1.前言
讀這篇文章之前希望你能好好的閱讀: 你應該知道的緩存進化史 和 如何優雅的使用緩存? 。這兩篇文章主要從一些實戰上面去介紹如何去使用緩存。在這兩篇文章中我都比較推薦Caffeine這款本地緩存去代替你的Guava Cache。本篇文章我将介紹Caffeine緩存的具體有哪些功能,以及内部的實作原理,讓大家知其然,也要知其是以然。有人會問:我不使用Caffeine這篇文章應該對我沒啥用了,别着急,在Caffeine中的知識一定會對你在其他代碼設計方面有很大的幫助。當然在介紹之前還是要貼一下他和其他緩存的一些比較圖:
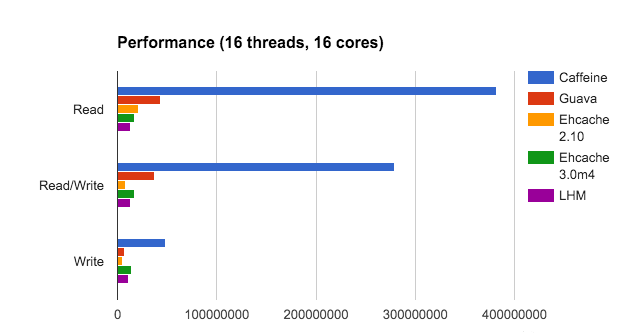
可以看見Caffeine基本從各個次元都是相比于其他緩存都高,廢話不多說,首先還是先看看如何使用吧。
1.1如何使用
Caffeine使用比較簡單,API和Guava Cache一緻:
public static void main(String[] args) {
Cache<String, String> cache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.SECONDS)
.expireAfterAccess(1,TimeUnit.SECONDS)
.maximumSize(10)
.build();
cache.put("hello","hello");
} 複制
2.Caffeine原理簡介
2.1W-TinyLFU
傳統的LFU受時間周期的影響比較大。是以各種LFU的變種出現了,基于時間周期進行衰減,或者在最近某個時間段内的頻率。同樣的LFU也會使用額外空間記錄每一個資料通路的頻率,即使資料沒有在緩存中也需要記錄,是以需要維護的額外空間很大。
可以試想我們對這個維護空間建立一個hashMap,每個資料項都會存在這個hashMap中,當資料量特别大的時候,這個hashMap也會特别大。
再回到LRU,我們的LRU也不是那麼一無是處,LRU可以很好的應對突發流量的情況,因為他不需要累計資料頻率。
是以W-TinyLFU結合了LRU和LFU,以及其他的算法的一些特點。
2.1.1頻率記錄
首先要說到的就是頻率記錄的問題,我們要實作的目标是利用有限的空間可以記錄随時間變化的通路頻率。在W-TinyLFU中使用Count-Min Sketch記錄我們的通路頻率,而這個也是布隆過濾器的一種變種。如下圖所示:

如果需要記錄一個值,那我們需要通過多種Hash算法對其進行處理hash,然後在對應的hash算法的記錄中+1,為什麼需要多種hash算法呢?由于這是一個壓縮算法必定會出現沖突,比如我們建立一個Long的數組,通過計算出每個資料的hash的位置。比如張三和李四,他們兩有可能hash值都是相同,比如都是1那Long[1]這個位置就會增加相應的頻率,張三通路1萬次,李四通路1次那Long[1]這個位置就是1萬零1,如果取李四的通路評率的時候就會取出是1萬零1,但是李四命名隻通路了1次啊,為了解決這個問題,是以用了多個hash算法可以了解為long[][]二維數組的一個概念,比如在第一個算法張三和李四沖突了,但是在第二個,第三個中很大的機率不沖突,比如一個算法大概有1%的機率沖突,那四個算法一起沖突的機率是1%的四次方。通過這個模式我們取李四的通路率的時候取所有算法中,李四通路最低頻率的次數。是以他的名字叫Count-Min Sketch。
這裡和以前的做個對比,簡單的舉個例子:如果一個hashMap來記錄這個頻率,如果我有100個資料,那這個HashMap就得存儲100個這個資料的通路頻率。哪怕我這個緩存的容量是1,因為Lfu的規則我必須全部記錄這個100個資料的通路頻率。如果有更多的資料我就有記錄更多的。
在Count-Min Sketch中,我這裡直接說caffeine中的實作吧(在FrequencySketch這個類中),如果你的緩存大小是100,他會生成一個long數組大小是和100最接近的2的幂的數,也就是128。而這個數組将會記錄我們的通路頻率。在caffeine中規定頻率最大為15,15的二進制位1111,總共是4位,而Long型是64位。是以每個Long型可以放16種算法,但是caffeine并沒有這麼做,隻用了四種hash算法,每個Long型被分為四段,每段裡面儲存的是四個算法的頻率。這樣做的好處是可以進一步減少Hash沖突,原先128大小的hash,就變成了128X4。
一個Long的結構如下:
