來源 | 微信背景團隊
Wechat & NUS《A Distributed System for Large-scale n-gram Language Models at Tencent》分布式語言模型,支援大型n-gram LM解碼的系統。本文是對原VLDB2019論文的簡要翻譯。
摘要
n-gram語言模型廣泛用于語言處理,例如自動語音識别(ASR)。它可以對從發生器(例如聲學模型)産生的候選單詞序列進行排序。大型n-gram模型通常可以提供良好的排名結果,但這需要大量的記憶體空間。将模型分布到多個節點,可以解決記憶體問題,同時會産生很大的網絡通信開銷并引入了不同的瓶頸。
本文我們将介紹一套分布式系統,它采用新穎的優化技術來降低網絡開銷,包括分布式索引、批處理和緩存,可以減少網絡請求并加速每個節點上的操作。同時還提出了一種級聯容錯機制,可根據故障的嚴重程度自适應地切換到小型n-gram模型。對9種自動語音識别(ASR)資料集的實驗研究證明,我們的分布式系統可以高效、有效、穩健地擴充到大型模型。我們已成功将其部署到騰訊的微信ASR系統中,網絡流量峰值達到每分鐘1億次查詢。
關鍵字
n-gram語言模型,分布式計算,語音識别,微信
1.介紹
語言模型用于估計單詞或标記序列的機率。通常,它們為罕見序列或具有文法錯誤的序列配置設定低機率。例如,通過計算機科學文章訓練的語言模型可能為s1配置設定更高的機率 :“VLDB is a database conference” ,而不是s2:“VLDB eases a data base conference”。語言模型廣泛用于自然語言處理[15],特别是在生成文本的應用中,包括自動語音識别,機器翻譯和資訊檢索。
通常,語言模型可以用于對生成器生成的候選輸出進行排名。例如,在ASR中,生成器是聲學模型,其接受音頻然後輸出候選詞序列。對于來自聲學模型的若幹個類似分數的候選者,例如s1和s2,語言模型對于選擇正确的答案至關重要。
n-gram是一種簡單且非常有效的語言模型。它基于對序列n-gram的統計(例如頻率)來估計單詞序列的機率。n-gram是n個單詞的子序列。
例如,“VLDB”和“database”是1-gram; “VLDB is”和“VLDB eases”是2-gram。n-gram語言模型為頻繁出現的n-gram的序列賦予更高的機率分數。最終機率統計資料是由特定文本語料庫計算出來。統計的機率反映了序列從訓練文本語料庫生成的可能性。對于樣本序列s1和s2,3-gram模型會給s1一個更高的機率,因為“VLDB is a”比“VLDB eases a”更常見,同樣,“a database conference”比“data base conference”在計算機科學文章中更常見。
使用n-gram語言模型的一個重要問題是其存儲成本高。首先為了準确性,n-gram中的n越大越好。例如,1-gram模型會給s2一個比s1更大的分數,因為“data”和“base”比“database”都要出現更頻繁。相比之下,2-gram語言模型可能給s1提供比s2更高的機率,因為“database conference”比“data base conference”更常見。
其次,較大的n-gram集合包括更多的n-gram(會有更好的覆寫),是以對相對不常見的n-gram序列也能給出更好的機率估計。例如,如果n-gram集合中不包含“database conference”,則會基于其字尾即“conference”來估計s1的機率。此過程稱為回退(參見第2.2節),準确度會有所下降。實驗證明,較大的模型确實具有更好的性能。但是,大型模型在單個計算機的記憶體存儲不容易,且快速通路的效率非常低。
通過将統計機率資訊分布到多個節點來處理大型n-gram模型,我們稱為分布式語言模型。實作分布式n-gram模型的一個挑戰是高通信開銷。例如,如果文本語料庫中不包含n-gram,則會産生O(n)的消息查詢(因為需要通過[5]中的“回退”來計算其最終機率)。考慮到每個輸入(句子)可能有多達150,000個候選n-gram [5],通信成本變得非常昂貴。實作分布式n-gram模型的另一個挑戰與網絡故障有關,網絡故障經常發生在具有大量網絡通信的分布式系統中[23]。如果某些n-gram消息丢失,則該模型将産生對機率的不準确計算。
在本文中,我們提出一種高效,有效和健壯的分布式系統技術,可以支援大規模的n-gram語言模型。
首先,我們在本地節點上緩存短n-gram的統計資料(如1-gram和2-gram)。如此可以消除了低階n-gram的通信成本。
