BEVFormer治好了我的精神内耗
來源:https://zhuanlan.zhihu.com/p/564295059
文章連結:BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
代碼:https://github.com/zhiqi-li/BEV
開局第一張圖
**來句題外話:**其實我個人來說,我特喜歡把網絡模型結構放在文章開頭的寫法,這種寫法很符合我閱讀論文的習慣 ,我習慣帶着思考和自己的初步了解逐漸探索的過程,這會極大的激發我的閱讀興趣!
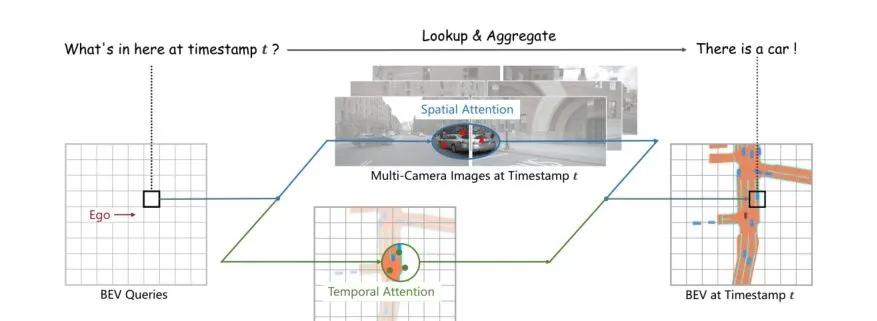
BEVFormer的工作流程
上面這張圖展示了BEVFormer的兩大核心任務:**mutil-camera(多視角相機)**和 bird- eye-view(鳥瞰圖)。BEVFormer利用了Transformer強大的特征提取能力以及Timestamp結構的時序特征的查詢映射能力,在時間次元和空間次元對兩個模态的特征資訊進行聚合,增強整體感覺系統的檢測效果。
那我們在開始讀文章的時候先仔細的分析一下這張圖
BEV Queries部分:根據字面意思推斷應該是用于查詢得到BEV圖上的特征資訊,那用什麼怎麼查詢呢?是Transformer中的QKV嗎?
Temporal Attention部分:根據字面意思推斷是一個時序注意力機制,是提取出不同的時序下鳥瞰圖的特征變化資訊嗎?
Spatial Attention部分:這個部分其實明顯了,将多個視角的空間特征資訊融合,因為多視角本來就是一個空間問題,是以使用空間注意力很正常,但是怎麼使用這個空間注意力呢?然後這個空間注意力長啥樣子呢?我們也還不知道。
是以讓我們帶着問題繼續往下讀這篇文章!
工作的Motivation
衆所周知一個攝像頭也就是幾百或者幾千,我八個攝像頭也不過是萬元内的價格,但是我部署一個雷射雷達,最低也要3-5萬美金。由于LiDAR裝置的價格是真的高,業界一直都有想法希望通過低成本的相機方案去完成自動駕駛汽車的感覺任務,降低整體感覺方案的成本,但是很顯然一直沒有一套很好的方案可以打敗LiDAR呢?
那相機除了夠便宜之外,與基于雷射雷達的方案相比,RGB視覺也能發揮很大的優勢,比如在(紅綠燈、停車線等)的場景中就有很大優勢。
是以為啥之前的相機方案不行?其實之前方法的核心問題是沒有能做到:讓相機更精準的描述3D空間資訊,合理的完成空間三維重建、完成認知決策和協同感覺。
其實大家應該都不多不少有聽說過,或者學習過賽車手都駕馭不了的Tesla(特斯拉)的純視覺自動駕駛感覺方案吧。那麼我們為什麼不嘗試一下加入和優化這套純視覺的BEV方案呢?
介紹
最簡單的方式就是單一的處理每一個視角的資訊,最後再進行後處理融合,但是這樣就會使得這幾個相機彼此沒有參與其中,資訊沒有辦法有效的互動,而且整體顯得很笨拙也不美觀。
受特斯拉的啟發,我們發現了可以使用TransFormer來模組化多視角攝像頭的輸入到BEV的輸出這麼一種映射關系。又因為我們的多視角攝像頭是沒有辦法采集到深度資訊的,是以BEV方法和LiDAR方法的GAP就在這裡了,是以我們應該怎麼去解決這個問題?
1、利用深度估計将資訊處理成僞點雲
2、根據預測的heatmap回歸位置資訊
3、利用深度資訊訓練一個backbone使得這個backbone更加适應3D任務
4、回避depth,将任務放在BEV視角下進行
**本文章就是這樣第四種思路進行設計的,**此前的一些三維物體檢測的工作很大程度會依賴于深度分布和深度值資訊對檢測任務的支援。但是從2D圖像中生成的BEV是不穩定的,如果按照依賴深度資訊和深度分布的LiDAR方法進行顯然是不适合的。是以我們可以嘗試回避Depth的資訊,通過自适應的方式,利用Self-attention動态聚合有價值的特征完成我們的需求。
對于人類視覺感覺系統,時序資訊在推斷物體的運動狀态和識别遮擋物體方面起着至關重要的作用,視訊領域的工作也很好的證明了這一點。但是加入時序資訊的話也要考慮在自動駕駛場景運用,如果隻是簡單的交叉疊加時序資訊的話,會引入許多額外的幹擾資訊(兩個不同時序下的其他環境的變化引入的幹擾資訊)的同時,更增加了額外的計算成本。是以文章也采用了RNN的方式對不同的時間進行一個循環的疊代過程。
文章的主要貢獻就是
實作了一個使用率時序、空間資訊模組化出端到端的BEV生成器。通過這個BEV特征資訊的統一可以更好的支援三維檢測和地圖分割任務。其實後續也可以有更多的任務加入其中!
