版權聲明:本文為部落客原創文章,遵循 CC 4.0 BY-SA 版權協定,轉載請附上原文出處連結和本聲明。
本文連結:https://blog.csdn.net/github_39655029/article/details/84869448
基于HMM(隐馬爾可夫模型)的分詞方法
基本部分
-
狀态值序列
B:Begin;
M:Middle;
E:End;
S:Single;
-
觀察值序列
待切分的詞;
-
初始化機率
BMES這四種狀态在第一個字的機率分布情況;
-
狀态轉移矩陣
HMM中,假設目前狀态隻與上一狀态相關,則此關系可用轉移矩陣表示;
-
條件機率矩陣
HMM中,觀察值隻取決與目前狀态值(假設條件),條件機率矩陣主要模組化在BMES下各個詞的不同機率,和初始化機率、狀态轉移矩陣一樣,需要在語料中計算得到對應的資料;
機率分詞模型:CRF(條件随機場)
HMM描述的是已知量和未知量的一個聯合機率分布,屬于generative model,而CRF則是模組化條件機率,屬于discriminative model;且CRF特征更加豐富,可通過自定義特征函數來增加特征資訊,CRF能模組化的資訊應該包括HMM的狀态轉移、資料初始化的特征;主要包括兩部分特征:
-
簡單特征
隻涉及目前狀态特征;
-
轉移特征
涉及兩種狀态間的特征;、
基于深度學習的分詞
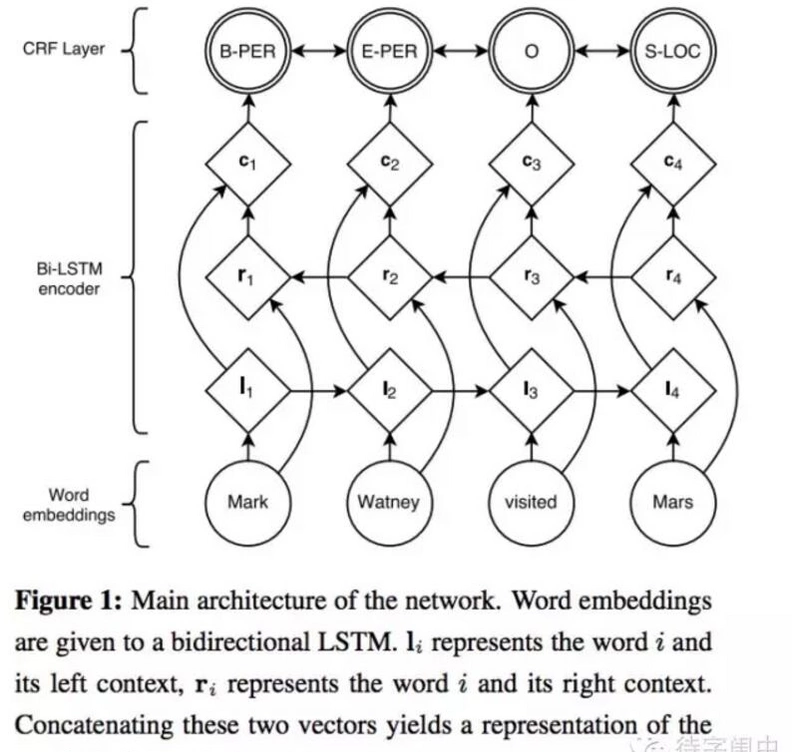
基本步驟:
- 首先,訓練字向量,使用word2vec對語料的字訓練50維的向量;
- 然後,接入一個bi-LSTM,用于模組化整個句子本身的語義資訊;
- 最後,接入一個CFR完成序列标注;
詞向量
one-hot編碼
每個詞隻在對應的index置1,其他位置均為0,難點在于做相似度計算;
LSA(矩陣分解方法)
LSA使用詞-文檔矩陣,矩陣常為系數矩陣,行代表詞語,列代表文檔;詞-文檔矩陣表示中的值表示詞在文章中出現的次數;難點在于當語料庫過大時,計算很耗費資源,且對未登入詞或新文檔不友好;
Word2Vec

結構
包括CBOW和Skip-gram模型;CBOW的輸入為上下文的表示,然後對目标詞進行預測;Skip-gram每次從目标詞w的上下文c中選擇一個詞,将其詞向量作為模型輸入;
Skip-gram主要結構:
- 輸入one-hot編碼;
- 隐藏層大小為次次元大小;
- 對常見詞或詞組,常将其作為當個word處理;
- 對高頻詞進行抽樣減少訓練樣本數目;
- 對優化目标采用negative sampling,每個樣本訓練時隻更新部分網絡權重;
詞性标注
- 基于最大熵的詞性标注;
- 基于統計最大機率輸出詞性;
- 基于HMM詞性标注;
- 基于CRF的詞性标注;