文章結構
1.特殊的
1.1limit
1.2主鍵、外鍵、非空
2.屬性類型
3.增删改
4.查詢
4.1單表查詢
4.2多表查詢
4.3附加運算查詢
4.4聚集函數運算查詢
1.特殊的
1.1limit
LIMIT 用于強制 SELECT 語句傳回指定的記錄數。
| 參數 | 意義 |
|---|---|
| a,b | a為第一個傳回記錄行的偏移量(初始偏移量是0),b為傳回記錄行的數目 |
| a | a表示傳回記錄行的數目 |
| a,-1 | 某一個偏移量到記錄集的結束所有的記錄行 |
1.2其他的
| 類型 | 含義 | 示例 |
|---|---|---|
| primary key | 主鍵,後面括号中是作為主鍵的屬性 | primary key(student_id) |
| foreign key references | 外鍵,括号中為外鍵,references後為外鍵的表 | foreign key(course_id) references Course |
| not null | 不為空,前面為屬性的定義 | name varchar(10) not null |
2.屬性類型
| 類型 | 含義 |
|---|---|
| char(n) | 存放固定長度的字元串,使用者指定長度為n。如果沒有使用n個長度則會在末尾添加空格。 |
| varchar(n) | 可變長度的字元串,使用者指定最大長度n。char的改進版,大多數情況下我們最好使用varchar。 |
| int | 整數類型 |
| smallint | 小整數類型 |
| numeric(p,d) | 定點數,精度由使用者指定。這個數有p位數字(包括一個符号位)d位在小數點右邊。 |
| real ,double precision | 浮點數和雙精度浮點數。 |
| float(n) | 精度至少位n位的浮點數 |
3.增删改
| 類型 | 含義 |
|---|---|
| create table | 建立一張表 |
| insert into…values | 向表中插入一條資訊 |
| delete from | 從表中删除一條資訊 |
| update…set…where | 在where的位置,更新内容為set的值 |
| drop table | 删除表 |
| alter table…add | 向表中添加某個屬性 |
| alter table…drop | 将表中的某個屬性删除 |
4.查詢
4.1單表查詢
| 類型 | 含義 |
|---|---|
| select | 表示要查找出的表所含有的屬性 |
| from | 表示要操作的表 |
| where | 判斷條件,根據該判斷條件選擇資訊 |
| distinct | 在select後加入關鍵字distinct表示将結果去重 |
| all | 在select後加入關鍵字all表示不去重(預設) |
| and | 在where中使用and表示将判斷條件連接配接起來 |
| or | 在where中使用or表示判斷條件多選一 |
| not | 在where中使用not表示判斷條件取反 |
4.2多表查詢
| 類型 | 含義 |
|---|---|
| A,B | 在from後面通過逗号連接配接多張表,表示将這些表進行笛卡兒積運算 |
| natural join | 将natural join關鍵字前後的兩張表進行自然連接配接運算 |
| A join B using © /on A.id=B.id | join 是 inner join 的簡寫形式,将A和B通過c屬性自然連接配接,或通過on添加條件 |
| left join | left outer join 的簡寫形式,包含左表的所有行,對應的右表行可能為空 |
| right join | 包含右表的所有行,對應的左表行可能為空 |
| full join | 隻包含左右表都比對并且不為空的行 |
補充①:笛卡爾積
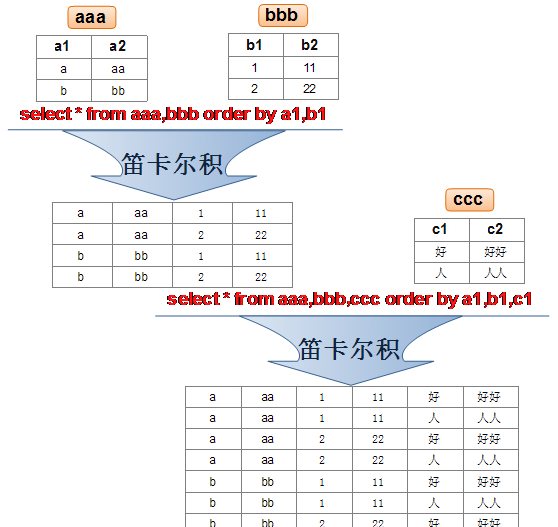
補充②:left join 和 inner join 差別和優化
| 差別 | 優化 |
|---|---|
| left join / left outer join :是做左外關聯,主表内容都會顯示;符合關聯條件的附表内容才會顯示出來 | |
| inner join / join:是内關聯,沒有主表附表的概念;兩個表中,同時符合關聯條件的資料才會顯示出來 | sql盡量使用資料量小的表做主表,這樣效率高,但是有時候因為邏輯要求,要使用資料量大的表做主表,此時使用left join 就會比較慢,即使關聯條件有索引。在這種情況下就要考慮是不是能使用inner join 了。因為inner join 在執行的時候回自動選擇最小的表做基礎表,效率高 |
補充③:mysql 内連接配接、自然連接配接、外連接配接的差別
補充④:jjoin using和join on的差別
join using 後面接 兩張表中都存在的字段 (字段名稱 一樣)
join on 後面接 兩張表中中需要關聯的字段 (字段名稱不需要一樣 a.id = b.id )
4.3附加運算查詢
| 類型 | 含義 |
|---|---|
| as | 将as前的關系起一個别名,在此語句中,可以用别名來代指這個表 |
| * | 在select中通過: “表名.*” 來表示查找出這個表中所有的屬性 |
| order by | 讓查詢結果中的資訊按照給定的屬性排序(預設升序,上小下大) |
| desc | 在order by之後的屬性後使用,表示采用降序排序 |
| asc | 在order by之後的屬性後使用,表示采用升序排序(預設) |
| between | 在where中使用between表示一個數在兩個數值之間取值 |
| not between | between的反義詞,在兩個數之外取值 |
| union/union all | 将兩個SQL語句做并運算,并且自動去重,添加all表示不去重 |
| intersect/intersect all | 将兩個SQL語句做交運算,并且自動去重,添加all表示不去重 |
| except/except all | 将兩個SQL語句做差運算,并且自動去重,添加all表示不去重 |
| is null | 在where中使用is null表示這個值是空值 |
| is not null | 在where中使用is not null表示這個值不是空值 |
4.4聚集函數運算查詢
| 類型 | 含義 |
|---|---|
| avg | 平均值 |
| min | 最小值 |
| max | 最大值 |
| sum | 總和 |
| count | 計數 |
| distinct | 表示将distinct後的屬性去重 |
| group by | 将在group by上取值相同的資訊分在一個組裡;可用于大表去重、挑選分組 |
| having | 對group by産生的分組進行篩選,可以使用聚集函數 |
select class,avg(score) as avg_score
from Student natural join Math
group by class
having avg(score)< 60;
#在Student與Math表自然連接配接的結果中按照班級分組,并且去除那些班級的平均成績沒到60的班級,剩下的班級和該班成績的平均數(該班成績的平均數這個屬性被重命名為avg_score)作為一張新表被輸出出來
補充①:where語句中不能使用聚合函數
大緻解釋如下,sql語句的執行過程是:from–>where–>group by -->having — >order by --> select;
聚合函數是針對結果集進行的,但是where條件并不是在查詢出結果集之後運作,是以主函數放在where語句中,會出現錯誤,
而having不一樣,having是針對結果集做篩選的,是以我門一般吧組函數放在having中,用having來代替where,having一般跟在group by後
![SQL優化SQL語句優化的目的[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)