一、前言
本文對梯度上升算法和改進的随機梯度上升算法進行了對比,總結了各自的優缺點,并對sklearn.linear_model.LogisticRegression進行了詳細介紹。
二、改進的随機梯度上升算法
梯度上升算法在每次更新回歸系數(最優參數)時,都需要周遊整個資料集。可以看一下我們之前寫的梯度上升算法:
def gradAscent(dataMatIn, classLabels):
dataMatrix = np.mat(dataMatIn) #轉換成numpy的mat
labelMat = np.mat(classLabels).transpose() #轉換成numpy的mat,并進行轉置
m, n = np.shape(dataMatrix) #傳回dataMatrix的大小。m為行數,n為列數。
alpha = 0.01 #移動步長,也就是學習速率,控制更新的幅度。
maxCycles = 500 #最大疊代次數
weights = np.ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights) #梯度上升矢量化公式
error = labelMat - h
weights = weights + alpha * dataMatrix.transpose() * error
return weights.getA(),weights_array #将矩陣轉換為數組,傳回權重數組
假設,我們使用的資料集一共有100個樣本。那麼,dataMatrix就是一個100*3的矩陣。每次計算h的時候,都要計算dataMatrix*weights這個矩陣乘法運算,要進行100*3次乘法運算和100*2次加法運算。同理,更新回歸系數(最優參數)weights時,也需要用到整個資料集,要進行矩陣乘法運算。總而言之,該方法處理100個左右的資料集時尚可,但如果有數十億樣本和成千上萬的特征,那麼該方法的計算複雜度就太高了。是以,需要對算法進行改進,我們每次更新回歸系數(最優參數)的時候,能不能不用所有樣本呢?一次隻用一個樣本點去更新回歸系數(最優參數)?這樣就可以有效減少計算量了,這種方法就叫做随機梯度上升算法。
1、随機梯度上升算法
讓我們直接看代碼:
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = np.shape(dataMatrix) #傳回dataMatrix的大小。m為行數,n為列數。
weights = np.ones(n) #參數初始化
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.01 #降低alpha的大小,每次減小1/(j+i)。
randIndex = int(random.uniform(0,len(dataIndex))) #随機選取樣本
h = sigmoid(sum(dataMatrix[randIndex]*weights)) #選擇随機選取的一個樣本,計算h
error = classLabels[randIndex] - h #計算誤差
weights = weights + alpha * error * dataMatrix[randIndex] #更新回歸系數
del(dataIndex[randIndex]) #删除已經使用的樣本
return weights #傳回
該算法第一個改進之處在于,alpha在每次疊代的時候都會調整,并且,雖然alpha會随着疊代次數不斷減小,但永遠不會減小到0,因為這裡還存在一個常數項。必須這樣做的原因是為了保證在多次疊代之後新資料仍然具有一定的影響。如果需要處理的問題是動态變化的,那麼可以适當加大上述常數項,來確定新的值獲得更大的回歸系數。另一點值得注意的是,在降低alpha的函數中,alpha每次減少1/(j+i),其中j是疊代次數,i是樣本點的下标。第二個改進的地方在于更新回歸系數(最優參數)時,隻使用一個樣本點,并且選擇的樣本點是随機的,每次疊代不使用已經用過的樣本點。這樣的方法,就有效地減少了計算量,并保證了回歸效果。
編寫代碼如下,看下改進的随機梯度上升算法分類效果如何:
# -*- coding:UTF-8 -*-
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
import numpy as np
import random
"""
函數說明:加載資料
Parameters:
無
Returns:
dataMat - 資料清單
labelMat - 标簽清單
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-08-28
"""
def loadDataSet():
dataMat = [] #建立資料清單
labelMat = [] #建立标簽清單
fr = open('testSet.txt') #打開檔案
for line in fr.readlines(): #逐行讀取
lineArr = line.strip().split() #去回車,放入清單
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #添加資料
labelMat.append(int(lineArr[2])) #添加标簽
fr.close() #關閉檔案
return dataMat, labelMat #傳回
"""
函數說明:sigmoid函數
Parameters:
inX - 資料
Returns:
sigmoid函數