其次,我們提出适合n-gram檢索的兩級分布式索引。全局索引将相關n-gram機率的統計資訊分發到遠端同一節點。是以,每次完整n-gram隻發出一次網絡消息就能得到完整資料。本地級索引将統計資訊存儲在字尾樹結構中,這有助于快速搜尋并節省存儲空間。
第三,我們把即将發送到同一伺服器的消息優化為單個消息,顯著降低了通信成本。
最後,我們提出了一種級聯容錯機制。兩級緩存分别為2-gram大模型子集,4/5-gram小模型。前者使用于網絡輕微故障,如偶爾丢包,後者使用于重大網絡故障,如節點故障。
本文貢獻歸納如下:
- 提出了緩存、索引和批處理優化技術,以減少大規模分布式n-gram語言模型的通信開銷和加速機率估計過程。
- 提出了一種級聯容錯機制,該機制适應于網絡故障的嚴重程度。它在兩個局部n-gram模型之間進行切換,給出了健壯的機率估計。
- 實作了一套分布式系統,并以語音識别為應用,對9個資料集進行了廣泛的實驗。該系統擴充為5-gram模型應用。實驗結果證明了較大的n元模型具有較高的計算精度。我們已經将其應用于微信ASR系統,每天有1億條語音,峰值網絡流量為每分鐘1億次查詢。
本文的其餘部分安排如下:第2節介紹了n-gram語言模型;第3節介紹了系統的細節,包括優化技術和容錯機制;第4節對實驗結果進行了分析;第5節回顧了相關工作;第6節總結了論文。
2.相關基礎
在本節中,我們首先簡單介紹如何使用n-gram語言模型估計單詞序列的機率,然後簡要描述下訓練和推理過程。
2.1語言模型
給定m個單詞序列,表示為wm =(w1,w2,...,wm),來自詞彙表V,語言模型提供該序列的機率,表示為P(w1...m)。
根據機率論,聯合機率可以分解如下:

通常,在自然語言處理(NLP)應用中,等式4中的機率與來自序列生成器的得分可以組合,來對候選序列進行排名。例如,ASR系統使用聲學模型來生成候選句子。聲學得分與來自語言模型的得分(等式4)組合,對候選句子進行排名。具有文法錯誤或奇怪單詞序列的那些将從語言模型得到較小的分數,是以被排在較低的位置。
n-gram語言模型假設序列中的單詞僅取決于先前的n-1個單詞。形式上表達為
在公式4中應用假設(公式5,稱為Markov假設[15]),我們得到了
例如,3-gram模型估計4個單詞序列的機率,
(省略examples)
2.2 平滑技術
基于頻率的統計(方程7)有一個問題:當n-gram沒有出現在訓練語料庫中時(例如當訓練語料庫很小時,頻率計數為0),條件機率(公式7)為零,這導緻聯合機率為0(公式6)。平滑是解決這種“零頻率”問題的一種技術。有兩種流行的平滑方法,即回退模型和插值模型。一般的想法是将一些機率品質從頻率高的n-gram轉移一部分到
,頻率低的n-gram,并基于字尾來估計它們的機率。
回退平滑模型:
在方程8中
表示(頻繁)n-gram的折扣機率。例如,一種流行的平滑技術,稱為Kneser-Ney平滑,計算
其中D是超參數。
插值Kneser-Ney平滑
我們應用Kneser-Ney插值平滑,如公式9。通過簡單的操作([6]的第2.8節),插值模型(例如公式9)可以轉換為相同的公式8,是以兩種平滑方法共享相同的推理算法。
在本文的其餘部分,我們使用回退模型(公式8)來介紹推理算法。
2.3 訓練和推理
n-gram語言模型的訓練過程會對訓練文本語料庫中的頻率進行計數,可以得到所有1-gram,2-gram,...,n-gram的所有條件機率(等式4)并計算系數。例如,5-gram模型的統計資料為1-gram至5-gram。
訓練語料庫中隻會出現訓練語料庫中出現的單詞。有兩個原因:
a)對于給定的n和一個單詞n詞彙V,完整的n-gram集,其大小為
當V很大時會消耗大量的記憶體。
b)從未使用過一些x-gram記錄,例如“is be do”,無需預先計算和存儲其統計資訊。在本文中,我們關注推理階段的表現,進而跳過有關教育訓練的細節。
(請注意,對大型文本語料庫(如TB級)的訓練也非常具有挑戰性。與[5]一樣,我們使用分布式架構(即Spark)來加速教育訓練過程。)
推理過程接受由其他子產品(例如ASR系統的聲學模型)生成的n-gram w1...n作為輸入,并傳回P (wn|wn−1)。如果n-gram出現在訓練語料庫中,則其訓練過程中已經計算出條件機率,可以直接檢索;否則,我們使用平滑技術來計算替代的機率(公式8)。
從訓練階段生成的所有機率和系數都儲存在磁盤上,并在推理期間加載到記憶體中。ARPA [27]是n-gram語言模型的通用檔案格式。
2.4 本文問題定義
