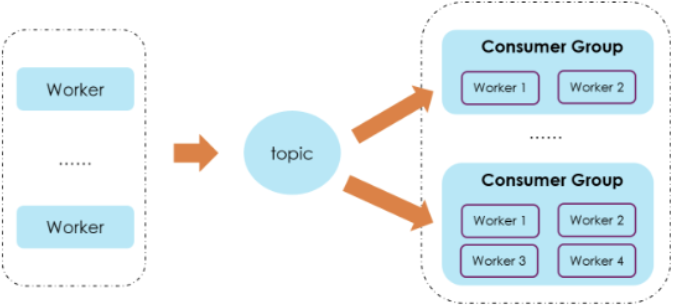
Kafka消費者以消費者組(Consumer Group)的形式消費一個topic,釋出到topic中的每個記錄将傳遞到每個訂閱消費者者組中的一個消費者執行個體。Consumer Group 之間彼此獨立,互不影響,它們能夠訂閱相同的一組主題而互不幹涉。
生産環境中,消費者在消費消息的時候若不考慮消費者的相關特性(比如主動設定offset重複曆史消息),由于一些代碼問題也可能會出現重複消費的問題。
一、基本概念
在讨論重複消費之前,首先來看一下kafka中跟消費者有關的幾個重要配置參數。
- enable.auto.commit:預設值true,表示消費者會周期性自動送出消費的offset
- auto.commit.interval.ms:在enable.auto.commit 為true的情況下, 自動送出的間隔,預設值5000ms
- max.poll.records: 單次消費者拉取的最大資料條數,預設值500
- max.poll.interval.ms:預設值5分鐘,表示若5分鐘之内消費者沒有消費完上一次poll的消息,那麼consumer會主動發起離開group的請求
在常見的使用場景下,我們的消費者配置比較簡單,特别是內建Spring元件進行消息的消費,通常情況下我們僅需通過一個注解就可以實作消息的消費。例如如下代碼:
@KafkaListener(topics = {"malu"},groupId="group1")
public void consumeMsg(ConsumerRecord<?, ?> record) throws Exception{
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
if (kafkaMessage.isPresent()) {
Object message = kafkaMessage.get();
//do something
Thread.sleep(1000);
}
}
這段代碼中我們配置了一個kafka消費注解,制定消費名為"test1"的topic,這個消費者屬于"group1"消費組。開發者隻需要對得到的消息進行處理即可。那麼這段 代碼中的消費者在這個過程中是如何拉取消息的呢,消費者消費消息之後又是如何送出對應消息的位移(offset)的呢?
實際上在autocommit=true時,當上一次poll方法拉取的消息消費完時會進行下一次poll,在經過auto.commit.interval.ms間隔後,下一次調用poll時會送出所有已消費消息的offset。
為了驗證consumer自動送出的時機,配置消費者參數如下:
props.put("enable.auto.commit","true");//自動送出
props.put("auto.commit.interval.ms","30000");//offset間隔
props.put("max.poll.records",20);//單次拉取消息最大值
同時為了便于擷取消費者消費進度,以下代碼通過kafka提供的相關接口定時每隔5s擷取一次消費者的消費進度資訊,并将擷取到的資訊列印到控制台。
@Scheduled(fixedRate = 5000)
public void schedule() throws TimeoutException {
Map<TopicPartition, OffsetAndMetadata> offset1 = lag0f("group1","localhost:9092");
for (Map.Entry<TopicPartition, OffsetAndMetadata> entry : offset1.entrySet()) {
System.out.println(new Date().toString() +
"consumer groupl:topic-"+entry.getKey().topic()+
"partition-"+entry.getKey().partition()+
"offset"+entry.getValue().offset());
}
}
public static Map<TopicPartition, OffsetAndMetadata> lag0f(String groupID, String bootstrapServers) throws TimeoutException {
Properties props = new Properties();
props.put(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
try (AdminClient client = AdminClient.create(props)) {
ListConsumerGroupOffsetsResult result = client.listConsumerGroupOffsets(groupID);
try {
Map<TopicPartition, OffsetAndMetadata> consumedOffsets = result.partitionsToOffsetAndMetadata().get(10, TimeUnit.SECONDS);
return consumedOffsets;
} catch (Exception e){
return Collections.emptyMap();
}
}
}
對于topic test1,為了便于觀察消費情況,我們僅設定了一個partition。對于消費者組group1的配置參數,消費者會單次拉取消息數20條,消費每條消息耗費1s,部分記錄日志列印結果如下:

從日志中可以看出,消費組的offset每40s更新一次,因為每次poll會拉取20條消息,每個消息消費1s,在第一次poll之後,下一次poll因為沒有達到auto.commit.interval.ms=30s,是以不會送出offset。第二次poll時,已經經過40s,是以這次poll會送出之前兩次消費的消息,offset增加40。也就是說隻有在經過auto.commit.interval.ms間隔後,并且在下一次調用poll時才會送出所有 已消費消息的offset。
二、重複消費問題
考慮到以上消費者消費消息的特點,在配置自動送出enable.auto.commit 預設值true情況下,出現重複消費的場景有以下幾種:
1、Consumer 在消費過程中,應用程序被強制kill掉或發生異常退出
例如在一次poll500條消息後,消費到200條時,程序被強制kill消費導緻offset 未送出,或出現異常退出導緻消費到offset未送出。下次重新開機時,依然會重新拉取這500消息,這樣就造成之前消費到200條消息重複消費了兩次。是以在有消費者線程的應用中,應盡量避免使用kill -9這樣強制殺程序的指令。
2、消費者消費時間過長
max.poll.interval.ms參數定義了兩次poll的最大間隔,它的預設值是 5 分鐘,表示你的 Consumer 程式如果在 5 分鐘之内無法消費完 poll 方法傳回的消息,那麼 Consumer 會主動發起“離開組”的請求,導緻未送出offset,Coordinator 也會開啟新一輪 Rebalance,進而重複消費。
為了複現這種場景,我們對消費者重新進行了配置,消費者參數如下:
props.put("enable.auto.commit","true");//自動送出
props.put("auto.commit.interval.ms","5000");//offset間隔
props.put("max.poll.records",11);//單次拉取消息最大值
@KafkaListener(topics = {"test2"},groupId="group22")
public void consumeMsg(ConsumerRecord<?, ?> record) throws Exception{
System.out.println(new Date().toString()+":group22 "+record.toString());
Thread.sleep(30000);
}
在消費過程中消費者單次會拉取11條消息,每條消息耗時30s,11條消息耗時 5分鐘30秒,由于max.poll.interval.ms 預設值5分鐘,是以理論上消費者無法在5分鐘内消費完,consumer會離開組,導緻rebalance。
實際運作日志如下:
可以看到在消費完第11條消息後,因為消費時間超出max.poll.interval.ms 預設值5分鐘,這時consumer已經離開消費組了,開始rebalance,是以送出offset失敗。之後重新rebalance,消費者再次配置設定partition後,再次poll拉取消息依然從之前消費過的消息處開始消費,這樣就造成重複消費。而且若不解決消費單次消費時間過長的問題,這部分消息可能會一直重複消費。
對于上述重複消費的場景,若不進行相應的處理,那麼有可能造成一些線上問題。為了避免因重複消費導緻的問題,以下提供了兩種解決重複消費的思路:
1)提高消費能力:
提高單條消息的處理速度,例如對消息進行中比 較耗時的步驟可通過異步的方式進行處理、利用多線程處理等。在縮短單條消息消費時常的同時,根據實際場景可将max.poll.interval.ms值設定大一點,避免不必要的rebalance,此外可适當減小max.poll.records的值,預設值是500,可根 據實際消息速率适當調小。這種思路可解決因消費時間過長導緻的重複消費問題, 對代碼改動較小,但無法絕對避免重複消費問題。
2)引入單獨去重機制:
例如生成消息時,在消息中加入唯一辨別符如消息id等。在消費端,我們可以儲存最近的1000條消息id到redis或mysql表中,配置max.poll.records的值小于1000。在消費消息時先通過前置表去重後再進行消息的處理。
此外,在一些消費場景中,我們可以将消費的接口幂等處理,例如資料庫的查 詢操作天然具有幂等性,這時候可不用考慮重複消費的問題。對于例如新增資料的操作,可通過設定唯一鍵等方式以達到單次與多次操作對系統的影響相同,進而使接口具有幂等性。
https://zhuanlan.zhihu.com/p/112745985
補充:對于自動送出,處理消息失敗後如何補償?
上面介紹了自動送出的時間間隔,以及每次拉取消息的數量參數。就拿上面的例子來做一個說明:
props.put("enable.auto.commit","true");//自動送出
props.put("auto.commit.interval.ms","30000");//offset間隔
props.put("max.poll.records",20);//單次拉取消息最大值
每次poll會拉取20條消息,每個消息消費1s,在第一次poll之後,下一次poll因為沒有達到auto.commit.interval.ms=30s,是以不會送出offset。第二次poll時,已經經過40s,是以這次poll會送出之前兩次消費的消息,offset增加40。也就是說隻有在經過auto.commit.interval.ms間隔後,并且在下一次調用poll時才會送出所有 已消費消息的offset。
在第二次poll中,假設處理的消息有的失敗了,由于自動送出機制,offset已經增加了40,是以無法再次消費失敗的消息了。通常,我們會在代碼中将消費失敗的消息,再次發送到kafka中,或者記錄到日志中,作為補償。