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-08-28
"""
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
"""
函數說明:繪制資料集
Parameters:
weights - 權重參數數組
Returns:
無
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-08-30
"""
def plotBestFit(weights):
dataMat, labelMat = loadDataSet() #加載資料集
dataArr = np.array(dataMat) #轉換成numpy的array數組
n = np.shape(dataMat)[0] #資料個數
xcord1 = []; ycord1 = [] #正樣本
xcord2 = []; ycord2 = [] #負樣本
for i in range(n): #根據資料集标簽進行分類
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2]) #1為正樣本
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2]) #0為負樣本
fig = plt.figure()
ax = fig.add_subplot(111) #添加subplot
ax.scatter(xcord1, ycord1, s = 20, c = 'red', marker = 's',alpha=.5)#繪制正樣本
ax.scatter(xcord2, ycord2, s = 20, c = 'green',alpha=.5) #繪制負樣本
x = np.arange(-3.0, 3.0, 0.1)
y = (-weights[0] - weights[1] * x) / weights[2]
ax.plot(x, y)
plt.title('BestFit') #繪制title
plt.xlabel('X1'); plt.ylabel('X2') #繪制label
plt.show()
"""
函數說明:改進的随機梯度上升算法
Parameters:
dataMatrix - 資料數組
classLabels - 資料标簽
numIter - 疊代次數
Returns:
weights - 求得的回歸系數數組(最優參數)
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-08-31
"""
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = np.shape(dataMatrix) #傳回dataMatrix的大小。m為行數,n為列數。
weights = np.ones(n) #參數初始化
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.01 #降低alpha的大小,每次減小1/(j+i)。
randIndex = int(random.uniform(0,len(dataIndex))) #随機選取樣本
h = sigmoid(sum(dataMatrix[randIndex]*weights)) #選擇随機選取的一個樣本,計算h
error = classLabels[randIndex] - h #計算誤差
weights = weights + alpha * error * dataMatrix[randIndex] #更新回歸系數
del(dataIndex[randIndex]) #删除已經使用的樣本
return weights #傳回
if __name__ == '__main__':
dataMat, labelMat = loadDataSet()
weights = stocGradAscent1(np.array(dataMat), labelMat)
plotBestFit(weights)
代碼運作結果:
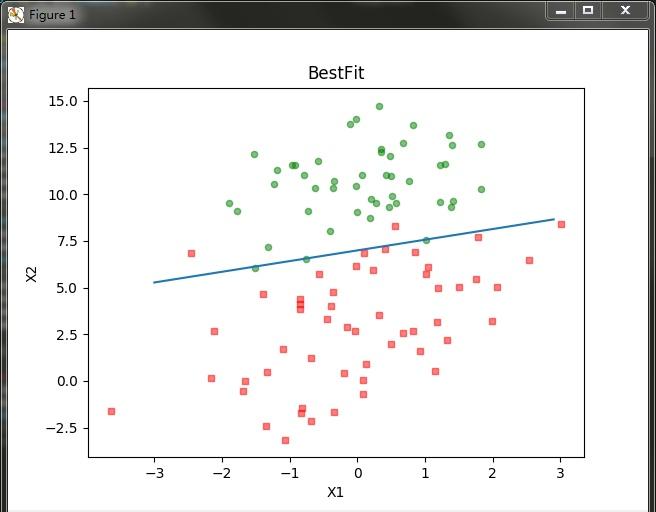
2、回歸系數與疊代次數的關系
可以看到分類效果也是不錯的。不過,從這個分類結果中,我們不好看出疊代次數和回歸系數的關系,也就不能直覺的看到每個回歸方法的收斂情況。是以,我們編寫程式,繪制出回歸系數和疊代次數的關系曲線:
# -*- coding:UTF-8 -*-
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
import numpy as np
import random
"""
函數說明:加載資料
Parameters:
無
Returns:
dataMat - 資料清單
labelMat - 标簽清單
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-08-28
"""
def loadDataSet():
dataMat = [] #建立資料清單
labelMat = [] #建立标簽清單
fr = open('testSet.txt') #打開檔案
for line in fr.readlines(): #逐行讀取
lineArr = line.strip().split() #去回車,放入清單
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #添加資料
labelMat.append(int(lineArr[2])) #添加标簽