我們的4個段分為A,B,C,D,在後面我也會這麼叫它們。而每個段裡面的四個算法我叫他s1,s2,s3,s4。下面舉個例子如果要添加一個通路50的數字頻率應該怎麼做?我們這裡用size=100來舉例。
- 首先确定50這個hash是在哪個段裡面,通過hash & 3(3的二進制是11)必定能獲得小于4的數字,假設hash & 3=0,那就在A段。
- 對50的hash再用其他hash算法再做一次hash,得到long數組的位置,也就是在長度128數組中的位置。假設用s1算法得到1,s2算法得到3,s3算法得到4,s4算法得到0。
- 因為S1算法得到的是1,是以在long[1]的A段裡面的s1位置進行+1,簡稱1As1加1,然後在3As2加1,在4As3加1,在0As4加1。
這個時候有人會質疑頻率最大為15的這個是否太小?沒關系在這個算法中,比如size等于100,如果他全局提升了size*10也就是1000次就會全局除以2衰減,衰減之後也可以繼續增加,這個算法再W-TinyLFU的論文中證明了其可以較好的适應時間段的通路頻率。
2.2讀寫性能
在guava cache中我們說過其讀寫操作中夾雜着過期時間的處理,也就是你在一次Put操作中有可能還會做淘汰操作,是以其讀寫性能會受到一定影響,可以看上面的圖中,caffeine的确在讀寫操作上面完爆guava cache。主要是因為在caffeine,對這些事件的操作是通過異步操作,他将事件送出至隊列,這裡的隊列的資料結構是RingBuffer,不清楚的可以看看這篇文章,你應該知道的高性能無鎖隊列Disruptor。然後會通過預設的ForkJoinPool.commonPool(),或者自己配置線程池,進行取隊列操作,然後在進行後續的淘汰,過期操作。
當然讀寫也是有不同的隊列,在caffeine中認為緩存讀比寫多很多,是以對于寫操作是所有線程共享一個Ringbuffer。
對于讀操作比寫操作更加頻繁,進一步減少競争,其為每個線程配備了一個RingBuffer:
2.3資料淘汰政策
在caffeine所有的資料都在ConcurrentHashMap中,這個和guava cache不同,guava cache是自己實作了個類似ConcurrentHashMap的結構。在caffeine中有三個記錄引用的LRU隊列:
- Eden隊列:在caffeine中規定隻能為緩存容量的%1,如果size=100,那這個隊列的有效大小就等于1。這個隊列中記錄的是新到的資料,防止突發流量由于之前沒有通路頻率,而導緻被淘汰。比如有一部新劇上線,在最開始其實是沒有通路頻率的,防止上線之後被其他緩存淘汰出去,而加入這個區域。伊甸區,最舒服最安逸的區域,在這裡很難被其他資料淘汰。
- Probation隊列:叫做緩刑隊列,在這個隊列就代表你的資料相對比較冷,馬上就要被淘汰了。這個有效大小為size減去eden減去protected。
- Protected隊列:在這個隊列中,可以稍微放心一下了,你暫時不會被淘汰,但是别急,如果Probation隊列沒有資料了或者Protected資料滿了,你也将會被面臨淘汰的尴尬局面。當然想要變成這個隊列,需要把Probation通路一次之後,就會提升為Protected隊列。這個有效大小為(size減去eden) X 80% 如果size =100,就會是79。
這三個隊列關系如下:
- 所有的新資料都會進入Eden。
- Eden滿了,淘汰進入Probation。
- 如果在Probation中通路了其中某個資料,則這個資料更新為Protected。
- 如果Protected滿了又會繼續降級為Probation。
對于發生資料淘汰的時候,會從Probation中進行淘汰。會把這個隊列中的資料隊頭稱為受害者,這個隊頭肯定是最早進入的,按照LRU隊列的算法的話那他其實他就應該被淘汰,但是在這裡隻能叫他受害者,這個隊列是緩刑隊列,代表馬上要給他行刑了。這裡會取出隊尾叫候選者,也叫攻擊者。這裡受害者會和攻擊者皇城PK決出我們應該被淘汰的。
通過我們的Count-Min Sketch中的記錄的頻率資料有以下幾個判斷:
- 如果攻擊者大于受害者,那麼受害者就直接被淘汰。
- 如果攻擊者<=5,那麼直接淘汰攻擊者。這個邏輯在他的注釋中有解釋:
他認為設定一個預熱的門檻會讓整體命中率更高。
- 其他情況,随機淘汰。
3.Caffeine功能剖析
在Caffeine中功能比較多,下面來剖析一下,這些API到底是如何生效的呢?
