工作中,每天要寫報告,要将各種資料彙總,發給相關人員。有的時候,系統或者工具不能滿足我們快速拿到資料,很費時。關鍵有的時候太忙,還容易忘記。
看到同僚每天花很多時間來寫測試報告,從jira裡面總結資料,然後編輯各種格式,寫成郵件發出來。雖然jira裡面dashboard也可以看到一些,也能導出excel,但是管理人員不會去看,要看最終能得出結論的資料。
我都是每天自動發報告,通過自動調用jira接口,資料分析總結,生成報表,給自己發郵件,自己稽核一下,就可以快速下班了。
先看看效果:
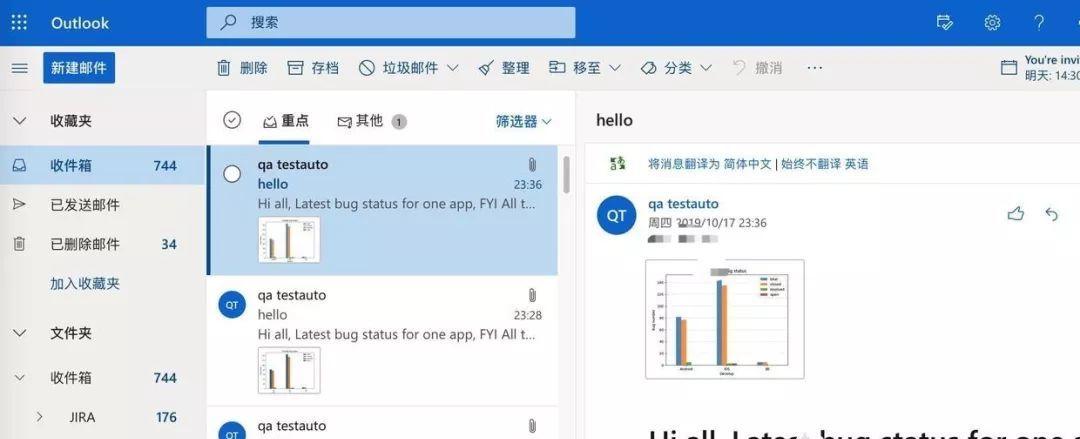
這個是部分的柱狀圖,這樣相關人士一眼就能得到結論,比冰冷的資料更直覺。

如果關心資料,這個表能很好展現。
雖然jira接口很強大,基本上手工操作的,接口裡面都有方法,我覺得還是有點不好的地方,就是太瑣碎,沒有子產品化。如果你要組裝成一個你想要的,還得費很大功夫。是以我還利用了爬蟲,直接得一個完整的表。建了個filter,直接登陸進去,通過pandas 的read_html就可以得到一個完整的矩陣表,比調用jira接口去組裝快多了。
先看看jira接口是如何使用的,先要安裝jira的這個包。
pip install jira
複制
裝完後就可以直接使用了, 先要登陸
from jira import JIRA
jira = JIRA(server='http://127.0.0.1:8080', basic_auth=('user_name', 'password'))
print(jira.user(jira.current_user()))#目前使用者
複制
jira的功能很多,用得多的可能是查詢。
result=jira.search_issues("labels =Snake AND status not in (Closed, Resolved, 'UAT GLed')")
複制
但是這樣查詢有個問題,隻顯示50個資料。
是以還得加個字段,maxResults,給個大點的值得。
result = jira.search_issues(sql, maxResults=600)
複制
如果要對某個資料的某個字段查詢,是這樣的:
issues = jira.issue("ME-8431")
print(issues)
print(issues.fields.priority)
複制
fields根據你的需要選擇。好了,jira這塊就說這麼多,下面來說用爬蟲如何操作。
jira也提供了session式的登陸接口:
rest/gadget/1.0/login 登入URI rest/gadget/1.0/login
os_username 使用者名 JIRA登入使用者名
os_password 使用者密碼 JIRA登入使用者密碼
os_cookie cookie模式 true為使用cookie方式登入模式,false為關閉 複制
這樣就能登陸進去了:
filter_url = "xxx/?filter=163201"
base_url = "Snakeisthebest/rest/gadget/1.0/login"
data = {
"os_username": jira_username,
"os_password": jira_password,
"os_cookie": True
}
res=requests.session()
res.post(base_url,data)
result=res.get(filter_url)
import pandas as pd
result2=pd.read_html(result.text)
print(result2)
b = pd.DataFrame(result2)
複制
這樣,資料就拿到了。對資料清洗,畫圖表,都可以了。可以寫個公用的畫各種圖表的函數,類似這樣的。
def bug_status_picture(df):
df.plot.bar()
plt.xlabel('Develop')
# 設定y周标簽
plt.ylabel('Bug number')
# 設定圖表标題
plt.title('OneApp bug status')
# # 設定圖例的文字和在圖表中的位置
# plt.legend(, loc='upper right')
# 設定背景網格線的顔色,樣式,尺寸和透明度
plt.grid(color='#95a5a6', linestyle='--', linewidth=1, axis='y', alpha=0.4)
plt.show()
plt.savefig("bug_{}.png".format(datetimenow))
複制
這樣有個問題,生成的圖檔中x軸的字是豎着的,可以加個參數解決。
df.plot.bar(alpha=0.75, rot=0)
複制
将生成的結果,發郵件,如果用text,黑乎乎的,不美觀。用html的,可以搞樣式,就美觀很多。
問題來了,我知道pandas 的to_html可以弄成一個html的圖表,但是多個dataframe怎麼弄。
網上我搜到了例子。
def write_htmls(df_list):
HEADER = '''
