Hi,我是王知無,一個大資料領域的原創作者。
放心關注我,擷取更多行業的一手消息。
一、各種整合
hive內建hudi方法:将hudi jar複制到hive lib下
cp ./packaging/hudi-hadoop-mr-bundle/target/hudi-hadoop-mr-bundle-0.5.2-SNAPSHOT.jar $HIVE_HOME/lib hive
hive 查詢hudi 資料主要是在hive中建立外部表資料路徑指向hdfs 路徑,同時hudi 重寫了inputformat 和outpurtformat。因為hudi 在讀的資料的時候會讀中繼資料來決定我要加載那些parquet檔案,而在寫的時候會寫入新的中繼資料資訊到hdfs路徑下。是以hive 要內建hudi 查詢要把編譯的jar 包放到HIVE-HOME/lib 下面。否則查詢時找不到inputformat和outputformat的類。
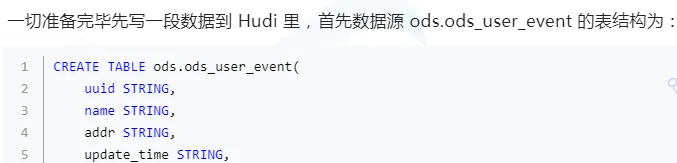
hive 外表資料結構如下:
CREATE EXTERNAL TABLE `test_partition`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_file_name` string,
`id` string,
`oid` string,
`name` string,
`dt` string,
`isdeleted` string,
`lastupdatedttm` string,
`rowkey` string)
PARTITIONED BY (
`_hoodie_partition_path` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://hj:9000/tmp/hudi'
TBLPROPERTIES (
'transient_lastDdlTime'='1582111004') presto 內建 hudi
presto 內建hudi 是基于hive catalog 同樣是通路hive 外表進行查詢,如果要內建需要把hudi 包copy 到presto hive-hadoop2插件下面。
presto內建hudi方法: 将hudi jar複制到 presto hive-hadoop2下
cp ./packaging/hudi-hadoop-mr-bundle/target/hudi-hadoop-mr-bundle-0.5.2-SNAPSHOT.jar $PRESTO_HOME/plugin/hive-hadoop2/
Hudi代碼實戰

Copy_on_Write 模式操作(預設模式)
- insert操作(初始化插入資料)
// 不帶分區寫入
@Test
def insert(): Unit = {
val spark = SparkSession.builder.appName("hudi insert").config("spark.serializer", "org.apache.spark.serializer.KryoSerializer").master("local[3]").getOrCreate()
val insertData = spark.read.parquet("/tmp/1563959377698.parquet")
insertData.write.format("org.apache.hudi")
// 設定主鍵列名
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "rowkey")
// 設定資料更新時間的列名
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "lastupdatedttm")
// 并行度參數設定
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// table name 設定
.option(HoodieWriteConfig.TABLE_NAME, "test")
.mode(SaveMode.Overwrite)
// 寫入路徑設定
.save("/tmp/hudi")
}
// 帶分區寫入
@Test
def insertPartition(): Unit = {
val spark = SparkSession.builder.appName("hudi insert").config("spark.serializer", "org.apache.spark.serializer.KryoSerializer").master("local[3]").getOrCreate()
// 讀取文本檔案轉換為df
val insertData = Util.readFromTxtByLineToDf(spark, "/home/huangjing/soft/git/experiment/hudi-test/src/main/resources/test_insert_data.txt")
insertData.write.format("org.apache.hudi")
// 設定主鍵列名
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "rowkey")
// 設定資料更新時間的列名
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "lastupdatedttm")
// 設定分區列
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "dt")
// 設定索引類型目前有HBASE,INMEMORY,BLOOM,GLOBAL_BLOOM 四種索引 為了保證分區變更後能找到必須設定全局GLOBAL_BLOOM
.option(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH, "true")
// 設定索引類型目前有HBASE,INMEMORY,BLOOM,GLOBAL_BLOOM 四種索引
.option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.GLOBAL_BLOOM.name())
// 并行度參數設定
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.option(HoodieWriteConfig.TABLE_NAME, "test_partition")
.mode(SaveMode.Overwrite)
.save("/tmp/hudi")
} - upsert操作(資料存在時修改,不存在時新增)
// 不帶分區upsert
@Test
def upsert(): Unit = {
val spark = SparkSession.builder.appName("hudi upsert").config("spark.serializer", "org.apache.spark.serializer.KryoSerializer").master("local[3]").getOrCreate()
val insertData = spark.read.parquet("/tmp/1563959377699.parquet")