fr.close() #關閉檔案
return dataMat, labelMat #傳回
"""
函數說明:sigmoid函數
Parameters:
inX - 資料
Returns:
sigmoid函數
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-08-28
"""
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
"""
函數說明:梯度上升算法
Parameters:
dataMatIn - 資料集
classLabels - 資料标簽
Returns:
weights.getA() - 求得的權重數組(最優參數)
weights_array - 每次更新的回歸系數
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-08-28
"""
def gradAscent(dataMatIn, classLabels):
dataMatrix = np.mat(dataMatIn) #轉換成numpy的mat
labelMat = np.mat(classLabels).transpose() #轉換成numpy的mat,并進行轉置
m, n = np.shape(dataMatrix) #傳回dataMatrix的大小。m為行數,n為列數。
alpha = 0.01 #移動步長,也就是學習速率,控制更新的幅度。
maxCycles = 500 #最大疊代次數
weights = np.ones((n,1))
weights_array = np.array([])
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights) #梯度上升矢量化公式
error = labelMat - h
weights = weights + alpha * dataMatrix.transpose() * error
weights_array = np.append(weights_array,weights)
weights_array = weights_array.reshape(maxCycles,n)
return weights.getA(),weights_array #将矩陣轉換為數組,并傳回
"""
函數說明:改進的随機梯度上升算法
Parameters:
dataMatrix - 資料數組
classLabels - 資料标簽
numIter - 疊代次數
Returns:
weights - 求得的回歸系數數組(最優參數)
weights_array - 每次更新的回歸系數
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-08-31
"""
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = np.shape(dataMatrix) #傳回dataMatrix的大小。m為行數,n為列數。
weights = np.ones(n) #參數初始化
weights_array = np.array([]) #存儲每次更新的回歸系數
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.01 #降低alpha的大小,每次減小1/(j+i)。
randIndex = int(random.uniform(0,len(dataIndex))) #随機選取樣本
h = sigmoid(sum(dataMatrix[randIndex]*weights)) #選擇随機選取的一個樣本,計算h
error = classLabels[randIndex] - h #計算誤差
weights = weights + alpha * error * dataMatrix[randIndex] #更新回歸系數
weights_array = np.append(weights_array,weights,axis=0) #添加回歸系數到數組中
del(dataIndex[randIndex]) #删除已經使用的樣本
weights_array = weights_array.reshape(numIter*m,n) #改變次元
return weights,weights_array #傳回
"""
函數說明:繪制回歸系數與疊代次數的關系
Parameters:
weights_array1 - 回歸系數數組1
weights_array2 - 回歸系數數組2
Returns:
無
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-08-30
"""
def plotWeights(weights_array1,weights_array2):
#設定漢字格式
font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)
#将fig畫布分隔成1行1列,不共享x軸和y軸,fig畫布的大小為(13,8)
#當nrow=3,nclos=2時,代表fig畫布被分為六個區域,axs[0][0]表示第一行第一列
fig, axs = plt.subplots(nrows=3, ncols=2,sharex=False, sharey=False, figsize=(20,10))
x1 = np.arange(0, len(weights_array1), 1)