在本文中,我們假設n-gram語言模型已經離線訓練好。我們的系統将ARPA檔案加載到記憶體中并進行線上推理,将其用于計算由其他子產品生成的單詞序列的機率,例如ASR的聲學模型。我們提出的技術,可以利用大規模n-gram語言模型的進行高效和穩健的推理。
3.分布式系統
較大的n-gram語言模型在機率估計中更準确。然而,當語言模型具有太多太長的n-gram時,例如,一個具有400 GB存儲空間的大型ARPA檔案,我們無法将整個檔案加載到單個節點的主存儲器中。如果我們隻将部分ARPA資訊加載到主記憶體中并将其餘部分(n-gram)放在磁盤上,則推理過程非常緩慢,因為它必須從磁盤中檢索n-gram的統計資訊。
我們采用分布式計算的方式來解決這個問題,将ARPA檔案分割成多個節點。每個節點的記憶體足夠大,可以存儲它的一部分。這樣的節點我們稱為伺服器節點。相應地,對應還有用戶端節點。用戶端節點如下運作:
首先,它使用其他子產品生成單詞序列候選(如ASR的聲學模型);
其次,它向伺服器發送請求消息,從序列中檢索每個n-gram的條件機率;一條n-gram就是一條查詢。如果查詢不存儲在伺服器上,則使用“回退”來估計機率,如算法1所示。
最後,用戶端将機率與公式6結合起來。這個過程叫做解碼,這在3.3節中進行了闡述。
在本節中,我們首先介紹我們減少通信開銷的優化技術,包括緩存,分布式索引和批處理。在此之後,再描述了針對通信故障的級聯容錯機制。我們的系統表示為DLM,是分布式語言模型的縮寫。
3.1 緩存
緩存廣泛應用于資料庫系統優化。在DLM中,我們緩存短n-gram的機率資料,具體來說,1-gram和2-gram被緩存在用戶端節點上。如果緩存長n-gram,例如3-gram,将進一步降低網絡成本。但是,它也會産生大量的記憶體成本。第4.2.2節詳細比較了存儲成本和通信減少。通過緩存這些資料,我們不僅可以降低通信成本,還可以改善系統的其他部分。我們實作以下三個目标:
- 減少網絡查詢的數量。例如對于2gram和1-gram查詢,使用本地緩存統計資訊估計條件機率。是以,無需向遠端伺服器發送消息。
- 在算法2(第3.2.1節)中支援超過2-gram的記錄,這使得伺服器上的資料更加平衡。
- 支援容災機制,将在3.4節中讨論。
3.2 分布式索引
DLM中的分布式索引由兩個級别組成,即用戶端節點上的全局索引和伺服器節點上的本地索引。
3.2.1 全局索引
通過用戶端節點上的本地緩存,用戶端可以估計本地1-gram和2-gram查詢的機率。對于長n-gram查詢,用戶端使用全局索引來定位存儲計算P(wn | wn-1)的統計資訊的伺服器(根據算法1),然後向這些伺服器發送消息。如果我們可以将所有必需的統計資訊放在同一台伺服器上,則隻會向伺服器發送一條消息。建構全局索引(算法2)可以實作該目标。
有兩個參數,即來自ARPA檔案的n-gram總集合A和伺服器B的數量。
對于每個1-gram和2-gram,我們在所有節點都放置其正向機率和回退機率(第3行)。
對于其他n-gram(n≥3),我們基于wn-2 和 wn-1的hash做key,分發正向機率(第5-6行)。基于wn-1和wn(線7-8)的hash做key,分發回退機率。第5行和第7行共享相同的hash函數。
在推理過程中,如果n≤2,我們在本地用戶端進行查詢而不發送任何消息;否則,我們隻需将P(wn | wn-1)的請求消息發送到具有ID Hash(wn-2,wn-1)%B + 1的伺服器。運作算法1以使用等式10和14之間的等式之一來獲得機率。全局索引保證對于任何n-gram w1..n(n> 2),可以從同一伺服器通路算法1中使用的所有資料。(例如,假設 w=“a database”。
根據算法2,以w(第7行和第8行)結尾的所有ngram的回退機率(例如,“is a database”)與所有子gram的正向條件機率都放在同一伺服器上(例如,“is a database conference“),其第三個和第二個字是w(第5行和第6行)。另外,公式13(相應的公式14)使用的P(wn | wn-1)和γ(wnn-21)(P(wn)和γ(wn-1))在所有的節點上都有(第3行)。
總之,公式10和14中使用的所有統計資料都可以從同一伺服器獲得。是以,算法1的任何一個完整的n-gram都可以減少至隻有一次網絡查詢。)
如果我們隻緩存1-gram,負載均衡算法1也能工作。然而,緩存1-gram和2-gram的結果可以獲得更好的負載平衡。我們解釋如下。考慮到某些單詞非常流行,如“is”和“the”,基于單個單詞的散列配置設定n-gram可能會導緻伺服器節點之間的負載不平衡。