insertData.write.format("org.apache.hudi")
// 設定主鍵列名
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "rowkey")
// 設定資料更新時間的列名
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "lastupdatedttm")
// 表名稱設定
.option(HoodieWriteConfig.TABLE_NAME, "test")
// 并行度參數設定
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.mode(SaveMode.Append)
// 寫入路徑設定
.save("/tmp/hudi");
}
// 帶分區upsert
@Test
def upsertPartition(): Unit = {
val spark = SparkSession.builder.appName("upsert partition").config("spark.serializer", "org.apache.spark.serializer.KryoSerializer").master("local[3]").getOrCreate()
val upsertData = Util.readFromTxtByLineToDf(spark, "/home/huangjing/soft/git/experiment/hudi-test/src/main/resources/test_update_data.txt")
upsertData.write.format("org.apache.hudi").option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "rowkey")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "lastupdatedttm")
// 分區列設定
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "dt")
.option(HoodieWriteConfig.TABLE_NAME, "test_partition")
.option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.GLOBAL_BLOOM.name())
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.mode(SaveMode.Append)
.save("/tmp/hudi");
} - delete操作(删除資料)
@Test
def delete(): Unit = {
val spark = SparkSession.builder.appName("delta insert").config("spark.serializer", "org.apache.spark.serializer.KryoSerializer").master("local[3]").getOrCreate()
val deleteData = spark.read.parquet("/tmp/1563959377698.parquet")
deleteData.write.format("com.uber.hoodie")
// 設定主鍵列名
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "rowkey")
// 設定資料更新時間的列名
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "lastupdatedttm")
// 表名稱設定
.option(HoodieWriteConfig.TABLE_NAME, "test")
// 硬删除配置
.option(DataSourceWriteOptions.PAYLOAD_CLASS_OPT_KEY, "org.apache.hudi.EmptyHoodieRecordPayload")
} 删除操作分為軟删除和硬删除配置在這裡檢視:http://hudi.apache.org/cn/docs/0.5.0-writing_data.html#%E5%88%A0%E9%99%A4%E6%95%B0%E6%8D%AE
- query操作(查詢資料)
@Test
def query(): Unit = {
val basePath = "/tmp/hudi"
val spark = SparkSession.builder.appName("query insert").config("spark.serializer", "org.apache.spark.serializer.KryoSerializer").master("local[3]").getOrCreate()
val tripsSnapshotDF = spark.
read.
format("org.apache.hudi").
load(basePath + "/*/*")
tripsSnapshotDF.show()
} - 同步至Hive
@Test
def hiveSync(): Unit = {
val spark = SparkSession.builder.appName("delta hiveSync").config("spark.serializer", "org.apache.spark.serializer.KryoSerializer").master("local[3]").getOrCreate()
val upsertData = Util.readFromTxtByLineToDf(spark, "/home/huangjing/soft/git/experiment/hudi-test/src/main/resources/hive_sync.txt")
upsertData.write.format("org.apache.hudi")
// 設定主鍵列名
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "rowkey")
// 設定資料更新時間的列名
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "lastupdatedttm")
// 分區列設定
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "dt")
// 設定要同步的hive庫名
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "hj_repl")
// 設定要同步的hive表名
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, "test_partition")
// 設定資料集注冊并同步到hive
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true")
// 設定當分區變更時,目前資料的分區目錄是否變更
.option(HoodieIndexConfig.BLOOM_INDEX_UPDATE_PARTITION_PATH, "true")
