這篇文章主要是說明一下群組推薦系統,衆所周知,推薦系統已經應用十分廣泛,群組推薦的應用不僅老使用者上發揮了極大的作用,在新使用者的冷啟動上也發揮了很大的作用。
由于後續會有一篇文章介紹結合深度學習的群組推薦,是以這裡先借用該篇論文,借花獻佛,介紹一下群組推薦系統和其應用。
本文中所涉及的内容算是比較老了,但在不同公司或者推薦系統的不同階段仍然有應用,其中群組推薦的思想更是經久不衰,是以本文比較适合以“溫習知識”或“了解群組推薦”,至于群組推薦的更加先進和業界比較常用的做法可以持續關注公衆号,後續會進行介紹。
傳統推薦系統
推薦問題通常被形式化描述為一個定義在使用者空間和項目空間上的效用函數,推薦系統的目的是把特定的項目推薦給使用者,使效用函數最大化。
目前推薦系統的分類沒有統一的标準,從不同的角度可以進行不同的劃分。
- 從推薦模型的角度:
- 協同過濾推薦
- 基于内容的推薦
- 基于知識的推薦
- 組合推薦
- 基于人口統計學的土建
- 基于效用的推薦
- 基于關聯規則的推薦
- 基于網絡結構的推薦
- 從推薦系統的資料源和應用環境的角度:
- 上下文感覺推薦
- 社會化推薦
- 移動推薦
- 從推薦系統技術的角度:
- 基于規則的推薦
- 基于機器學習的推薦
- 基于深度學習的推薦
- 基于強化學習的推薦
- 基于知識圖譜的推薦
群組推薦系統的形式化定義
許多日常活動中是由多個使用者以群組的形式參與的,是以推薦系統需要考慮群組中每個使用者的偏好來進行推薦,這種推薦系統稱為群組推薦系統(Group Recommend System),它将推薦對象由單個使用者擴充為一個群組,這為推薦系統帶來了一些挑戰。
群組成員的興趣偏好可能很相似,也可能存在較大差異,如何擷取群組成員的共同偏好,來緩解群組成員之間的偏好沖突,使推薦的結果盡可能滿足所有群組成員的需求,則是群組推薦研究需要解決的關鍵問題。
群組推薦目前還沒有統一的形式化定義,有文獻基于共識分數的概念給出形式化定義:
1、群組預測評分
群組對項目的預測評分由群組中每個使用者預測評分融合得到,使用的偏好融合政策不同,群組計算的預測方法也不同,其中最常用的則是均值政策。
2、群組分歧度
群組對項目度分歧度表示群組中的使用者對項目預測評分的差異程度。群組分歧度也有多種計算方法,這裡給出一種最常用的方法:利用分歧方差(disagreeement variabce) 計算群組分歧度。
其中 是群組中的使用者對項目預測評分的均值。
3、共識函數
共識函數利用群組預測評分群組分歧計算得出群組對項目的共識分數。
其中:
- 表示群組預測分在共識函數中的權重