#繪制w0與疊代次數的關系
axs[0][0].plot(x1,weights_array1[:,0])
axs0_title_text = axs[0][0].set_title(u'梯度上升算法:回歸系數與疊代次數關系',FontProperties=font)
axs0_ylabel_text = axs[0][0].set_ylabel(u'W0',FontProperties=font)
plt.setp(axs0_title_text, size=20, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=20, weight='bold', color='black')
#繪制w1與疊代次數的關系
axs[1][0].plot(x1,weights_array1[:,1])
axs1_ylabel_text = axs[1][0].set_ylabel(u'W1',FontProperties=font)
plt.setp(axs1_ylabel_text, size=20, weight='bold', color='black')
#繪制w2與疊代次數的關系
axs[2][0].plot(x1,weights_array1[:,2])
axs2_xlabel_text = axs[2][0].set_xlabel(u'疊代次數',FontProperties=font)
axs2_ylabel_text = axs[2][0].set_ylabel(u'W2',FontProperties=font)
plt.setp(axs2_xlabel_text, size=20, weight='bold', color='black')
plt.setp(axs2_ylabel_text, size=20, weight='bold', color='black')
x2 = np.arange(0, len(weights_array2), 1)
#繪制w0與疊代次數的關系
axs[0][1].plot(x2,weights_array2[:,0])
axs0_title_text = axs[0][1].set_title(u'改進的随機梯度上升算法:回歸系數與疊代次數關系',FontProperties=font)
axs0_ylabel_text = axs[0][1].set_ylabel(u'W0',FontProperties=font)
plt.setp(axs0_title_text, size=20, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=20, weight='bold', color='black')
#繪制w1與疊代次數的關系
axs[1][1].plot(x2,weights_array2[:,1])
axs1_ylabel_text = axs[1][1].set_ylabel(u'W1',FontProperties=font)
plt.setp(axs1_ylabel_text, size=20, weight='bold', color='black')
#繪制w2與疊代次數的關系
axs[2][1].plot(x2,weights_array2[:,2])
axs2_xlabel_text = axs[2][1].set_xlabel(u'疊代次數',FontProperties=font)
axs2_ylabel_text = axs[2][1].set_ylabel(u'W1',FontProperties=font)
plt.setp(axs2_xlabel_text, size=20, weight='bold', color='black')
plt.setp(axs2_ylabel_text, size=20, weight='bold', color='black')
plt.show()
if __name__ == '__main__':
dataMat, labelMat = loadDataSet()
weights1,weights_array1 = stocGradAscent1(np.array(dataMat), labelMat)
weights2,weights_array2 = gradAscent(dataMat, labelMat)
plotWeights(weights_array1, weights_array2)
運作結果如下:

由于改進的随機梯度上升算法,随機選取樣本點,是以每次的運作結果是不同的。但是大體趨勢是一樣的。我們改進的随機梯度上升算法收斂效果更好。為什麼這麼說呢?讓我們分析一下。我們一共有100個樣本點,改進的随機梯度上升算法疊代次數為150。而上圖顯示15000次疊代次數的原因是,使用一次樣本就更新一下回歸系數。是以,疊代150次,相當于更新回歸系數150*100=15000次。簡而言之,疊代150次,更新1.5萬次回歸參數。從上圖左側的改進随機梯度上升算法回歸效果中可以看出,其實在更新2000次回歸系數的時候,已經收斂了。相當于周遊整個資料集20次的時候,回歸系數已收斂。訓練已完成。
再讓我們看看上圖右側的梯度上升算法回歸效果,梯度上升算法每次更新回歸系數都要周遊整個資料集。從圖中可以看出,當疊代次數為300多次的時候,回歸系數才收斂。湊個整,就當它在周遊整個資料集300次的時候已經收斂好了。
沒有對比就沒有傷害,改進的随機梯度上升算法,在周遊資料集的第20次開始收斂。而梯度上升算法,在周遊資料集的第300次才開始收斂。想像一下,大量資料的情況下,誰更牛逼?