// 設定要同步的分區列名
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY, "dt")
// 設定jdbc 連接配接同步
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY, "jdbc:hive2://localhost:10000")
// hudi表名稱設定
.option(HoodieWriteConfig.TABLE_NAME, "test_partition")
// 用于将分區字段值提取到Hive分區列中的類,這裡我選擇使用目前分區的值同步
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY, "org.apache.hudi.hive.MultiPartKeysValueExtractor")
// 設定索引類型目前有HBASE,INMEMORY,BLOOM,GLOBAL_BLOOM 四種索引 為了保證分區變更後能找到必須設定全局GLOBAL_BLOOM
.option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.GLOBAL_BLOOM.name())
// 并行度參數設定
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.mode(SaveMode.Append)
.save("/tmp/hudi");
}
@Test
def hiveSyncMergeOnReadByUtil(): Unit = {
val args: Array[String] = Array("--jdbc-url",
"jdbc:hive2://hj:10000",
"--partition-value-extractor",
"org.apache.hudi.hive.MultiPartKeysValueExtractor",
"--user", "hive", "--pass", "hive",
"--partitioned-by", "dt", "--base-path",
"/tmp/hudi_merge_on_read", "--database", "hj_repl",
"--table", "test_partition_merge_on_read")
HiveSyncTool.main(args)
} 這裡可以選擇使用spark 或者hudi-hive包中的hiveSynTool進行同步,hiveSynTool類其實就是run_sync_tool.sh運作時調用的。hudi 和hive同步時保證hive目标表不存在,同步其實就是建立外表的過程。
- Hive查詢讀優化視圖和增量視圖
@Test
def hiveViewRead(): Unit = {
// 目标表
val sourceTable = "test_partition"
// 增量視圖開始時間點
val fromCommitTime = "20200220094506"
// 擷取目前增量視圖後幾個送出批次
val maxCommits = "2"
Class.forName("org.apache.hive.jdbc.HiveDriver")
val prop = new Properties()
prop.put("user", "hive")
prop.put("password", "hive")
val conn = DriverManager.getConnection("jdbc:hive2://localhost:10000/hj_repl", prop)
val stmt = conn.createStatement
// 這裡設定增量視圖參數
stmt.execute("set hive.input.format=org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat")
// Allow queries without partition predicate
stmt.execute("set hive.strict.checks.large.query=false")
// Dont gather stats for the table created
stmt.execute("set hive.stats.autogather=false")
// Set the hoodie modie
stmt.execute("set hoodie." + sourceTable + ".consume.mode=INCREMENTAL")
// Set the from commit time
stmt.execute("set hoodie." + sourceTable + ".consume.start.timestamp=" + fromCommitTime)
// Set number of commits to pull
stmt.execute("set hoodie." + sourceTable + ".consume.max.commits=" + maxCommits)
val rs = stmt.executeQuery("select * from " + sourceTable)
val metaData = rs.getMetaData
val count = metaData.getColumnCount
while (rs.next()) {
for (i <- 1 to count) {
println(metaData.getColumnName(i) + ":" + rs.getObject(i).toString)
}
println("-----------------------------------------------------------")
}
rs.close()
stmt.close()
conn.close()
} - Presto查詢讀優化視圖(暫不支援增量視圖)
@Test
def prestoViewRead(): Unit = {
// 目标表
val sourceTable = "test_partition"
Class.forName("com.facebook.presto.jdbc.PrestoDriver")
val conn = DriverManager.getConnection("jdbc:presto://hj:7670/hive/hj_repl", "hive", null)
val stmt = conn.createStatement
val rs = stmt.executeQuery("select * from " + sourceTable)
val metaData = rs.getMetaData
val count = metaData.getColumnCount
while (rs.next()) {
for (i <- 1 to count) {
println(metaData.getColumnName(i) + ":" + rs.getObject(i).toString)
}
println("-----------------------------------------------------------")
}
rs.close()
stmt.close()
conn.close()
} 問題整理
- merg on read 問題