例如,存儲以'the'結尾的n-gram的伺服器将具有更大的分片并從用戶端接收更多消息。由于2-gram的分布比1-gram(即單詞)的分布更均衡,是以在算法1中基于兩個單詞(wn-1+wn或wn-2+wn-1)分布n-gram将使查詢更加均勻。事實上,我們不建議使用3-gram以上,以使分布更加平衡。這樣需要在本地用戶端節點上緩存3-gram并在每個伺服器節點上備份3-gram資訊,這會顯着增加存儲成本。
3.2.2 本地索引
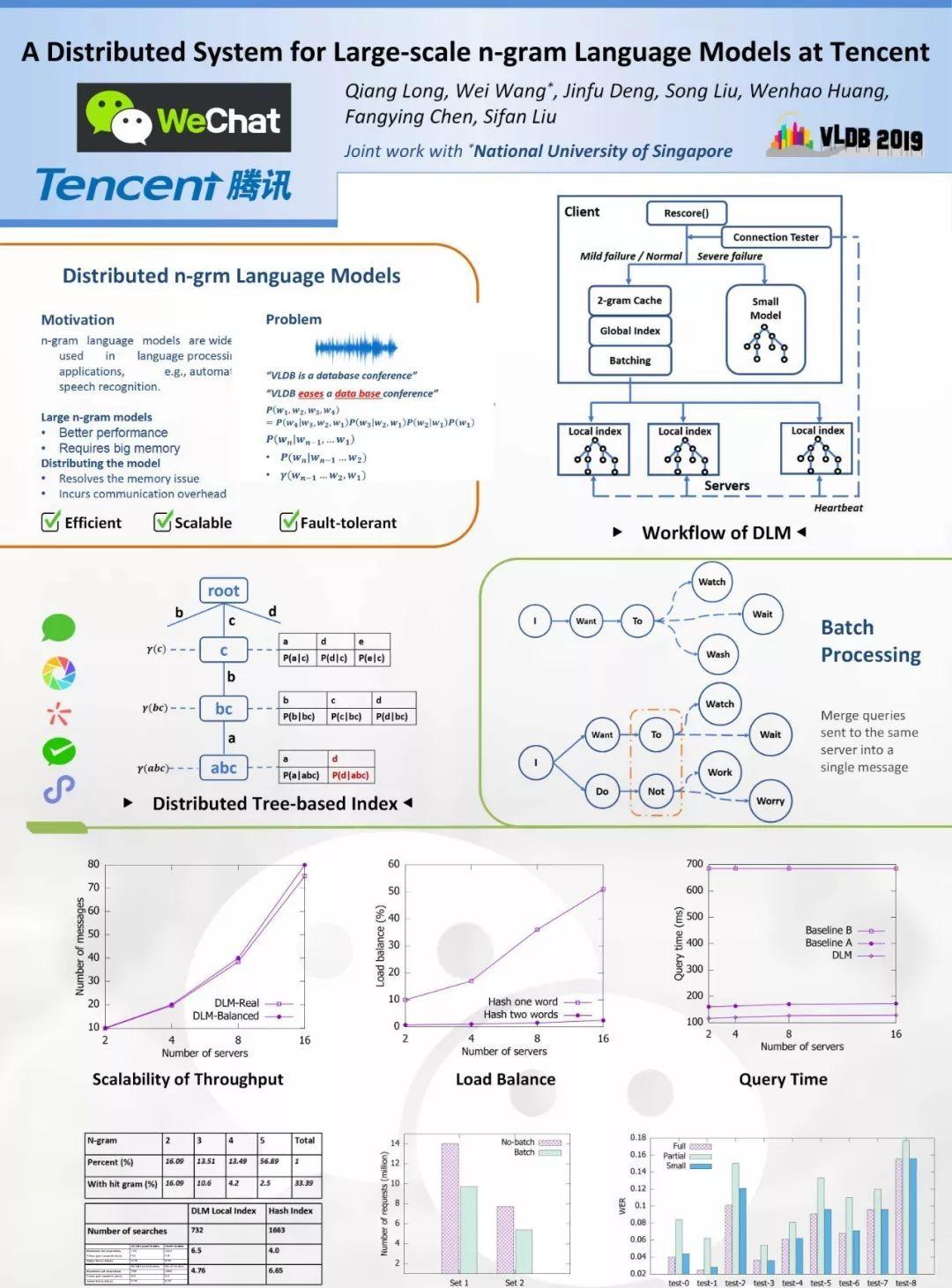
伺服器節點從用戶端接收到n-gram查詢請求,它就會搜尋本地索引來得到統計資訊并将它們組合最終計算P(wn | wn-1)。伺服器上需要建構本地索引,以便有效地檢索機率資訊。我們使用字尾樹作為索引結構,其中每個邊表示來自語音的一個或多個單詞,每個節點通過連接配接邊表示一系列單詞。如圖1所示。
本地索引的建構算法如算法3。每個伺服器都有兩組從算法2生成的統計資料,即表示為G = {<w1n,γ(w1n)>}的回退權重和表示為P = {<w1n的機率, P¯(wn | wn-1>}。對于P中的每一對,如果它是1-gram,我們隻需将它存儲在字典U(第8行)中;否則,我們沿着路徑wn-周遊樹。1,wn-2,...,w1。如果我們在完成路徑之前到達葉節點,則建立剩餘單詞的新邊和節點。傳回最後一個被通路節點(第5行)。使用wn作為鍵(第6行)将機率插入到排序數組中,進而啟用二分搜尋。
對于每一對參數中的g,我們沿着完整n-gram的反向序列路徑wn,wn-1,...,w1(第7行)來周遊樹結構。周遊期間插入新節點。γ(w1n)被配置設定給回退的節點(第8行)。注意,每個節點可能具有多個關聯機率;但是,它隻能有一個回退權重。這是因為共享相同字首(即wn-1)的所有n-gram文法的機率被插入到同一節點中;而回退權重與對應于完整n-gram的節點相關聯,且n-gram是唯一的。圖1給出了将4-gram插入索引的一個例子。這個4-gram的條件機率位于右下角。
在推理期間,我們運作算法4來估計條件機率。它針對字尾樹3實作算法1.算法4周遊(wn-1,...,w2,w1)(第2行)。當下一個單詞沒有邊緣或達到w1時,它會停止。傳回的路徑是一組通路過的節點。根節點位于底部,最後一個通路節點位于頂部。然後它逐個彈出節點。所有類型的n-gram都是通過使用公式10和14之間的公式之一來計算機率 。
3.3 Batch 處理
通常,生成器為每個輸出位置生成多個候選詞。是以,有許多待篩選的句子。當語言模型在生成新的候選者之後立即對新候選詞進行排名,它被稱為on-the-fly rescoring ;當語言模型被用于在完成所有位置之後對候選句子進行排名時,它被稱為multi-pass rescoring。與multi-pass rescoring相比,on-the-fly resocring會産生較小的存儲成本,并且通過過濾低分數的單詞來維持一小組候選句子,是以效率更高。在DLM中,我們采用on-the-fly recoring。
目前候選句子的尾部,可能産生新的若幹個新候選詞。為了得到每個新候選詞的聯合機率,我們需要得到最後一個n-gram的正向條件機率(其它詞已經計算了n-gram的機率)。一開始,候選句子很短,隻有一個單詞“START”代表一個句子的開頭。是以,第一組查詢n-gram是2-gram,如“START I”。随着句子變得更長,查詢n-gram變得更長,例如5-gram。如果我們保持最多K個候選參數并為每個位置生成W個單詞,那麼我們需要查詢KW n-gram,即KW個消息。這個數字可能非常大,如10,000,這會導緻非常多的網絡查詢。為了降低通信消耗,我們嘗試将發送到同一伺服器的消息批量處理為單個消息。
如果兩個n-gram共享相同的字首,根據算法4(和公式10-14),它們可能在本地索引上共享類似的通路模式,以便統計計算條件機率。假設我們使用4-gram模型對圖2中的候選詞進行排名,即“watch”,“wait”和“wash”。即使使用分布式索引,我們也需要為3個4-gram中的每一個提供一條消息。
由于它們共享相同的字首“I Want To”,是以根據算法2的第5行将這三條消息發送到同一伺服器。将這三條消息合并為一條消息。一旦伺服器節點收到消息,算法4就沿着公共字首“I Want To”的反向周遊,然後周遊傳回以分别獲得3個n-gram的統計資料。結果将放入單個消息中并發送回用戶端。對于此示例,我們将消息數量減少至原來的1/3。換句話說,可以節省2/3的成本。