三、從疝氣病症狀預測病馬的死亡率
1、實戰背景
本次實戰内容,将使用Logistic回歸來預測患疝氣病的馬的存活問題。原始資料集下載下傳位址:資料集下載下傳
這裡的資料包含了368個樣本和28個特征。這種病不一定源自馬的腸胃問題,其他問題也可能引發馬疝病。該資料集中包含了醫院檢測馬疝病的一些名額,有的名額比較主觀,有的名額難以測量,例如馬的疼痛級别。另外需要說明的是,除了部分名額主觀和難以測量外,該資料還存在一個問題,資料集中有30%的值是缺失的。下面将首先介紹如何處理資料集中的資料缺失問題,然後再利用Logistic回歸和随機梯度上升算法來預測病馬的生死。
2、準備資料
資料中的缺失值是一個非常棘手的問題,很多文獻都緻力于解決這個問題。那麼,資料缺失究竟帶來了什麼問題?假設有100個樣本和20個特征,這些資料都是機器收集回來的。若機器上的某個傳感器損壞導緻一個特征無效時該怎麼辦?它們是否還可用?答案是肯定的。因為有時候資料相當昂貴,扔掉和重新擷取都是不可取的,是以必須采用一些方法來解決這個問題。下面給出了一些可選的做法:
- 使用可用特征的均值來填補缺失值;
- 使用特殊值來填補缺失值,如-1;
- 忽略有缺失值的樣本;
- 使用相似樣本的均值添補缺失值;
- 使用另外的機器學習算法預測缺失值。
預處理資料做兩件事:
- 如果測試集中一條資料的特征值已經确實,那麼我們選擇實數0來替換所有缺失值,因為本文使用Logistic回歸。是以這樣做不會影響回歸系數的值。sigmoid(0)=0.5,即它對結果的預測不具有任何傾向性。
- 如果測試集中一條資料的類别标簽已經缺失,那麼我們将該類别資料丢棄,因為類别标簽與特征不同,很難确定采用某個合适的值來替換。
原始的資料集經過處理,儲存為兩個檔案:horseColicTest.txt和horseColicTraining.txt。已經處理好的“幹淨”可用的資料集下載下傳位址:
- 資料集1
- 資料集2
有了這些資料集,我們隻需要一個Logistic分類器,就可以利用該分類器來預測病馬的生死問題了。
3、使用Python建構Logistic回歸分類器
在使用Sklearn建構Logistic回歸分類器之前,我們先用自己寫的改進的随機梯度上升算法進行預測,先熱熱身。使用Logistic回歸方法進行分類并不需要做很多工作,所需做的隻是把測試集上每個特征向量乘以最優化方法得來的回歸系數,再将乘積結果求和,最後輸入到Sigmoid函數中即可。如果對應的Sigmoid值大于0.5就預測類别标簽為1,否則為0。
# -*- coding:UTF-8 -*-
import numpy as np
import random
"""
函數說明:sigmoid函數
Parameters:
inX - 資料
Returns:
sigmoid函數
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-09-05
"""
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
"""
函數說明:改進的随機梯度上升算法
Parameters:
dataMatrix - 資料數組
classLabels - 資料标簽
numIter - 疊代次數
Returns:
weights - 求得的回歸系數數組(最優參數)
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-09-05
"""
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = np.shape(dataMatrix) #傳回dataMatrix的大小。m為行數,n為列數。
weights = np.ones(n) #參數初始化 #存儲每次更新的回歸系數
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.01 #降低alpha的大小,每次減小1/(j+i)。
randIndex = int(random.uniform(0,len(dataIndex))) #随機選取樣本
h = sigmoid(sum(dataMatrix[randIndex]*weights)) #選擇随機選取的一個樣本,計算h
error = classLabels[randIndex] - h #計算誤差
weights = weights + alpha * error * dataMatrix[randIndex] #更新回歸系數
del(dataIndex[randIndex]) #删除已經使用的樣本
return weights #傳回
"""
函數說明:使用Python寫的Logistic分類器做預測
Parameters:
無
Returns:
無
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-09-05
"""
def colicTest():
frTrain = open('horseColicTraining.txt') #打開訓練集
frTest = open('horseColicTest.txt') #打開測試集
trainingSet = []; trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr = []
for i in range(len(currLine)-1):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[-1]))
trainWeights = stocGradAscent1(np.array(trainingSet), trainingLabels, 500) #使用改進的随即上升梯度訓練
errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr =[]
for i in range(len(currLine)-1):
lineArr.append(float(currLine[i]))
if int(classifyVector(np.array(lineArr), trainWeights))!= int(currLine[-1]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec) * 100 #錯誤率計算
print("測試集錯誤率為: %.2f%%" % errorRate)
"""
函數說明:分類函數
Parameters:
inX - 特征向量
weights - 回歸系數
Returns:
分類結果
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-09-05
"""
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
if __name__ == '__main__':
colicTest()
運作結果如下:
錯誤率還是蠻高的,而且耗時1.9s,并且每次運作的錯誤率也是不同的,錯誤率高的時候可能達到40%多。為啥這樣?首先,因為資料集本身有30%的資料缺失,這個是不能避免的。另一個主要原因是,我們使用的是改進的随機梯度上升算法,因為資料集本身就很小,就幾百的資料量。用改進的随機梯度上升算法顯然不合适。讓我們再試試梯度上升算法,看看它的效果如何?