- 表示群組分歧度在共識函數中的權重
組推薦的目标是對于給定的群組和項目集合,找到特定的項目使共識函數最大化。即群組預測評分最高,群組分歧度越低,就越能滿足所有群組成員的偏好。
4、Top-k 組推薦
群組推薦将前 個共識分數最高的項目推薦給群組,即Top-k推薦,推薦清單中的項目按照共識分數降序排序。
從上述的形式化定義看出,群組推薦系統首先通過傳統的推薦算法為每個使用者生成預測評分,然後根據使用者預測評分得到群組預測評分。然而這并不是所有群組推薦系統通用的方法。此外,該形式化定義與傳統推薦系統的形式化定義并不統一不利于組推薦問題的描述與求解。是以,群組推薦系統的形式化定義仍是一個開放問題。
雖然上述的群組推薦的形式化定義不通用,但是在具體的應用場景可以結合自己的群組預測評分和群組分歧度進行使用。
群組推薦與傳統推薦的異同
下表展示了群組推薦系統與傳統推薦系統的比較
| - | 傳統推薦系統 | 群組推薦系統 |
|---|---|---|
| 推薦目标 | 單個使用者 | 群組 |
| 使用者偏好擷取 | 不需要偏好共享 | 需要偏好共享 |
| 偏好融合 | 不需要 | 需要 |
| 推薦結果展示 | 獨立方式 | 共享方式 |
| 支援使用者互動 | 不需要 | 需要 |
當然群組推薦也和傳統的推薦系統存在一些相同之處,比如:
- 常見的協同、基于内容、組合推薦等也會用在群組推薦中
- 群組推薦也可以作為一路召回為單個使用者推薦
- 群組推薦可以幫助解決“使用者冷啟動”問題
群組推薦系統研究架構
群組推薦的生命周期分為4個階段:
- 收叢集組成員資料
- 擷取群組成員偏好資訊
- 生成群組推薦
- 推薦結果的評價和回報
下面展示的是從面向過程角度提出的4層群組推薦系統研究架構:
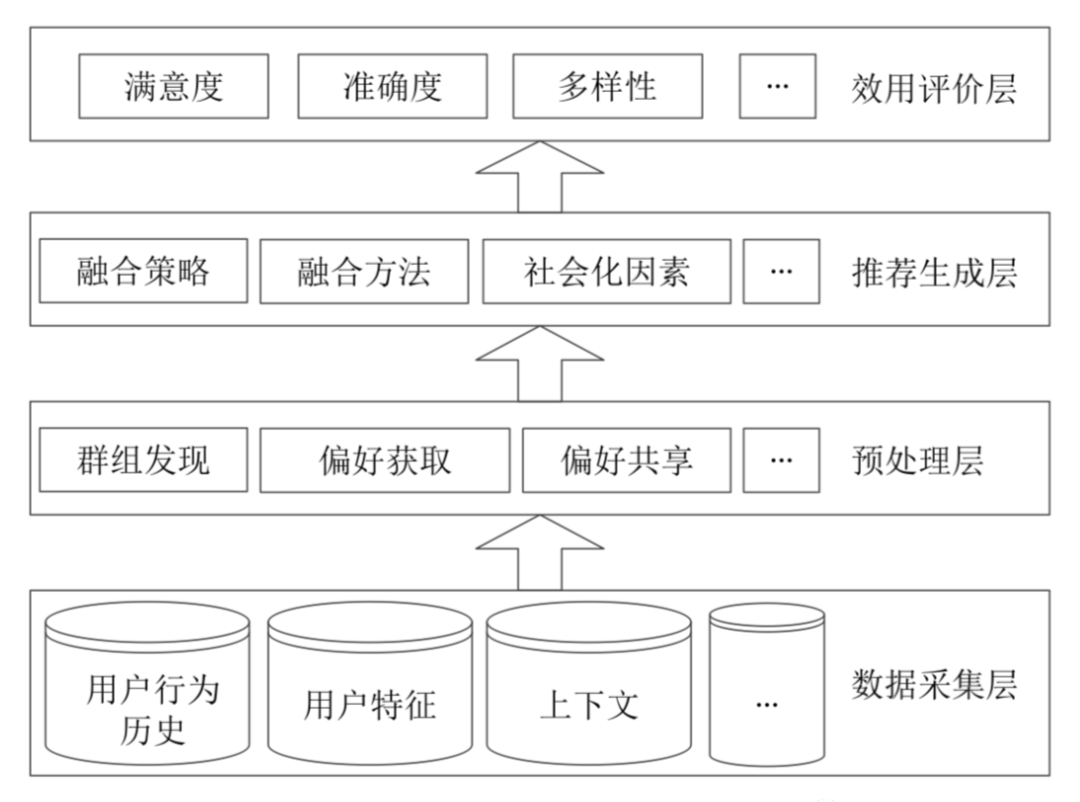
4層群組推薦系統研究架構
底層的資料源包括:
- 群組成員行為曆史
- 群組成員浏覽記錄
- 群組使用者-項目評分
- 群組成員人口統計學特征
- 項目特征
- 上下文資訊
- ...
資料預處理層則是通過分析使用者和項目的源資料資訊建構使用者偏好模型。與傳統推薦系統相比,群組推薦系統的使用者偏好過程更加關注使用者的負向偏好(因為,負向偏好資料更加容易擷取,且在建構群組推薦候選池的時候可以過濾掉負向物品)和群組成員偏好的共享。
推薦生成層則是将群組成員偏好映射到群組偏好,通過一定的融合政策和推薦融合方法生成群組推薦過程。
群組推薦效果評價層則是采用一些評價方法對群組推薦進行評價,常見的:
- 使用者滿意度
- 準确度
- 覆寫率
- 多樣性
- 精細度
- ...