對于不共享相同字首的n-gram,隻要将它們目的地是同一伺服器,我們仍然可以合并它們的請求消息。假設“Want To”和“Do Not”具有相同的散列值,則在圖3中,根據算法1的第5行,可以将所有4-gram的消息合并(批處理)為單個消息。在伺服器端,共享相同字首的n-gram由算法4一起處理。兩種批處理方法是正交的,是以可以組合在一起。
3.4 容錯(容災)
容錯對于分布式系統至關重要。根據網絡故障的嚴重程度,我們提供級聯容錯機制。圖4顯示了我們系統的架構。連接配接測試程式不斷向伺服器發送心跳。當故障率很高時,例如,超過0.1%的消息逾時或網絡延遲加倍,我們将所有查詢重定向到本地小語言模型。
在我們的實驗中,我們使用一個50 GB統計的小型(5-gram)模型,通過基于熵的裁剪從完整的模型中裁剪得到[25]。當故障率處于非常低的水準,我們正常去遠端查詢大模型機率,如果查詢失敗,我們将使用本地2-gram子集模型的分數。(注意,這個子集模型和50G小模型是不一樣的,兩者獨立分開訓練)。是以,我們不能混合他們的統計資料來估計句子機率(方程6)。
4.0 實驗
在本節中,我們将基于多個資料集的來評估ASR的DLM技術。結果表明,我們的分布式語言模型DLM,可以有效地擴充到大型模型(例如,具有400 GB ARPA),并且通信開銷很小。具體來說,當輸入音頻增加一秒時,DLM的開銷僅增加0.1秒,這對于微信中的實時系統來說足夠小。
4.1實驗設定
4.1.1 硬體
我們通過每個節點上具有Intel(R)Xeon(R)CPU E5-2670 V3(2.30GHz)和128 Giga Bytes(GB)記憶體的叢集進行實驗。節點通過10 Gbps網卡連接配接。我們使用開源消息傳遞庫(Github:phxrpc)
4.1.2 資料
我們收集一個大的文本語料庫(3.2TB)來訓練使用插值Kneser-Ney平滑的5-gram語言模型。經過訓練,我們得到一個500 GB的ARPA檔案,進一步修剪,生成50GB,100GB,200GB和400GB的實驗模型。如果沒有明确的描述,則實驗将在200GB模型上進行,該模型是目前部署的模型。為了評估語言模型的性能,我們使用ASR作為我們的應用程式。收集9個資料集作為測試資料。我們将這9個資料集命名為test-1到test-9,詳細資訊如表1所示。我們可以看到測試資料是在不同的環境下記錄的,并且在長度方面有所不同。mix 表示音頻具有閱讀和自發語音。noise 意味着音頻被記錄在實際應用場景的公共場所。
4.1.3評估名額
我們評估DLM在支援ASR方面的有效性,效率和存儲成本。為了有效性,我們使用單詞錯誤率(WER),這是ASR的常用度量。為了計算WER,我們從測試資料集中手動生成每個音軌的參考單詞序列(即标準答案)。給定輸入音軌,我們将模型生成的單詞序列與參考單詞序列對齊,然後應用公式15計算WER。
在公式15中,D; S和I是删除,替換和插入操作的數量,分别涉及在Levenshtein距離之後對齊兩個序列.N是參考序列中的詞的總數。例如,轉換圖5中的預測詞序列對于參考序列,我們需要D = 1删除操作,S = 2替換操作,I = 1插入操作。相應的WER是(1 + 2 + 1)/5 = 0.8
為了提高效率,我們測量每秒語言模型輸入音頻所花費的平均處理時間。分布式n-gram模型會産生通信開銷。我們還測量網絡消息的數量,這是通信開銷的主要原因。
4.2可伸縮性和效率評價
我們首先研究DLM的整體效率和可擴充性。之後,我們對每種優化技術的性能進行細分分析。
4.2.1可擴充性測試
我們根據吞吐量測試DLM的可擴充性,即每秒伺服器處理的消息數量。我們使用具有400GB資料的大型模型,并測量DLM處理的每分鐘消息數。通過控制從用戶端到伺服器的消息速率,所有伺服器上的最大CPU使用率保持在75%。
我們運作兩組工作負載:a)實際工作負載,表示為DLM-Real,其消息由解碼器生成,無需任何調節; b)平衡工作負載,表示為DLM-Balanced,其消息在DLM的所有伺服器之間手動平衡。對于DLM-Real,向伺服器分發消息是不平衡的。是以,一些伺服器将接收更少的消息,并且整體吞吐量受到影響。圖6中的結果顯示DLM-Balanced和DLM-Real很好擴充,差異很小。良好的可擴充性是得益于本文提出的技術,将在以下小節中詳細分析。
可擴充的系統應該最小化伺服器增多時産生的開銷。在圖7中,我們通過在伺服器數量增加時查詢時間和每秒音頻生成的消息數量的變化來衡量開銷。我們将DLM與兩種基線方法進行比較,表示為基線A [5]和基線B [20]。
