論文題目:Fast-MVSNet: Sparse-to-Dense Multi-View Stereo with Learned Propagation and Gauss-Newton Refinement
代碼位址:在公衆号「3D視覺工坊」,背景回複「Fast-MVSNet」,即可直接下載下傳。
摘要:
以往基于深度學習的多視圖立體比對 (MVS) 方法幾乎都是為了提高重建品質。除了重建品質,效率也是現實場景中重建的一個重要特征。為此,本文提出Fast-MVSNet,一種新的由稀疏到稠密、由粗糙到精細的架構,用于快速和準确的多視圖深度估計。具體而言,在Fast-MVSNet中,我們首先構造一個稀疏的代價體來學習一個稀疏但高分辨率的深度圖。然後我們利用小型卷積神經網絡對局部區域内像素的深度依賴進行編碼,以稠密化稀疏但高分辨率的深度圖。最後提出簡單且有效的高斯-牛頓層來進一步優化深度圖。一方面,高分辨率的深度圖、資料驅動的自适應傳播方法和高斯-牛頓層保證了算法的有效性。另一方面,Fast-MVSNet中所有子產品都是輕量級的,是以保證了算法的高效性。此外由于稀疏深度圖的表示,我們方法也是memory-friendly的。實驗結果表明Fast-MVSNet比Point-MVSNet快5倍,比R-MVSNet快14倍,同時在Tanks and Temples的DTU上取得了可比較甚至更好的結果。
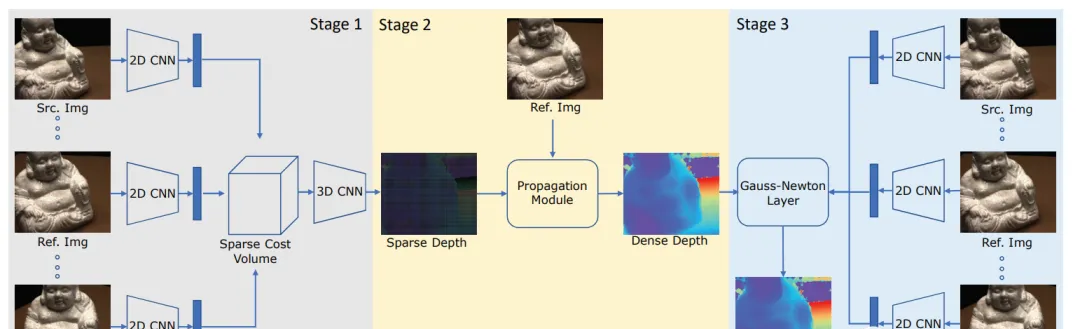
圖 1. Fast-MVSNet的網絡架構。第一階段,首先基于2D CNN提取的特征建構稀疏代價體,并使用3D CNN預測稀疏的低分辨率深度圖。第二階段:設計了一個簡單而有效的網絡将稀疏深度圖傳播為稠密深度圖。第三階段:使用可微分的高斯-牛頓層來進一步優化深度圖。
一、方法

為此,我們提出了Fast-MVSNet,一個高效的MVS架構,利用由稀疏到稠密、由粗糙到精細的政策來進行深度估計。具體地,首先估計一個稀疏的高分辨率深度圖,這樣現有的MVS方法可以以更低的成本應用;然後設計了一個簡單而有效的傳播子產品來稠密化稀疏深度圖;最後,提出一種可微的高斯-牛頓層來進一步優化深度圖,實作亞像素精度的深度估計。方法的整體流程如圖1所示。
圖 2. 深度圖的初始化。(a) MVSNet和R-MVSNet方法使用的高分辨率深度圖。(b) Point-MVSNet使用的低分辨率深度圖。(c) 和之前的方法不同,本方法使用的是稀疏的高分辨率深度圖。
1.1 稀疏的高分辨率深度圖預測
算法的第一步是為參考圖像I0估計稀疏的高分辨率深度圖。圖2展示了稀疏深度圖表示和其他類型深度圖之間的差異。本方法以較低的記憶體消耗和代價計算來預測稀疏的高分辨率深度圖,而其他方法要麼估計高分辨率的深度圖,但是記憶體成本高;要麼估計低分辨率的深度圖,細節處會丢失。我們認為,稀疏的高分辨率表示比低分辨率表示更加合适,原因有以下兩點:1)使用低分辨率深度圖進行訓練需要對ground-truth深度圖進行下采樣。如果使用最近鄰方式,那麼低分辨率的表示形式和我們稀疏的高分辨率表示是相同的。然而在這種情況下,得到的深度圖與提取的低分辨率特征圖沒有很好地對齊。如果下采樣使用雙線性插值,那麼将會在深度值不連續區域出現僞影。2)細節在低分辨率的深度圖中丢失了。從低分辨率深度圖中恢複出具有良好細節的高分辨率深度圖需要複雜的上采樣技術。