3.1 百花齊放-Cache工廠
在Caffeine中有個LocalCacheFactory類,他會根據你的配置進行具體Cache的建立。
可以看見他會根據你是否配置了過期時間,remove監聽器等參數,來進行字元串的拼裝,最後會根據字元串來生成具體的Cache,這裡的Cache太多了,作者的源碼并沒有直接寫這部分代碼,而是通過Java Poet進行代碼的生成:
3.2 轉瞬即逝-過期政策
在Caffeine中分為兩種緩存,一個是有界緩存,一個是無界緩存,無界緩存不需要過期并且沒有界限。在有界緩存中提供了三個過期API:
- expireAfterWrite:代表着寫了之後多久過期。
- expireAfterAccess: 代表着最後一次通路了之後多久過期。
- expireAfter:在expireAfter中需要自己實作Expiry接口,這個接口支援create,update,以及access了之後多久過期。注意這個API和前面兩個API是互斥的。這裡和前面兩個API不同的是,需要你告訴緩存架構,他應該在具體的某個時間過期,也就是通過前面的重寫create,update,以及access的方法,擷取具體的過期時間。
在Caffeine中有個scheduleDrainBuffers方法,用來進行我們的過期任務的排程,在我們讀寫之後都會對其進行調用:
首先他會進行加鎖,如果鎖失敗說明有人已經在執行排程了。他會使用預設的線程池ForkJoinPool或者自定義線程池,這裡的drainBuffersTask其實是Caffeine中PerformCleanupTask。
在performCleanUp方法中再次進行加鎖,防止其他線程進行清理操作。然後我們進入到maintenance方法中:
可以看見裡面有挺多方法的,其他方法稍後再讨論,這裡我們重點關注expireEntries(),也就是用來過期的方法:
- 首先擷取目前時間。
- 第二步,進行expireAfterAccess的過期:
這裡根據我們的配置evicts()方法為true,是以會從三個隊列都進行過期淘汰,上面已經說過了這三個隊列都是LRU隊列,是以我們的expireAfterAccessEntries方法,隻需要把各個隊列的頭結點進行判斷是否通路過期然後進行剔除即可。
- 第三步,是expireAfterWrite:
可以看見這裡依賴了一個隊列writeQrderDeque,這個隊列的資料是什麼時候填充的呢?當然也是使用異步,具體方法在我們上面的draninWriteBuffer中,他會将我們之前放進RingBuffer的Task拿出來執行,其中也包括添加writeQrderDeque。過期的政策很簡單,直接循環彈出第一個判斷其是否過期即可。
- 第四步,進行expireVariableEntries過期:
在上面的方法中我們可以看見,是利用時間輪,來進行過期處理的,時間輪是什麼呢?想必熟悉一些定時任務系統對其并不陌生,他是一個高效的處理定時任務的結構,可以簡單的将其看做是一個多元數組。在Caffeine中是一個二層時間輪,也就是二維數組,其一維的資料表示較大的時間次元比如,秒,分,時,天等,其二維的資料表示該時間次元較小的時間次元,比如秒内的某個區間段。當定位到一個TimeWhile[i][j]之後,其資料結構其實是一個連結清單,記錄着我們的Node。在Caffeine利用時間輪記錄我們在某個時間過期的資料,然後去處理。
在Caffeine中的時間輪如上面所示。在我們插入資料的時候,根據我們重寫的方法計算出他應該過期的時間,比如他應該在1536046571142時間過期,上一次處理過期時間是1536046571100,對其相減則得到42ms,然後将其放入時間輪,由于其小于1.07s,是以直接放入1.07s的位置,以及第二層的某個位置(需要經過一定的算法算出),使用尾插法插傳入連結表。
處理過期時間的時候會算出上一次處理的時間和目前處理的時間的內插補點,需要将其這個時間範圍之内的所有時間輪的時間都進行處理,如果某個Node其實沒有過期,那麼就需要将其重新插入進時間輪。
3.3.除舊布新-更新政策
Caffeine提供了refreshAfterWrite()方法來讓我們進行寫後多久更新政策:
上面的代碼我們需要建立一個CacheLodaer來進行重新整理,這裡是同步進行的,可以通過buildAsync方法進行異步建構。在實際業務中這裡可以把我們代碼中的mapper傳入進去,進行資料源的重新整理。
注意這裡的重新整理并不是到期就重新整理,而是對這個資料再次通路之後,才會重新整理。舉個例子:有個key:'咖啡',value:'拿鐵' 的資料,我們設定1s重新整理,我們在添加資料之後,等待1分鐘,按理說下次通路時他會重新整理,擷取新的值,可惜并沒有,通路的時候還是傳回'拿鐵'。但是繼續通路的話就會發現,他已經進行了重新整理了。