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
'''
FOOTER = '''
</body>
</html>
'''
with open(os.path.join(os.getcwd(), 'test.html'), 'w') as f:
f.write(HEADER)
for each_df in df_list:
print(type(each_df))
# f.write('<h1><strong>' + '自定義dataframe名' +'</strong></h1>')
f.write(each_df.to_html(classes='classname'))
f.write(FOOTER)
複制
生成的結果很醜,嘗試換個樣式。
def generate_df_html(arg):
html_str = ""
html_temp = """
<h2>{}</h2>
<div>
<h4></h4>
{}
</div>
<hr>
"""
for k in sorted(arg.keys()):
df_html = arg[k].to_html(escape=False)
html_str = html_str + html_temp.format(k, df_html)
if k == 'Total_bugs':
html_str = html_str + """<table><tr><td><img src="cid:Total_bugs"></td></tr></table>"""
return html_str
def get_html_msg(df):
head = \
"""
<head>
<meta charset="utf-8">
<STYLE TYPE="text/css" MEDIA=screen>
table.dataframe {
border-collapse: collapse;
border: 2px solid #a19da2;
/*居中顯示整個表格*/
margin: left;
}
table.dataframe thead {
border: 2px solid #91c6e1;
background: #f1f1f1;
padding: 10px 10px 10px 10px;
color: #333333;
}
table.dataframe tbody {
border: 2px solid #91c6e1;
padding: 10px 10px 10px 10px;
}
table.dataframe tr {
}
table.dataframe th {
vertical-align: top;
font-size: 14px;
padding: 10px 10px 10px 10px;
color: #105de3;
font-family: arial;
text-align: center;
}
table.dataframe td {
text-align: center;
padding: 10px 10px 10px 10px;
}
# body {
# font-family: 宋體;
# }
# h1 {
# color: #5db446
# }
div.header h2 {
color: #0002e3;
font-family: 黑體;
}
div.content h2 {
text-align: left;
font-size: 18px;
# text-shadow: 2px 2px 1px #de4040;
#color: #fff;
color:#008eb7
font-weight: bold;
#background-color: #008eb7;
# line-height: 1.5;
# margin: 20px 0;
# box-shadow: 10px 10px 5px #888888;
# border-radius: 5px;
}
h3 {
font-size: 22px;
background-color: rgba(0, 2, 227, 0.71);
text-shadow: 2px 2px 1px #de4040;
color: rgba(239, 241, 234, 0.99);
line-height: 1.5;
}
h4 {
color: #e10092;
font-family: 楷體;
font-size: 20px;
text-align: center;
}
</STYLE>
</head>
"""
# 構造模闆的附件(100)
message = """
Hi all,
Latest bug status for snake, FYI
"""
body = \
"""
<body>
<div align="left" class="header">
<!--标題部分的資訊-->
<h1 align="left">{}</h1>
</div>
<hr>
<div class="content">
<!--正文内容-->
{}
<p style="text-align: left">
Any question, please let me know, Thanks!
