上期我們一起學習了自然語言進行中的word embedding相關知識,
深度學習算法(第24期)----自然語言處理(NLP)中的Word Embedding
前幾期我們一起學習了RNN的很多相關知識,今天我們一起用這些知識,學習下機器翻譯中的編碼解碼網絡.
這裡我們要做一個英文翻譯成法語的翻譯器,直接先上圖,看一下編碼解碼網絡長什麼樣子,如下:
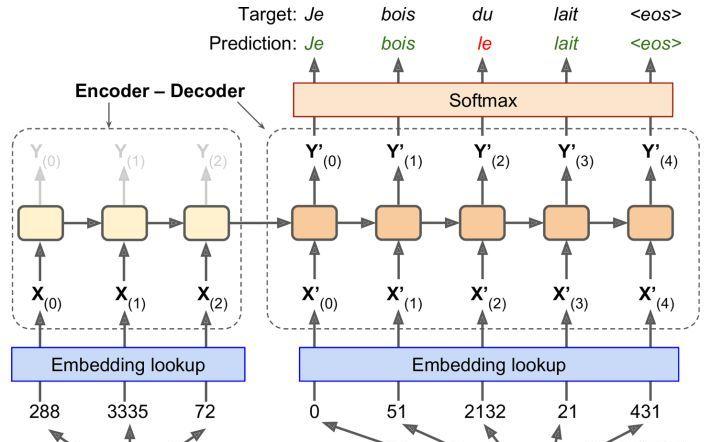
從上圖可以看出,整個網絡包括左邊的編碼器和右邊的解碼器,其中英文語句‘I drink milk’輸入到編碼器中,而解碼器輸出相應的法語翻譯。我們注意到,這裡我們把法語的翻譯結果(标簽)作為輸入也輸入到了解碼器中,也就是說,解碼器的輸入有兩個,一個是标簽,一個是編碼器的輸出結果。對于解碼器第一個單詞,這裡用一個辨別符<go>表示語句的開始,而以辨別符<eos>結束。
需要注意的是這裡的英文句子是被反置輸入進編碼器的。比如語句“I drink milk”是被反置成“milk drink I”輸入到編碼器中的。這確定了英語句子的開頭将會最後送到編碼器,這很有用,因為這通常是解碼器需要翻譯的第一個東西。
每個單詞最初都用一個簡單的整數辨別符來表示(例如:288表示“milk”)。接下來,embedding lookup傳回該詞的embedding(如前所述,這是一個密集的,相當低維的向量)。 這些詞的embedding是實際送到編碼器和解碼器的内容。
在每個步驟中,解碼器輸出輸出詞彙表(即法語)中每個詞的score,然後 Softmax 層将這些得分轉換為機率。 例如,在第一步中,單詞"Je"有 20% 的機率,"Tu"有 1% 的機率,以此類推。 機率最高的詞會輸出。 這非常類似于正常分類任務,是以你可以使用softmax_cross_entropy_with_logits()函數來訓練模型。
需要注意的是,在推斷期間(訓練之後),你不再将目标句子送入解碼器。 相反,隻需向解碼器提供它在上一步輸出的單詞,如下 所示(這裡還需要embedding lookup,它未在圖中顯示)。

well,現在我們知道了大概思路。 但是,如果我們去閱讀 TensorFlow 的序列教程,并檢視rnn/translate/seq2seq_model.py中的代碼(在 TensorFlow 模型中),我們會注意到一些重要的差別:
首先,到目前為止,我們已經假定所有輸入序列(編碼器和解碼器的)具有恒定的長度。但顯然句子長度可能會有所不同。
有以下幾種方法可以處理,例如,使用static_rnn()或dynamic_rnn()函數的sequence_length參數,來指定每個句子的長度(前幾期學過)。然而,教程中使用了另一種方法(大概是出于性能原因):根據長度對句子分組,比如長度為1到6個單詞的分到一組,長度為7到12的分到另一組,等等),并且使用特殊的填充标記(例如"<pad>")來填充較短的句子。例如,"I drink milk"變成"<pad> <pad> <pad> milk drink I",翻譯成"Je bois du lait <eos> <pad>"。當然,我們希望忽略任何<eos>标記之後的輸出。為此,本教程的實作使用target_weights向量。例如,對于目标句子"Je bois du lait <eos> <pad>",權重将設定為[1.0,1.0,1.0,1.0,1.0,0.0](注意權重 0.0 對應目标句子中的填充标記)。簡單地将損失乘以目标權重,将消除對應<eos> 标記之後的單詞的損失。
其次,當輸出詞彙表很大時(就是這裡的情況),輸出每個可能的單詞的機率的過程将會非常慢。如果目标詞彙表包含50,000個法語單詞,則解碼器将輸出 50,000維向量,然後在這樣高次元的向量上計算softmax函數,計算量将非常大。為了避免這種情況,一種解決方案是讓解碼器輸出更小的向量,例如,1,000 維向量,然後使用采樣技術來估計損失,這樣就不必對目标詞彙表中的每個單詞都計算。 這種采樣的Softmax 技術是由Sébastien Jean等人在2015年提出的。在TensorFlow中,你可以使用sampled_softmax_loss()函數。
第三,教程的實作使用了一種注意力機制,讓解碼器能夠監視輸入序列。注意力增強的RNN,這裡不做詳細讨論,但如果你有興趣,可以關注機器翻譯,機器閱讀和圖像說明的相關論文。
最後,本教程的實作使用了tf.nn.legacy_seq2seq子產品,該子產品提供了輕松建構各種編解碼器模型的工具。例如,embedding_rnn_seq2seq()函數會建立一個簡單的編解碼器模型,它會自動為你處理word embedding,就像上面中所示的一樣。
現在我們了解了seq2seq教程的實作所需的全部知識,嘗試去應用并訓練自己的翻譯器吧!
好了,至此,今天我們簡單學習了機器翻譯中編碼解碼器的相關知識,希望有些收獲,下期我們将一起學習下自編碼器的相關知識,歡迎留言或進社群共同交流。