以前我們說到爬取網頁資料,你可能會第一時間想到scrapy,嗯,那個強大的python爬蟲庫,然而,有些時候,我們其實要爬取資料并非一定要使用這麼強大【笨重】的庫來實作,而且,某些時候,可能使用scrapy來爬取我們想到的資料,還比較困難。
舉個例子:假如,我們想購買一台騰訊雲CVM伺服器,這時候你們團隊肯定會有一個預算,這時候,可能你們PM想對比一下各種配置的價格,他發現去雲官網上看會比較痛苦,需要點好多好多次,然後對比也沒有那麼直接,那麼這時候,他可能會給你提一個需求。
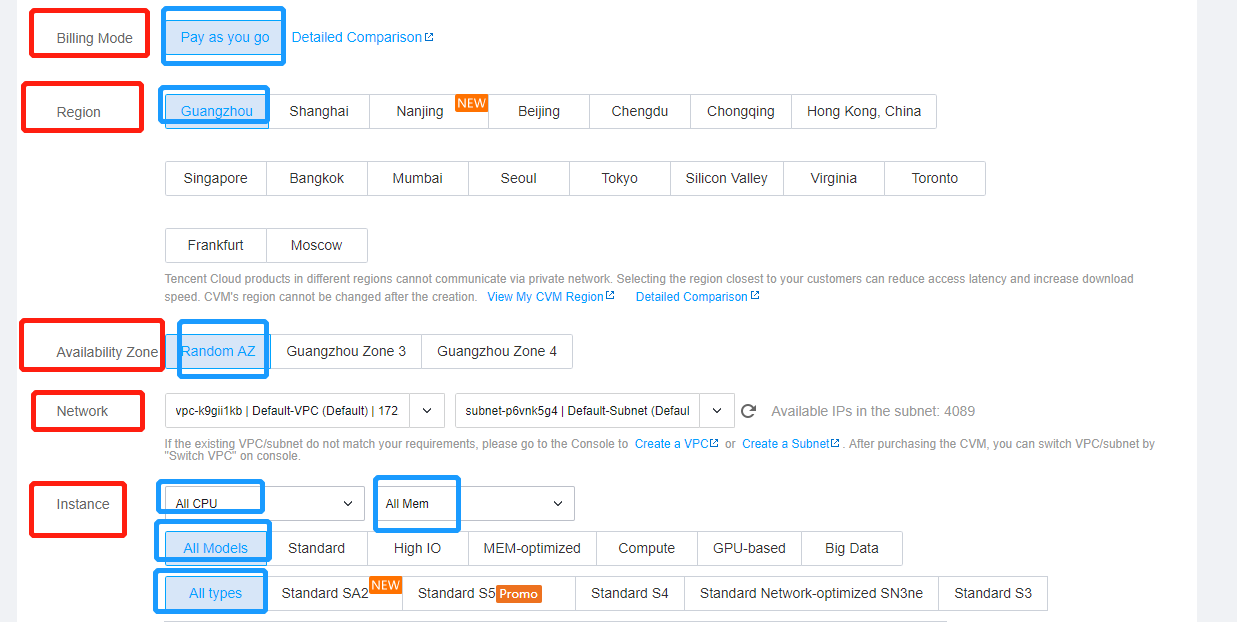
比如,把各個Region的都爬出來,然後CPU的類型選擇所有的類型,或者說還有一些雜七雜八的刷選條件,一言以蔽之,就是有些選項是預設,有些需要勾選指定項。

最終,需要将這麼多分頁資料都給爬出來。嗯,以上就是我們要做的事情。
那麼,分析一下,有幾個難點。
1、頁面中有一些選項,需要我們選擇,并非都是預設,是以,頁面加載出來之後,我們需要選擇。
2、其次,這個網頁中的資料是異步加載的,可以使用curl一下網頁,發現我們需要的資料并沒有,是一個空架子而已。
3、這裡面有分頁資料,都爬取下來,舉個例子,對于該頁,我們需要從第1頁點選到第
20頁,然後把這些表格中的資料都撈下來。
是以,可以看下我們的任務,這對于選擇scrapy來做的化,可能不是特别好實作,就拿頁面中的一些form項中的勾選,選擇,這點scrapy就并不是特别擅長。
是以,想一想,我們熟悉的什麼庫比較适合操作dom,然後拿dom中的内容呢?jQuery,很明顯,jQuery就非常适合做這樣的操作。
使用jQuery擷取資料
使用jQuery爬取頁面資料,主要要掌握以下幾個基本的技能:
1、如何找到需要操作的form元素,然後利用click()方法,選中需要選擇的項。
2、如何找到我們需要導出的資料。
3、如何在網頁中導出json資料,(注意也可以是其他格式)。
然後我們分析一下,比如這個頁面有10頁,那其實就是寫一個for循環。
for (var i = 0; i < pageCount;i++){
nextPage.click()
collectData()
} 複制
注意,這裡的難點是,click選項之後,頁面是需要一定的時間才能加載出資料的,是以,點選之後,我們并不能馬上去拿資料,需要等頁面加載資料成功,是以上面click之後,馬上去搜尋資料,很明顯不對。
那麼,該如何辦呢?我們寫一個等待函數?