基線A基于每個n-gram的最後兩個字的散列來配置設定回退權重和機率。文中簡要提到了批處理,省略了細節。我們對基線A使用相同的DLM批量處理方法。基線B根據n-gram中所有單詞的散列配置設定機率和回退權重;另外,它在本地緩存短的ngram。我們遵循與DLM相同的緩存機制實作Baseline B,即緩存1-gram和2-gram。
DLM和基線的每秒輸入音頻的處理時間如圖7a所示。我們可以看到,當伺服器數量增加時,DLM和Baseline A在查詢時間方面的開銷(或變化)很小。基線B的查詢時間仍然很長,并且對于不同數量的伺服器幾乎相同。這可以通過從用戶端到伺服器每秒音頻的消息數來解釋(圖7b)。注意,圖7b的y軸與圖6中的y軸不同,圖6表示伺服器每秒處理的消息。算法A和DLM比算法B産生的消息少,主要是因為批量處理。對于Baseline A和DLM,當伺服器數量增加時,發送到同一伺服器的兩條消息的機會減少。
是以,消息數量和處理時間增加。此外,DLM的分布式索引保證一個n-gram的所有統計資訊都在一台伺服器上。基線A它隻能保證在n-gram的回退過程中使用的所有機率被配置設定到同一伺服器(因為等式8中的字尾gram共享相同的最後兩個字),而回退權重可以被分發到不同的伺服器。是以,DLM生成的消息比算法A少。
為了了解時間的消耗,我們在表2中測量單個網絡通信的每個階段所花費的時間。我們可以看到,使用優化的本地索引,大部分時間花在消息傳輸,編碼和解碼上,這需要優化消息傳遞庫。在本文中,我們專注于減少消息的數量。接下來,我們研究了我們提出的優化技術在通信減少方面的有效性。
4.2.2 Caching
DLM在用戶端緩存2-gram和1-gram。是以,1-gram和2-gram查詢在本地回答,而不向伺服器節點發送消息。從表3中,我們可以看到可以直接發出16.09%的2-gram查詢。是以,我們通過在本地緩存2-gram查詢來減少16.09%的消息(不考慮批處理)。隻有一個1-gram的查詢,即“START”,它對性能沒有影響。
我們不會緩存3-gram和4-gram,因為它們非常大,如表4所示。此外,隻有一小部分3-gram和4-gram查詢可以直接回答而無需回退。其餘的3-gram和4-gram查詢必須由遠端伺服器計算。換句話說,緩存3-gram和4-gram會降低通信成本。5-gram的大小并不大,因為訓練算法修剪了許多5-gram,可以使用4-gram或3-gram精确估算,以節省存儲空間。我們不緩存5-gram,因為隻有2.5%的5-gram查詢(表3)可以使用ARPA檔案中的5-gram來應答;其他5-gram查詢需要回退,這會導緻網絡通信。
4.2.3 分布式索引
我們進行了一項消融實驗,以分别評估全局和本地 DLM 索引(第3.2節)的表現。我們不考慮此實驗的批處理和緩存優化。DLM的全局索引将用于估計n-gram機率的所有資料放在同一伺服器節點中,進而将消息數量減少到每個n-gram 1次。為了評估這種減少的效果,我們在表3中列出了查詢分布。隻有一個1-gram查詢,即“START”。是以,我們不會在表格中列出它。
我們可以看到所有查詢中有33.39%已命中。換句話說,這些33.39%的查詢不需要回退,每個查詢隻會産生一條消息。其餘查詢至少需要一次回退,這至少會再産生一次消息。使用全局索引,我們始終為每個查詢發出一條消息,這至少可以節省(1-33.39%)= 66.61%的成本。
全局索引将ARPA檔案中的資料分區到多個伺服器上。我們評估伺服器之間的負載平衡。負載平衡如下計算:
其中S表示所有伺服器節點上的本地索引大小集,max(avg)計算最大(相應的平均值)索引大小。圖8通過對單個單詞和兩個單詞進行散列來比較全局索引的負載平衡。我們可以看到,當對兩個單詞進行散列時,伺服器之間的資料分布更加平衡。
為了評估DLM的本地索引(即字尾樹)的性能,我們建立了一個n-gram查詢集,并使用我們的本地索引與使用存儲條件機率和回退權重的基線索引來比較搜尋時間。兩個單獨的Hash函數都以整個n-gram為關鍵字。表5顯示DLM的本地索引比哈希索引快得多(參見總時間)。這主要是因為本地索引通過減少搜尋次數來節省時間。具體而言,平均而言,每個n-gram需要2.27倍的回退才能達到獲得最終資料。DLM每n-gram搜尋一次本地索引(字尾樹),然後周遊以擷取回退過程所需的所有資訊。
相反,基線方法在回退過程(算法1)期間重複調用哈希索引以獲得回退權重和機率。盡管每次搜尋的哈希索引的速度很快,但總體效率差距主要取決于搜尋次數的巨大差異。請注意,表5中每次搜尋的時間小于表2中的時間。這是因為在表2中,我們測量每條消息的時間,其中包括一批n-gram。這些n-gram中的一些可以共享相同的字首(參見第3.3節),是以一起處理。是以,搜尋時間更長。表5中的時間僅适用于單個n-gram。