為了預測稀疏的高分辨率深度圖,使用MVSNet作為基礎網絡。具體地,首先使用8層的2D CNN網絡來提取圖像特征,然後基于參考圖像的視錐體來建構稀疏的代價體。最後使用3D CNN網絡對代價體進行正則化,并通過soft-argmin操作進行深度圖回歸。
另外稀疏的代價體表示使得3D CNN在空間域的表現類似于dilation為2的空洞卷積。是以在正則化中,有融合更大空間資訊的能力。
圖 3 傳播子產品的圖示
1.2深度圖傳播
圖 4. 可微分高斯-牛頓層的圖示。
1.3 高斯-牛頓優化
在上一步中,我們關注稠密深度圖的高效預測,然後預測得到的深度圖精度是不夠的。是以我們提出使用高斯-牛頓算法對深度圖進行優化。盡管深度圖優化的方法有很多,但出于對效率的考量選擇了高斯-牛頓算法。
1.4 損失函數
按照之前的方法,我們使用估計深度圖和ground-truth深度圖之間的平均絕對誤差 (mean absolute error, MAE) 作為訓練損失函數。初始深度圖和細化後的深度圖都被考慮在内:
圖 5. DTU資料集scan 9的重建結果。如圖中藍色圓圈區域所示,我們的重建方法在精細結構周圍包含了更少的噪聲,證明了我們方法的有效性。
二、實驗結果
2.1 DTU資料集
本文方法與傳統方法和基于學習的方法進行了比較。定量評測結果如表1所示。其中Gipuma的準确性 (Acc.) 最好,本文方法在完整性 (Comp.) 和整體品質 (Overall) 方面表現最佳。圖5展示了本文方法與Point-MVSNet重建結果的可視化對比。本文方法在精細結構處的重建更加幹淨,驗證了本方法的有效性。
表 1. DTU資料集上重建品質的評測結果
更近一步地,如表2所示,作者通過與state-of-the-art方法比較三維點雲重建品質、深度圖分辨率、GPU顯存占用和運作時間方面的性能名額來證明本文的有效性和高效性。
表2. DTU資料集上關于重建品質、深度圖分辨率、GPU顯存占用和運作時間的對比結果
2.2 Tanks and Temples資料集
為了評測本文方法的泛化性能,作者在Tanks and Temples資料集中進行了測試。直接使用在DTU資料集上訓練的模型,沒有經過任何的fine-tuning。輸入圖像的分辨率為1920×1056。深度假設的平面數D = 96,實驗使用MVSNet提供的相機參數。評測結果如表3所示,本文取得了與state-of-the-art方法接近較的結果,證明本方法具有較好的泛化性能。如圖6所示,重建的點雲是稠密且具有良好視覺效果的。
表 3. Tanks and Temples資料集上的評測結果。本文方法獲得了與state-of-the-art方法可比較的實驗結果。
圖 6. Tanks and Temples資料集中intermediate set的重建結果。
三、結論
本文提出一個高效的MVS架構Fast-MVSNet,本架構利用了有稀疏到稠密、由粗糙到精細的政策。首先以較低的成本估計稀疏的高分辨率深度圖。然後通過一個簡單的傳播子產品将稀疏深度圖傳播為稠密深度圖。最後利用可微的高斯-牛頓層來進一步優化深度圖,來提高深度估計的準确性。在兩個具有挑戰性的資料集上 (DTU, Tanks and Temples) 的實驗結果驗證了本方法的有效性和高效性。