# -*- coding:UTF-8 -*-
import numpy as np
import random
"""
函數說明:sigmoid函數
Parameters:
inX - 資料
Returns:
sigmoid函數
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-09-05
"""
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
"""
函數說明:梯度上升算法
Parameters:
dataMatIn - 資料集
classLabels - 資料标簽
Returns:
weights.getA() - 求得的權重數組(最優參數)
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-08-28
"""
def gradAscent(dataMatIn, classLabels):
dataMatrix = np.mat(dataMatIn) #轉換成numpy的mat
labelMat = np.mat(classLabels).transpose() #轉換成numpy的mat,并進行轉置
m, n = np.shape(dataMatrix) #傳回dataMatrix的大小。m為行數,n為列數。
alpha = 0.01 #移動步長,也就是學習速率,控制更新的幅度。
maxCycles = 500 #最大疊代次數
weights = np.ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights) #梯度上升矢量化公式
error = labelMat - h
weights = weights + alpha * dataMatrix.transpose() * error
return weights.getA() #将矩陣轉換為數組,并傳回
"""
函數說明:使用Python寫的Logistic分類器做預測
Parameters:
無
Returns:
無
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-09-05
"""
def colicTest():
frTrain = open('horseColicTraining.txt') #打開訓練集
frTest = open('horseColicTest.txt') #打開測試集
trainingSet = []; trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr = []
for i in range(len(currLine)-1):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[-1]))
trainWeights = gradAscent(np.array(trainingSet), trainingLabels) #使用改進的随即上升梯度訓練
errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr =[]
for i in range(len(currLine)-1):
lineArr.append(float(currLine[i]))
if int(classifyVector(np.array(lineArr), trainWeights[:,0]))!= int(currLine[-1]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec) * 100 #錯誤率計算
print("測試集錯誤率為: %.2f%%" % errorRate)
"""
函數說明:分類函數
Parameters:
inX - 特征向量
weights - 回歸系數
Returns:
分類結果
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-09-05
"""
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
if __name__ == '__main__':
colicTest()
運作結果如下:
可以看到算法耗時減少了,錯誤率穩定且較低。很顯然,使用随機梯度上升算法,反而得不償失了。是以可以得到如下結論:
- 當資料集較小時,我們使用梯度上升算法
- 當資料集較大時,我們使用改進的随機梯度上升算法
對應的,在Sklearn中,我們就可以根據資料情況選擇優化算法,比如資料較小的時候,我們使用liblinear,資料較大時,我們使用sag和saga。
四、使用Sklearn建構Logistic回歸分類器
開始新一輪的征程,讓我們看下Sklearn的Logistic回歸分類器!