本地索引還能節省存儲,因為字尾樹僅在共享該字首的所有n-gram中存儲字首一次。圖6比較了ARPA檔案,DLM(即本地索引)和另一種用于存儲語言模型的流行資料結構(即WFST [22])的存儲成本。我們可以看到DLM節省了近一半的空間。
4.2.4 batch處理
3.3節中提出的批處理将發送到同一伺服器的消息合并為單個消息,以減少開銷。圖9比較了DLM與批處理和沒有批處理的DLM兩組n-gram查詢。y軸是每個查詢集的消息總數。我們可以看到批處理顯着減少了網絡消息的數量。實際上,幾乎一半的消息都被消除了。是以,它節省了很多時間。圖7中DLM和Baseline B之間的巨大差距也主要是由于批處理。
4.3 容錯(容災)評估
我們的分布式系統具有兩個用于容錯的備用模型,這有助于使系統對網絡故障具有魯棒性。但是,由于我們使用的是部分或小型語言模型,是以識别性能可能會降低。為了比較這些模型的準确性,我們獨立地在9個測試資料集上運作每個模型。圖10顯示了小模型,部分和完整模型的WER。完整模型的ARPA檔案具有200 GB資料。部分模型包括完整模型的所有1-gram和2-gram。小模型是在文本語料庫的子集上訓練的5-gram語言模型。ARPA檔案大小為50 GB。
我們可以看到完整模型具有最小的WER,這證明了我們的假設,即較大的模型具有更好的性能。此外,小模型優于部分模型,并且在某些測試資料集上與完整模型可以競争。這是因為小型模型通過複雜的修剪政策從完整模型中修剪[25],而部分模型隻需通過移除3-gram,4-gram和5-gram得到。
請注意,輕度網絡故障時調用部分模型,這對運作時的整體WER影響非常有限。盡管小型模型在多個測試資料集(環境)上具有與完整模型類似的性能,但仍然值得使用完整模型,因為完整模型在不同環境中更加健壯,包括具有多個揚聲器的嘈雜環境,這對于商業部署非常重要。
總結
n-gram語言模型在NLP應用非常廣泛。分布式計算使我們能夠以更高的準确度運作更大的n-gram語言模型。由于通信成本和網絡故障,使系統可擴充是一項挑戰。面對挑戰,我們提出了一個分布式系統來支援大規模的n-gram語言模型。為了減少通信開銷,我們提出了三種優化技術。
首先,我們在用戶端節點上緩存低階n-gram以在本地提供一些請求。其次,我們提出了一個分布式索引來處理其餘的請求。索引将每個n-gram查詢所需的統計資訊配置設定到同一伺服器節點上,這将每n-gram的消息數量減少到隻有一個。此外,它在每個伺服器上建構字尾樹索引,以便快速檢索和估計機率。第三,我們将發送到同一伺服器節點的所有消息批量處理為單個消息。除了效率優化之外,我們還提出了一種級聯容錯機制,它可以自适應地切換到本地小語言模型。實驗結果證明,我們的系統可以高效,有效,穩健地擴充到大型n-gram模型。
參考文獻
[1] C. Allauzen, M. Riley, and B. Roark. Distributed representation and estimation of wfst-based n-gram models. In Proceedings of the ACL Workshop on Statistical NLP and Weighted Automata (StatFSM), pages 32-41, 2016.
[2] D. Amodei, R. Anubhai, E. Battenberg, C. Case,J. Casper, B. Catanzaro, J. Chen, M. Chrzanowski,A. Coates, G. Diamos,E. Elsen, J. Engel, L. Fan,C. Fougner, T. Han, A. Y. Hannun, B. Jun, P. LeGresley, L. Lin, S. Narang, A. Y. Ng, S. Ozair, R. Prenger, J. Raiman, S. Satheesh, D. Seetapun,S. Sengupta, Y. Wang, Z. Wang, C. Wang, B. Xiao,D. Yogatama, J.Zhan, and Z. Zhu. Deep speech 2:End-to-end speech recognition in english and mandarin. CoRR, abs/1512.02595, 2015.