</p>
</div>
</body>
""".format(message, df)
html_msg = "<html>" + head + body + "</html>"
print(html_msg)
# 這裡是将HTML檔案輸出,作為測試的時候,檢視格式用的,正式腳本中可以注釋掉
fout = open('{}.html'.format(datetimenow), 'w', encoding='UTF-8', newline='')
fout.write(html_msg)
fout.close()
return html_msg
複制
結果看起來還湊合:
現在開始需要利用stmp來發郵件了,選擇用html加附件的模式,網上找了個例子,一般我喜歡用yagmail,好像不能滿足。
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.mime.image import MIMEImage
msg['From'] = "[email protected]" #郵件發件人
msg['To'] = "[email protected]" #郵件接收人
msg['Subject'] = "hello world" ##郵件主題
def addimg(img_src,imgid):
fp = open(img_src,'rb')
msgImage = MIMEImage(fp.read())
fp.close()
msgImage.add_header('Conteng-ID',imgid)
return msgImage ##傳回msgImage對象
msg_text = MIMEText("""<table><tr><td><img src="cid:aa"></td></tr></table>""","html","utf-8")
#建立MIMEMultipart對象,采用related定義内嵌資源
msg = MIMEMultipart('related')
msg.attach(msg_text)
msg.attach(addimg("C:\aa.img",aa)) ##這裡的aa要與msg_text裡的aa對應
#發送郵件
server = smtplib.SMTP()
server.connect('smtp.XXX.com',"25")
server.starttls() ##啟動安全傳輸模式
server.login('XXX','XXXXX') #XXX為使用者名,XXXXX為密碼
server.sendmail(msg['From'], msg['To'],msg.as_string()) #這裡的前兩個參數自定義
server.quit()
複制
測試,發現了一個問題,就是如果用爬蟲方式弄的資料,jira裡面的priority拿不到,因為頁面用的是圖示。
這個可以用接口來查詢一下,在datafram裡面來替換。
對某列的操作,可以用apply或map就可以了
對某列操作,可以用map或者apply
eg: df["FullName"]=df["Name"].map(lambda x: x.split(",")[1].strip())
對一列資料去空格的方法:
def qukong(hang):
return hang['city'].strip()
dataframe['city']=dataframe.apply(qukong,axis=1) # axis=1表示對每一行做相同的操作
複制
我用的是map。
bug_result_df["Priority"]=bug_result_df["Key"].map(lambda x: (jira.issue(x)).fields.priority)
show_list = ["Key", "Summary", "Assignee", "Status","Priority", "Created"]
bug_detail_df = bug_result_df[show_list]
複制
選擇需要展示的列切片就完美解決了這個問題。
總結
由于這塊太久沒弄了,也有段時間沒寫代碼了,寫起來不是那麼順,各種問題,但都被解決了。
這個玩意作用雖然很小,如果這麼多人,天天能節省幾分鐘,一年下來也是個很可觀的效率提升。
雖然公司不能寫代碼,晚上在家熬夜寫點東西,也是很爽的。
然後跟同僚分享了,他們都覺得好,這樣就推廣起來了。有的時候,獨樂樂,不如衆樂樂。
更多精彩,請關注微信公衆号:python愛好部落