群組推薦的關鍵技術
使用者偏好擷取
使用者行為包括:
- 顯式回報:能明确表示使用者對内容喜好等級的資料,比如評分,打星等
- 隐式回報:使用者與物品之間産生的互動行為,沒有明确的表示喜好等級
群組推薦的群組發現
目前群組發現方法主要是根據使用者的偏好和人口統計學資訊等特征對使用者進行聚類(當然這已經不是目前的主流方法了,能對使用者聚類的方式有很多,比如使用者的偏好、人口統計學、使用裝置、各種Embedding向量等)。
進行聚類的算法主要有:
- 階層化聚類
- 劃分式聚類
- KMeans聚類
- 二分KMeans聚類
- 基于滑窗的聚類
- Mean-Shift 聚類
- 基于密度的聚類
- DBSCAN
- 基于網格的聚類
- 新發展的一些方法
- 基于限制(eg:EM聚類)
- 基于模糊
- 基于粒度
- 量子聚類
- 核聚類
- 譜聚類
群組推薦的偏好融合算法
偏好融合政策
基本融合政策
群組推薦中常用的融合政策如下:

群組推薦中常用的融合政策
權重模型在進行偏好融合時,應當考慮到不同的群組成員對群組偏好的不同影響。權重模型根據群組成員的特征、角色、影響力等因素,為每個群組成員配置設定不同的權重,這類權重模型可分為:
- 靜态模型:根據群組成員的年齡、性别等人口統計學資訊對使用者進行分類 然後對不同類别賦予不同的權重,比如:一個針對00後的社群對青年和老年人配置設定較小的權重
- 互動模型:根據使用者與内容之間的互動行為來配置設定權重。比如:使用者的行為越多,說明使用者越活躍,則權重越大
研究表明:互動模型的推薦效果通常比靜态模型要好。
一種常見的互動模型權重方法為:根據使用者的角色和活躍度來計算使用者在群組中所占的權重可以用以下兩種方式計算:
- The role-based model
表示和使用者角色相同的使用者
- The family-log model
上述公式來自論文:Group-Based Recipe Recommendations: Analysis of Data Aggregation Strategies(https://dl.acm.org/doi/10.1145/1864708.1864732)
多種政策融合
在傳統的推薦系統中,組合推薦方法通過組合多種推薦算法能夠提高推薦效果,同樣群組推薦系統也可以通過多種融合政策來應對單一融合政策的不足。同樣是上文中提到的一篇論文,介紹的一種組合政策,公式如下:
其中:
- 表示最小痛苦政策的最小門檻值
- 表示最開心政策的最大門檻值
- 表示 對的評分不在時權重為1,其他為
偏好融合方法
偏好融合的方法分為:
- 推薦結果融合
- 評分融合
- 群組偏好模組化
其中推薦結果融合和評分融合都是先為每個群組成員生成推薦結果,再彙聚到群組上,群組偏好模組化則是先把群組成員的偏好模型融合生成群組的偏好模型,再根據群組偏好模型生成群組推薦。
是以根據偏好融合的時機,可以将偏好融合方法分為:
- 模型融合
- 推薦融合
其差別如下:
模型融合
模型融合的形式化表示如下:
其中 :
- 表示群組對項目的評分
- 表示使用者對項目的評分
- 表示使用者在群組中的權重
- 表示群組對未評分項目的預測評分
- 表示群組和的偏好相似度
當然這裡隻是舉例說明模型融合的政策,也有很多其他方式的形式化表示。
推薦融合
推薦融合的形式化表示為:
模型融合和推薦融合的形式化表示公式來自論文:Group-Based Recipe Recommendations: Analysis of Data Aggregation Strategies(https://dl.acm.org/doi/10.1145/1864708.1864732)
偏好融合政策比較
下表給出了推薦準确率較高的幾種偏好融合政策、偏好融合方法、推薦算法組合
| 偏好融合政策 | 偏好融合方法 | 推薦算法 |
|---|---|---|
| 最開心政策 | 模型融合 | 基于内容的推薦 |
| 最小痛苦政策 | 推薦融合 | 基于内容的推薦 |
| 痛苦避免均值政策 | 模型融合 | 基于使用者的協同過濾 |
| 均值政策 | 推薦融合 | 組合推薦 |
群組推薦的評價
- 準确度:RMSE、MAP、F1、E(k)、Recall、Precision、AUC、NDCG
- 使用者滿意度
- 多樣性
- 覆寫率
- 驚喜度
群組推薦研究的難點和發展方向
群組推薦的偏好融合
包括偏好融合政策和偏好融合方法。目前的融合政策主要關注的是公平性,但是這些預定義的政策和資料本身無關。
基于模型的群組推薦方法
現有的群組推薦方法也可以分為:
- 基于記憶體
- 基于模型
基于偏好融合的群組推薦算法則屬于基于記憶體的方式,主要缺陷是使用啟發式的融合政策,忽略了群組成員之間的互相影響。
基于模型的方法通過建構一個生成模型,對群組選擇項目的生成過程進行模組化,進而能夠通過考慮群組成員之間的互動來進行更精準的推薦。
群組推薦中的不确定性
大部分推薦系統假設擷取的使用者偏好是準确的,但使用者偏好本身存在不确定性,特别是通過隐式回報擷取的資料本身就具有很大的不确定性。
群組推薦的解釋和可視化
對群組推薦的結果進行合理的解釋并以合适的方式呈現給群組能夠提高透明度,使使用者能夠更好的了解推薦機制的其他成員的偏好,進而更加容易接受推薦系統。
群組推薦的效用評價
由于群組類型、規模以及群組推薦生成方式的多樣性使得群組推薦的評價比傳統推薦系統的評價更加困難。
此外,目前推薦系統的評價集中在推薦準确度方面,而對推薦的覆寫率、多樣性、驚喜度等方面關注較少。
上下文感覺的群組推薦
除了使用者和内容之間的互動資訊,如何将使用者的地理位置、時間、環境、情緒等因素應用到群組推薦中也是一大難點。
移動群組推薦
移動群組推薦關注的是在移動裝置上,使用者的需求變得更加不可控,如何實時有效的捕獲使用者的興趣也是非常值得關注的地方。
群組推薦的使用者隐私和安全
偏好共享和提供使用者互動有利于群組推薦系統性能的提升,但同時也帶來了使用者隐私問題。
雖然在傳統的推薦系統中,使用者隐私和安全也是值得關注的,但是和群組推薦相比,群組推薦則更加複雜。
群組推薦中存在傳統推薦問題
比如冷啟動等。