[3] P. Bailis, E. Gan, S. Madden, D. Narayanan, K. Rong, and S. Suri. Macrobase: Prioritizing attention in fast data. In SIGMOD, pages 541-556, 2017.
[4] Y. Bengio, R. Ducharme, P. Vincent, and C. Janvin. A neural probabilistic language model. J. Mach. Learn. Res., 3:1137-1155, Mar. 2003.
[5] T. Brants, A. C. Popat, P. Xu, F. J. Och, and J. Dean. Large language models in machine translation. In EMNLP-CoNLL, pages 858-867, Prague, Czech Republic, June 2007.
[6] S. F. Chen and J. Goodman. An empirical study of smoothing techniques for language modeling. Computer Speech & Language, 13(4):359-394, 1999.
[7] D. Crankshaw, X. Wang, G. Zhou, M. J. Franklin, J. E. Gonzalez, and I. Stoica. Clipper: A low-latency online prediction serving system. In NSDI, pages 613-627, Boston, MA, 2017. USENIX Association.
[8] A. Emami, K. Papineni, and J. Sorensen. Large-scale distributed language modeling. In ICASSP, volume 4, pages IV-37-V-40, April 2007.
[9] A. Graves and N. Jaitly. Towards end-to-end speech recognition with recurrent neural networks. In ICML - Volume 32, ICML'14, pages II-1764-II-1772. JMLR.org, 2014.
[10] A. Graves, A. Mohamed, and G. E. Hinton. Speech recognition with deep recurrent neural networks. CoRR, abs/1303.5778, 2013.
[11] G. Hinton, L. Deng, D. Yu, G. E. Dahl, A. r. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. N. Sainath, and B. Kingsbury. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Processing Magazine, 29(6):82-97, Nov 2012.
[12] S. Ji, S. V. N. Vishwanathan, N. Satish, M. J. Anderson, and P. Dubey. Blackout: Speeding up recurrent neural network language models with very large vocabularies. CoRR, abs/1511.06909, 2015.
[13] J. Jiang, F. Fu, T. Yang, and B. Cui. Sketchml: Accelerating distributed machine learning with data sketches. In SIGMOD, SIGMOD '18, pages 1269-1284, New York, NY, USA, 2018. ACM.
[14] R. Jozefowicz, O. Vinyals, M. Schuster, N. Shazeer, and Y. Wu. Exploring the limits of language modeling. CoRR, abs/1602.02410, 2016.
[15] D. Jurafsky and J. H. Martin. Speech and Language Processing (2nd Edition). Prentice-Hall, Inc., Upper Saddle River, NJ, USA, 2009.
[16] D. Kang, J. Emmons, F. Abuzaid, P. Bailis, and M. Zaharia. Noscope: Optimizing neural network queries over video at scale. PVLDB, 10(11):1586-1597, 2017.
[17] R. Kneser and H. Ney. Improved backing-o for m-gram language modeling. In ICASSP, volume 1,pages 181-184 vol.1, May 1995.
[18] Y. Lu, A. Chowdhery, S. Kandula, and S. Chaudhuri. Accelerating machine learning inference with probabilistic predicates. In SIGMOD, SIGMOD '18, pages 1493-1508, New York, NY, USA, 2018. ACM.
[19] A. L. Maas, A. Y. Hannun, D. Jurafsky, and A. Y. Ng. First-pass large vocabulary continuous speech recognition using bi directional recurrent dnns. CoRR, abs/1408.2873, 2014.
[20] C. Mandery. Distributed n-gram language models : Application of large models to automatic speech recognition. 2011.
[21] T. Mikolov, S. Kombrink, L. Burget, J. Cernocky, and S. Khudanpur. Extensions of recurrent neural network language model. pages 5528 - 5531, 06 2011.
[22] M. Mohri, F. Pereira, and M. Riley. Weighted nite-state transducers in speech recognition. Comput. Speech Lang., 16(1):69-88, Jan. 2002.
[23] Y. Shen, G. Chen, H. V. Jagadish, W. Lu, B. C. Ooi, and B. M. Tudor. Fast failure recovery in distributed graph processing systems. PVLDB, 8(4):437-448, 2014.
[24] D. Shi. A study on neural network language modeling. CoRR, abs/1708.07252, 2017.
[25] A. Stolcke. Entropy-based pruning of backo language models. CoRR, cs.CL/0006025, 2000.
[26] W. Williams, N. Prasad, D. Mrva, T. Ash, and T. Robinson. Scaling recurrent neural network language models. In ICASSP, pages 5391-5395, April 2015.
[27] S. Young, G. Evermann, M. Gales, T. Hain, D. Kershaw, X. Liu, G. Moore, J. Odell, D. Ollason, D. Povey, V. Valtchev, and P. Woodland. The HTK book. 01 2002.
[28] Y. Zhang, A. S. Hildebrand, and S. Vogel. Distributed language modeling for n-best list re-ranking. In EMNLP, EMNLP '06, pages 216-223, Stroudsburg, PA, USA, 2006.
PS:本文首先用微信翻譯引擎完成了全文的翻譯,然後再由人工對部分影響閱讀的句子做了修改。