官方英文文檔位址:點我檢視
sklearn.linear_model子產品提供了很多模型供我們使用,比如Logistic回歸、Lasso回歸、貝葉斯脊回歸等,可見需要學習的東西還有很多很多。本篇文章,我們使用LogisticRegressioin。
1、LogisticRegression
讓我們先看下LogisticRegression這個函數,一共有14個參數:
參數說明如下:
- penalty:懲罰項,str類型,可選參數為l1和l2,預設為l2。用于指定懲罰項中使用的規範。newton-cg、sag和lbfgs求解算法隻支援L2規範。L1G規範假設的是模型的參數滿足拉普拉斯分布,L2假設的模型參數滿足高斯分布,所謂的範式就是加上對參數的限制,使得模型更不會過拟合(overfit),但是如果要說是不是加了限制就會好,這個沒有人能回答,隻能說,加限制的情況下,理論上應該可以獲得泛化能力更強的結果。
- dual:對偶或原始方法,bool類型,預設為False。對偶方法隻用在求解線性多核(liblinear)的L2懲罰項上。當樣本數量>樣本特征的時候,dual通常設定為False。
- tol:停止求解的标準,float類型,預設為1e-4。就是求解到多少的時候,停止,認為已經求出最優解。
- c:正則化系數λ的倒數,float類型,預設為1.0。必須是正浮點型數。像SVM一樣,越小的數值表示越強的正則化。
- fit_intercept:是否存在截距或偏差,bool類型,預設為True。
- intercept_scaling:僅在正則化項為"liblinear",且fit_intercept設定為True時有用。float類型,預設為1。
- class_weight:用于标示分類模型中各種類型的權重,可以是一個字典或者'balanced'字元串,預設為不輸入,也就是不考慮權重,即為None。如果選擇輸入的話,可以選擇balanced讓類庫自己計算類型權重,或者自己輸入各個類型的權重。舉個例子,比如對于0,1的二進制模型,我們可以定義class_weight={0:0.9,1:0.1},這樣類型0的權重為90%,而類型1的權重為10%。如果class_weight選擇balanced,那麼類庫會根據訓練樣本量來計算權重。某種類型樣本量越多,則權重越低,樣本量越少,則權重越高。當class_weight為balanced時,類權重計算方法如下:n_samples / (n_classes * np.bincount(y))。n_samples為樣本數,n_classes為類别數量,np.bincount(y)會輸出每個類的樣本數,例如y=[1,0,0,1,1],則np.bincount(y)=[2,3]。
- 那麼class_weight有什麼作用呢?
- 在分類模型中,我們經常會遇到兩類問題:
- 1.第一種是誤分類的代價很高。比如對合法使用者和非法使用者進行分類,将非法使用者分類為合法使用者的代價很高,我們甯願将合法使用者分類為非法使用者,這時可以人工再甄别,但是卻不願将非法使用者分類為合法使用者。這時,我們可以适當提高非法使用者的權重。
- 2. 第二種是樣本是高度失衡的,比如我們有合法使用者和非法使用者的二進制樣本資料10000條,裡面合法使用者有9995條,非法使用者隻有5條,如果我們不考慮權重,則我們可以将所有的測試集都預測為合法使用者,這樣預測準确率理論上有99.95%,但是卻沒有任何意義。這時,我們可以選擇balanced,讓類庫自動提高非法使用者樣本的權重。提高了某種分類的權重,相比不考慮權重,會有更多的樣本分類劃分到高權重的類别,進而可以解決上面兩類問題。
- 那麼class_weight有什麼作用呢?