for (var i = 0; i < pageCount;i++){
nextPage.click()
wait(3000)
collectData()
}
function wait(ms){
var start = new Date().getTime();
var end = start;
while(end < start + ms) {
end = new Date().getTime();
}
} 複制
請注意,我一開始也是這麼想的,但是,click()之後,頁面卡死了,更本不是我們想象的效果,點選之後,重新整理到下一頁,讓後,我們在這裡等待個3s左右,讓網絡把資料加載好,但實際上這個點選之後的過程背後是需要執行js代碼的,然而我們的wait函數沒有給他那個機會,是以,你看到頁面不會有任何變化。
是以,我們不能同步等待,需要異步等待。那麼,如何異步等待呢?我想到了
setTimeout
,
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
setInterval(travelPages,500)
function travelPages(){
if(!dataCollecteFinished) return
nextPage.click()
sleep(3000).then(collectData)
} 複制
是以,這裡for循環似乎并不好用了,為了異步,我使用了setInterval來代替循環,能執行循環中的條件是,我已經将上頁加載的資料抓取完畢。
嗯,這個思路下來,我成功的完成了這個任務。
一些疑問
1、假如入目标頁面沒有jQuery怎麼辦,很簡單,沒有我們就給他注入jQuery,
(function() {
var hm = document.createElement("script");
hm.src = "http://libs.baidu.com/jquery/2.0.0/jquery.min.js";
var s = document.getElementsByTagName("title")[0];
s.parentNode.insertBefore(hm, s);
})() 複制
2、同樣的道理,加入頁面沒有Promise啥的,都可以使用這種方式注入,但其實那裡并沒有必要使用Promise,直接寫一個setTimeout也是可以的,但是注意全局污染(很可能同時多個搜集器在搜集資料,造成資料混亂,用Promise封裝不僅僅是為了優雅,更多的是為了讓垃圾回收器一起自動回收掉setTimeout)
3、如何在使用js導出json
(function (console) {
console.save = function (data, filename) {
if (!data) {
console.error('Console.save: No data')
return;
}
if (!filename) filename = 'console.json'
if (typeof data === "object") {
data = JSON.stringify(data, undefined, 4)
}
var blob = new Blob([data], {
type: 'text/json'
}),
e = document.createEvent('MouseEvents'),
a = document.createElement('a')
a.download = filename
a.href = window.URL.createObjectURL(blob)
a.dataset.downloadurl = ['text/json', a.download, a.href].join(':')
e.initMouseEvent('click', true, false, window, 0, 0, 0, 0, 0, false, false, false, false, 0, null)
a.dispatchEvent(e)
}
})(console) 複制
4、如何把json檔案轉換為xsl,因為産品汪可能更喜歡看xsl
送你一個線上轉的網址,https://json-csv.com/
總結
有時候,使用jQuery來爬取網頁資料,也是很友善的,利用jQuery強大的查找dom元素,及操作dom元素的特性,實作起來可能要比scrapy簡單的多。