我們來看看自動重新整理他是怎麼做的呢?自動重新整理隻存在讀操作之後,也就是我們afterRead()這個方法,其中有個方法叫refreshIfNeeded,他會根據你是同步還是異步然後進行重新整理處理。
3.4 虛虛實實-軟引用和弱引用
在Java中有四種引用類型:強引用(StrongReference)、軟引用(SoftReference)、弱引用(WeakReference)、虛引用(PhantomReference)。
- 強引用:在我們代碼中直接聲明一個對象就是強引用。
- 軟引用:如果一個對象隻具有軟引用,如果記憶體空間足夠,垃圾回收器就不會回收它;如果記憶體空間不足了,就會回收這些對象的記憶體。隻要垃圾回收器沒有回收它,該對象就可以被程式使用。軟引用可以和一個引用隊列(ReferenceQueue)聯合使用,如果軟引用所引用的對象被垃圾回收器回收,Java虛拟機就會把這個軟引用加入到與之關聯的引用隊列中。
- 弱引用:在垃圾回收器線程掃描它所管轄的記憶體區域的過程中,一旦發現了隻具有弱引用的對象,不管目前記憶體空間足夠與否,都會回收它的記憶體。弱引用可以和一個引用隊列(ReferenceQueue)聯合使用,如果弱引用所引用的對象被垃圾回收,Java虛拟機就會把這個弱引用加入到與之關聯的引用隊列中。
- 虛引用:如果一個對象僅持有虛引用,那麼它就和沒有任何引用一樣,在任何時候都可能被垃圾回收器回收。虛引用必須和引用隊列 (ReferenceQueue)聯合使用。當垃圾回收器準備回收一個對象時,如果發現它還有虛引用,就會在回收對象的記憶體之前,把這個虛引用加入到與之 關聯的引用隊列中。
3.4.1弱引用的淘汰政策
在Caffeine中支援弱引用的淘汰政策,其中有兩個api: weakKeys()和weakValues(),用來設定key是弱引用還是value是弱引用。具體原理是在put的時候将key和value用虛引用進行包裝并綁定至引用隊列:
。
具體回收的時候,在我們前面介紹的maintenance方法中,有兩個方法:
//處理key引用的
drainKeyReferences();
//處理value引用
drainValueReferences(); 複制
具體的處理的代碼有:
因為我們的key已經被回收了,然後他會進入引用隊列,通過這個引用隊列,一直彈出到他為空為止。我們能根據這個隊列中的運用擷取到Node,然後對其進行驅逐。
注意:很多同學以為在緩存中内部是存儲的Key-Value的形式,其實存儲的是KeyReference - Node(Node中包含Value)的形式。
3.4.2 軟引用的淘汰政策
在Caffeine中還支援軟引用的淘汰政策,其api是softValues(),軟引用隻支援Value不支援Key。我們可以看見在Value的回收政策中有:
和key引用回收相似,但是要說明的是這裡的引用隊列,有可能是軟引用隊列,也有可能是弱引用隊列。
3.5 知己知彼-打點監控
在Caffeine中提供了一些的打點監控政策,通過recordStats()Api進行開啟,預設是使用Caffeine自帶的,也可以自己進行實作。 在StatsCounter接口中,定義了需要打點的方法目前來說有如下幾個:
- recordHits:記錄緩存命中
- recordMisses:記錄緩存未命中
- recordLoadSuccess:記錄加載成功(指的是CacheLoader加載成功)
- recordLoadFailure:記錄加載失敗
- recordEviction:記錄淘汰資料
通過上面的監聽,我們可以實時監控緩存目前的狀态,以評估緩存的健康程度以及緩存命中率等,友善後續調整參數。
3.6有始有終-淘汰監聽
有很多時候我們需要知道Caffeine中的緩存為什麼被淘汰了呢,進而進行一些優化?這個時候我們就需要一個監聽器,代碼如下所示:
Cache<String, String> cache = Caffeine.newBuilder()
.removalListener(((key, value, cause) -> {
System.out.println(cause);
}))
.build(); 複制
在Caffeine中被淘汰的原因有很多種:
- EXPLICIT: 這個原因是,使用者造成的,通過調用remove方法進而進行删除。
- REPLACED: 更新的時候,其實相當于把老的value給删了。
- COLLECTED: 用于我們的垃圾收集器,也就是我們上面減少的軟引用,弱引用。
- EXPIRED: 過期淘汰。
- SIZE: 大小淘汰,當超過最大的時候就會進行淘汰。
當我們進行淘汰的時候就會進行回調,我們可以列印出日志,對資料淘汰進行實時監控。
4.最後
本文介紹了Caffeine的全部功能原理,其中的知識點涉及到:LFU,LRU,時間輪,Java的四種引用等等。如果你對Caffeine不感興趣也沒有關系,通過這些知識的介紹相信你也收獲了不少。