BEVFormer設計了Spatial Cross Attention子產品提取出多視角圖中感興趣的區域空間資訊進行重建。然後通過Temporal self-Attention子產品對曆史的時序資訊進行融合,通過這兩個子產品得到的空間和時序資訊進行有效的聚合。
BEVFormer在nuScenes測試集上實作了56.9%的NDS,比以前的最佳檢測方法DETR3D高9個點**(56.9%vs.47.9%)**。對于地圖分割任務,我們還實作了最先進的性能,在最具挑戰性的車道分割上比Lift Splat高出5個多點
結構講解

BEVFormer的總體架構
其實上圖這個是最開始結構圖的詳解版本,那麼我們下面主要分析以下三個核心結構Spatial Cross-Attention、Temporal Self-Attention、BEV Queries
BEV Queries
如圖所示文章中建立了H×W×C的空間作為BEVFormer的查詢網格,在将BEV queries 輸入到BEVFormer之前,先将可學習的位置編碼添加到BEV queries Q集合空間中,然後開始學習并更新BEV queries的值。
BEV queries為空間網格的可學習參數,用來捕獲自動駕駛汽車的BEV特征。
每個位于(x,y)位置的query都負責表征對應的最小位置
通過對Spatial和temporal資訊的輪番查詢,生成BEV特征圖。
Spatial Cross-Attention
步驟1:在(x,y)的位置上不同的高度采集pillar的點。
步驟2:可以根據pillar點的3D參數投影到各個2D平面上。
對于一個BEV query,投影的2D點隻能落在某些視圖上,而其他視圖不會被擊中,在這裡我們把被擊中的視圖稱為hit視圖
步驟3:在hit視圖的區域位置中采樣特征資訊
步驟4:我們通過帶權重的方式将這些特征資訊進行一個融合
上圖會更加直覺的體會到Spatial Cross-Attention整個完整步驟流程,其中Out of image就是投影到整個視野以外,那麼這個點就不會參與到查詢的工作中來。
Temporal Self-Attention
步驟1:通過ego-motion(幀間運動)将曆史幀和目前幀映射到網格圖對應于真實世界的位置,将兩個曆史的BEV特征資訊進行對齊。
步驟2:通過Self-attention同時采樣過去幀和目前幀的資訊
步驟3:采樣完成後通過一個權重的方式将特征權重目前的BEV視角,得到一個更加魯棒的特征圖
步驟4:通過一個RNN的方法做3-4次通過一種疊代的方式查詢曆史的目前特征,還能做做一個持續的融合。
優勢和結果
多任務學習:3D目标檢測和地圖語義分割
**可遷移性:**常用的2D檢測頭也可以很好通過很小的修改遷移到3D檢測頭上面去。
BEVFormer在nuScenes測試集上實作了56.9%的NDS,比以前的最佳檢測方法DETR3D高9個點**(56.9%vs.47.9%)**。對于地圖分割任務,我們還實作了最先進的性能,在最具挑戰性的車道分割上比Lift Splat高出5個多點
56.9vs47.9
28.0vs22.0
消融實驗總結
1、強的backbone依然是漲點的關鍵
2、Local-attention要不global attention的效果要更好,global attention更加耗時,性能也不太好
3、時序資訊的必要,能夠有效的提高速度上的名額
4、不建議多任務頭,多任務頭在3D目标檢測表現ok,但是在BEV map的語義分割中性能還是較差。
提問
Q1:其實純視覺到底還能走多遠?能不能真正的和LiDAR的效果做到一個大差不差的一個性能
Q2:打不過就加入,那麼我們的多模态的方案到底怎麼做才會讓視覺與LiDAR的融合更加的優雅
Q3:對于BEV的部署要求,BEV能不能更友好的支援部署的要求!
我看完文章之後其實看完了這篇文章之後,會對第二個問題更加有共鳴,我們能不能讓不同模态的融合方式更加優雅,在語義資訊以及空間資訊上對兩個模态做更好的一個融合,更高效的資訊補充。
對于融合的方式,我們常見的有下面幾種
但是我們多用的融合方式通常是Early-fusion和Late-fusion
我們最直接,最友善的思路就是把不同模态的資訊concatenate,然後一次性輸入到模型當中,最後得到一個輸出。
BEVFusion就采用的是這種方案,将多視角圖與LiDAR投影到BEV視角下直接的通道疊加做一個效果出來
把整體的決策和融合交給黑箱,這顯然是最簡單,但是我認為也是最不負責任的做法。因為這壓根沒有辦法針對不同模型的特征資訊進行優化,我們隻能把希望寄托在Encoder的特征學習能力足夠強大,可以學習到自身的特征,和彼此之間的聯系,但是如果兩個模态資訊并非強相關,也并非都是強模态,這樣一定會帶來的強模态搶占弱模态的事情發生。如果發生搶占,可能會在兩個模态上識别效果很差。
我個人也其實不太喜歡後融合,如果後處理融合的話,兩個模态的資訊互動其實非常的不充分,也很難從裡面學習到兩個模态之間的聯系資訊,這樣的做法其實是吃力不讨好的。