merge on read 要配置option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)才會生效
配置為option(HoodieTableConfig.HOODIE_TABLE_TYPE_PROP_NAME, HoodieTableType.MERGE_ON_READ.name())将不會生效。
- spark pom 依賴問題
不要引入spark-hive 的依賴裡面包含了hive 1.2.1的相關jar包,而hudi 要求的版本是2.x版本。如果一定要使用請排除相關依賴。
- hive視圖同步問題
代碼與hive視圖同步時resources要加入hive-site.xml 配置檔案,不然同步hive metastore 會報錯。
二、內建Spark SQL
1. 摘要
內建Spark SQL後,會極大友善使用者對Hudi表的DDL/DML操作,下面就來看看如何使用Spark SQL操作Hudi表。
2. 環境準備
首先需要将PR拉取到本地打包,生成SPARK_BUNDLE_JAR(hudi-spark-bundle_2.11-0.9.0-SNAPSHOT.jar)包
2.1 啟動spark-sql
在配置完spark環境後可通過如下指令啟動spark-sql
spark-sql --jars $PATH_TO_SPARK_BUNDLE_JAR
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' 2.2 設定并發度
由于Hudi預設upsert/insert/delete的并發度是1500,對于示範的小規模資料集可設定更小的并發度。
set hoodie.upsert.shuffle.parallelism = 1;
set hoodie.insert.shuffle.parallelism = 1;
set hoodie.delete.shuffle.parallelism = 1; 同時設定不同步Hudi表中繼資料
set hoodie.datasource.meta.sync.enable=false; 3. Create Table
使用如下SQL建立表
create table test_hudi_table (
id int,
name string,
price double,
ts long,
dt string
) using hudi
partitioned by (dt)
options (
primaryKey = 'id',
type = 'mor'
)
location 'file:///tmp/test_hudi_table' 說明:表類型為MOR,主鍵為id,分區字段為dt,合并字段預設為ts。
建立Hudi表後檢視建立的Hudi表
show create table test_hudi_table 4. Insert Into
4.1 Insert
使用如下SQL插入一條記錄
INSERT INTO test_hudi_table
SELECT 1 AS id, 'hudi' AS name, 10 AS price, 1000 AS ts, '2021-05-05' AS dt insert完成後檢視Hudi表本地目錄結構,生成的中繼資料、分區和資料與Spark Datasource寫入均相同。
4.2 Select
使用如下SQL查詢Hudi表資料
select * from test_hudi_table 查詢結果如下
5. Update
5.1 Update
使用如下SQL将id為1的price字段值變更為20
update test_hudi_table set price = 20.0 where id = 1 5.2 Select
再次查詢Hudi表資料
select * from test_hudi_table 查詢結果如下,可以看到price已經變成了20.0
檢視Hudi表的本地目錄結構如下,可以看到在update之後又生成了一個deltacommit,同時生成了一個增量log檔案。
6. Delete
6.1 Delete
使用如下SQL将id=1的記錄删除
delete from test_hudi_table where id = 1 檢視Hudi表的本地目錄結構如下,可以看到delete之後又生成了一個deltacommit,同時生成了一個增量log檔案。
6.2 Select
再次查詢Hudi表
select * from test_hudi_table; 查詢結果如下,可以看到已經查詢不到任何資料了,表明Hudi表中已經不存在任何記錄了。
7. Merge Into
7.1 Merge Into Insert
使用如下SQL向test_hudi_table插入資料
merge into test_hudi_table as t0
using (
select 1 as id, 'a1' as name, 10 as price, 1000 as ts, '2021-03-21' as dt
) as s0
on t0.id = s0.id
when not matched and s0.id % 2 = 1 then insert * 7.2 Select
查詢Hudi表資料
select * from test_hudi_table 查詢結果如下,可以看到Hudi表中存在一條記錄
7.3 Merge Into Update
使用如下SQL更新資料
merge into test_hudi_table as t0
using (
select 1 as id, 'a1' as name, 12 as price, 1001 as ts, '2021-03-21' as dt
) as s0
on t0.id = s0.id
when matched and s0.id % 2 = 1 then update set * 7.4 Select
查詢Hudi表
select * from test_hudi_table 查詢結果如下,可以看到Hudi表中的分區已經更新了
7.5 Merge Into Delete
使用如下SQL删除資料
merge into test_hudi_table t0
using (
select 1 as s_id, 'a2' as s_name, 15 as s_price, 1001 as s_ts, '2021-03-21' as dt
) s0
on t0.id = s0.s_id
when matched and s_ts = 1001 then delete 查詢結果如下,可以看到Hudi表中已經沒有資料了
8. 删除表
使用如下指令删除Hudi表
drop table test_hudi_table; 使用show tables檢視表是否存在
show tables; 可以看到已經沒有表了
9. 總結
通過上面示例簡單展示了通過Spark SQL Insert/Update/Delete Hudi表資料,通過SQL方式可以非常友善地操作Hudi表,降低了使用Hudi的門檻。另外Hudi內建Spark SQL工作将繼續完善文法,盡量對标Snowflake和BigQuery的文法,如插入多張表(INSERT ALL WHEN condition1 INTO t1 WHEN condition2 into t2),變更Schema以及CALL Cleaner、CALL Clustering等Hudi表服務。
如果這個文章對你有幫助,不要忘記 「點贊」 「收藏」