個時間戳組成。name和value可以是任何類型,name不需要是字元串。一個列就是一個Name-Value-Timestamp集合。
列族(Column Family)
可以想象成在關系資料庫中一行所包含的一個key和一些列。
超列族(Super Column Family)
就是一個列族,這個列族中每個列的值就是一個列的集合。
大家可能會有些疑惑,可以看看下面的圖檔:
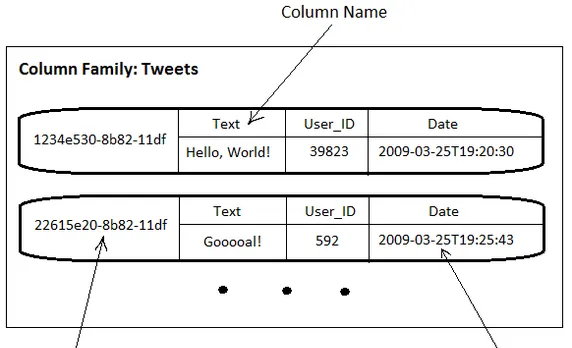

對Column Family再多說兩句。一個column family 可以被定義為一個有序rows的集合,每個row都包含了一個有序的columns的集合。Cassandra是一個自由的模式,之後你可以在任意時刻添加任意column到任意column family中。Columns不需要相同,并且每行都不需要有相同數量的columns。盡管這樣,在相同的column family有相同的columns還是比較好的,因為每個column family都存儲在一個單獨的檔案中。
一個column family 有一個name和一個比較器,比較器的的值決定了columns的排序。每行中的key被用來決定該行存儲在叢集中哪個節點中。
KeySpaces
是資料最外層的容器。可以把它想象成RDBMS中的一個資料庫。盡管不是必須的,但是為每個應用建立一個單獨的keyspace比較好。一個keyspace有一個name和一些别的屬性(比如說複制因子,複制政策等)。
Clusters
Cassandra運作在多個節點(一個叢集)之上,它在叢集間複制資料,是以當有一個節點當機,另外的節點能接管工作。這讓Cassandra是高可用的。
簡而言之,Cassandra的資料模型像下面這樣:
Cluster => Keyspace => Column Families (Standard or Super) => Column => (Name, Value, Timestamp)
一緻性哈希
Cassandra是一個分布式資料庫,一般會運作在多個機器上。在這些節點中,我們該怎麼劃分資料呢?可以使用一個簡單的政策,比如在N個節點的叢集中,把資料存放在(hash(key)%N)個機器上,但是當一個節點增加或者删除的時候會引起一些問題,因為每個節點上的資料都會變化。為了避免這種情況,我們使用一緻性哈希。
在一緻性哈希中,機器被放在一個邏輯上的圓環上,如下圖所示,key同樣也在這個圓環上,并被配置設定到順時針的最近一個機器上,并複制N份到順時針前的節點上(N被稱為複制因子)。Cassandra是一個最終一緻性的存儲系統, 會在背景進行複制操作。用戶端沒必要等待所有的副本寫入完成,可以設定要等待完成寫入的節點數。
現在,如果我們從圓環上增加或删除一個機器,key隻會在移動到和它相鄰的節點上去。
反熵(Anti-Entropy) 和 讀修複
Anti-Entropy是Cassandra的一個副本同步機制,來保證在不同節點上的資料都被更新到最新的版本。Anti-Entropy使用Merkle Trees,對于每個column family,都會構造這個tree。為什麼叫Anti-Entropy呢?在一個最終一緻性性的資料庫中,随着時間流逝,應該被精确複制的節點都會慢慢互相偏差。這個偏差可以被認為是系統的“entropy”。反熵 就是讓節點之間互相同步的過程。
Hash Tree被交換用來找出陳舊的資料。他們被用來減少節點之間的資料交換。Hashes trees看起來像下面這樣:
當反熵 開始的時候,hash trees被建構,并在節點之間互相交換。而不是交換真實的資料。然後從root開始比較。如果某些節點的hash不一樣,我們可以準确的判斷出哪些資料是陳舊的。
Memtables,SSTable and Commit Logs
一個寫操作會立即寫到節點的commit log中。隻有當這個請求被寫入到commit log中的時候,它才被認為是成功的。在被寫入commit log之後,這個value被寫入到一個被稱為memtable的記憶體結構中。當memtable的大小到達一個門檻值的時候,它就被刷到磁盤中的SSTable中。Memtables根據key進行排序,然後被順序的寫到磁盤中。是以,寫入是非常快的。
在磁盤中的一個SSTable是不可變的。若幹個SSTable被一個compaction程式合并到一起。每個SSTable都有一個相關的布隆過濾器和一個索引。布隆過濾器可以快速的檢查一個元素是否在這個集合中。
讀的時候,Cassandra首先會檢查memtable。然後會嘗試查找所有的SSTable。
Compaction
在壓縮期間,SSTable會被合并:key會被合并,标記為tombstones 的資料會被丢棄,會建立新的索引。
什麼是tombstones?
當一個值被 删除的時候,他不會真正的被删除,但是會給他一個tombstone标記。為什麼要這麼做呢?因為如果一個值在一個副本中被删除,而在另外的副本中沒被删除,當重新調節的時候,系統會認為被删除值的副本是沒有被更新的,然後又重新寫入這個值。Tombstones顯然會浪費空間,并且需要被清除。一個anti-entropy 開始的時候,在壓縮的時候是最好擺脫他們的時機。在每次GCGraceSeconds之後,Tombstones被會垃圾收集。
在壓縮的時候,合并的資料會被排序,一個新的索引也會被建立,然後新的合并後的資料、索引資料都會被寫到一個單獨的新的SSTable中。
Gossip 和失敗檢測
暗示送出(Hinted Handoff)
- 當一緻性不是必須的時候保證高可用
- 減少死亡節點上線所需要的時間