版權聲明:本文為部落客原創文章,遵循 CC 4.0 BY-SA 版權協定,轉載請附上原文出處連結和本聲明。
本文連結:https://blog.csdn.net/github_39655029/article/details/82893018
什麼是NLTK
NLTK
,全稱
Natural Language Toolkit
,自然語言處理工具包,是NLP研究領域常用的一個
Python
庫,由賓夕法尼亞大學的
Steven Bird
和
Edward Loper
在
Python
的基礎上開發的一個子產品,至今已有超過十萬行的代碼。這是一個開源項目,包含資料集、
Python
子產品、教程等;
怎樣安裝
詳情可以參見我的另一篇部落格NLP的開發環境搭建,通過這篇部落格,你将學會
Python
環境的安裝以及
NLTK
子產品的下載下傳;
常見子產品及用途
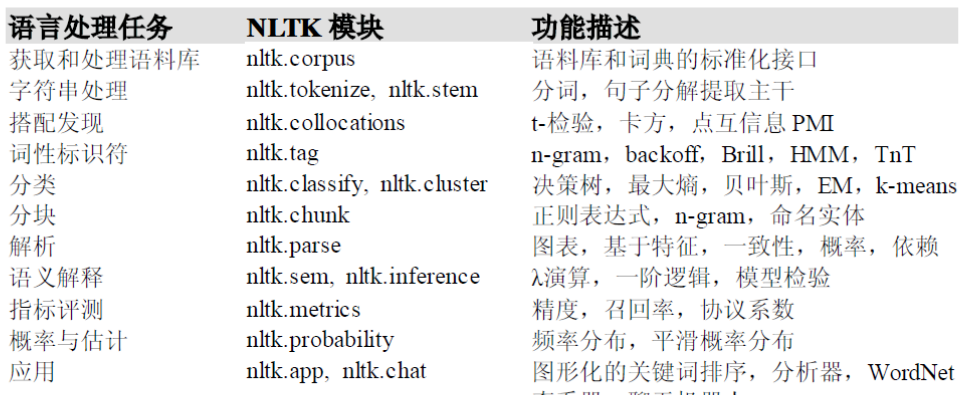
NLTK能幹啥?
- 搜尋文本
- 單詞搜尋:
- 相似詞搜尋;
- 相似關鍵詞識别;
- 詞彙分布圖;
- 生成文本;
- 計數詞彙

#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018-9-28 22:21
# @Author : Manu
# @Site :
# @File : python_base.py
# @Software: PyCharm
from __future__ import division
import nltk
import matplotlib
from nltk.book import *
from nltk.util import bigrams
# 單詞搜尋
print('單詞搜尋')
text1.concordance('boy')
text2.concordance('friends')
# 相似詞搜尋
print('相似詞搜尋')
text3.similar('time')
#共同上下文搜尋
print('共同上下文搜尋')
text2.common_contexts(['monstrous','very'])
# 詞彙分布表
print('詞彙分布表')
text4.dispersion_plot(['citizens', 'American', 'freedom', 'duties'])
# 詞彙計數
print('詞彙計數')
print(len(text5))
sorted(set(text5))
print(len(set(text5)))
# 重複詞密度
print('重複詞密度')
print(len(text8) / len(set(text8)))
# 關鍵詞密度
print('關鍵詞密度')
print(text9.count('girl'))
print(text9.count('girl') * 100 / len(text9))
# 頻率分布
fdist = FreqDist(text1)
vocabulary = fdist.keys()
for i in vocabulary:
print(i)
# 高頻前20
fdist.plot(20, cumulative = True)
# 低頻詞
print('低頻詞:')
print(fdist.hapaxes())
# 詞語搭配
print('詞語搭配')
words = list(bigrams(['louder', 'words', 'speak']))
print(words) 複制
NLTK設計目标
- 簡易性;
- 一緻性;
- 可擴充性;
- 子產品化;
NLTK中的語料庫
- 古騰堡語料庫:
gutenberg
- 網絡聊天語料庫:
webtext
nps_chat
- 布朗語料庫:
brown
- 路透社語料庫:
reuters
- 就職演說語料庫:
inaugural
- 其他語料庫;
文本語料庫結構
- isolated: 獨立型;
- categorized:分類型;
- overlapping:重疊型;
- temporal:暫時型;
基本語料庫函數
條件頻率分布
總結
以上就是自然語言處理
NLP
中
NLTK
子產品的相關知識介紹了,希望通過本文能解決你對
NLTK
的相關疑惑,歡迎評論互相交流!!!