- random_state:随機數種子,int類型,可選參數,預設為無,僅在正則化優化算法為sag,liblinear時有用。
- solver:優化算法選擇參數,隻有五個可選參數,即newton-cg,lbfgs,liblinear,sag,saga。預設為liblinear。solver參數決定了我們對邏輯回歸損失函數的優化方法,有四種算法可以選擇,分别是:
- liblinear:使用了開源的liblinear庫實作,内部使用了坐标軸下降法來疊代優化損失函數。
- lbfgs:拟牛頓法的一種,利用損失函數二階導數矩陣即海森矩陣來疊代優化損失函數。
- newton-cg:也是牛頓法家族的一種,利用損失函數二階導數矩陣即海森矩陣來疊代優化損失函數。
- sag:即随機平均梯度下降,是梯度下降法的變種,和普通梯度下降法的差別是每次疊代僅僅用一部分的樣本來計算梯度,适合于樣本資料多的時候。
- saga:線性收斂的随機優化算法的的變重。
- 總結:
- liblinear适用于小資料集,而sag和saga适用于大資料集因為速度更快。
- 對于多分類問題,隻有newton-cg,sag,saga和lbfgs能夠處理多項損失,而liblinear受限于一對剩餘(OvR)。啥意思,就是用liblinear的時候,如果是多分類問題,得先把一種類别作為一個類别,剩餘的所有類别作為另外一個類别。一次類推,周遊所有類别,進行分類。
- newton-cg,sag和lbfgs這三種優化算法時都需要損失函數的一階或者二階連續導數,是以不能用于沒有連續導數的L1正則化,隻能用于L2正則化。而liblinear和saga通吃L1正則化和L2正則化。
- 同時,sag每次僅僅使用了部分樣本進行梯度疊代,是以當樣本量少的時候不要選擇它,而如果樣本量非常大,比如大于10萬,sag是第一選擇。但是sag不能用于L1正則化,是以當你有大量的樣本,又需要L1正則化的話就要自己做取舍了。要麼通過對樣本采樣來降低樣本量,要麼回到L2正則化。
- 從上面的描述,大家可能覺得,既然newton-cg, lbfgs和sag這麼多限制,如果不是大樣本,我們選擇liblinear不就行了嘛!錯,因為liblinear也有自己的弱點!我們知道,邏輯回歸有二進制邏輯回歸和多元邏輯回歸。對于多元邏輯回歸常見的有one-vs-rest(OvR)和many-vs-many(MvM)兩種。而MvM一般比OvR分類相對準确一些。郁悶的是liblinear隻支援OvR,不支援MvM,這樣如果我們需要相對精确的多元邏輯回歸時,就不能選擇liblinear了。也意味着如果我們需要相對精确的多元邏輯回歸不能使用L1正則化了。
- max_iter:算法收斂最大疊代次數,int類型,預設為10。僅在正則化優化算法為newton-cg, sag和lbfgs才有用,算法收斂的最大疊代次數。
- multi_class:分類方式選擇參數,str類型,可選參數為ovr和multinomial,預設為ovr。ovr即前面提到的one-vs-rest(OvR),而multinomial即前面提到的many-vs-many(MvM)。如果是二進制邏輯回歸,ovr和multinomial并沒有任何差別,差別主要在多元邏輯回歸上。
- OvR和MvM有什麼不同?
- OvR的思想很簡單,無論你是多少元邏輯回歸,我們都可以看做二進制邏輯回歸。具體做法是,對于第K類的分類決策,我們把所有第K類的樣本作為正例,除了第K類樣本以外的所有樣本都作為負例,然後在上面做二進制邏輯回歸,得到第K類的分類模型。其他類的分類模型獲得以此類推。
- 而MvM則相對複雜,這裡舉MvM的特例one-vs-one(OvO)作講解。如果模型有T類,我們每次在所有的T類樣本裡面選擇兩類樣本出來,不妨記為T1類和T2類,把所有的輸出為T1和T2的樣本放在一起,把T1作為正例,T2作為負例,進行二進制邏輯回歸,得到模型參數。我們一共需要T(T-1)/2次分類。
- 可以看出OvR相對簡單,但分類效果相對略差(這裡指大多數樣本分布情況,某些樣本分布下OvR可能更好)。而MvM分類相對精确,但是分類速度沒有OvR快。如果選擇了ovr,則4種損失函數的優化方法liblinear,newton-cg,lbfgs和sag都可以選擇。但是如果選擇了multinomial,則隻能選擇newton-cg, lbfgs和sag了。
- OvR和MvM有什麼不同?
- verbose:日志冗長度,int類型。預設為0。就是不輸出訓練過程,1的時候偶爾輸出結果,大于1,對于每個子模型都輸出。
- warm_start:熱啟動參數,bool類型。預設為False。如果為True,則下一次訓練是以追加樹的形式進行(重新使用上一次的調用作為初始化)。
- n_jobs:并行數。int類型,預設為1。1的時候,用CPU的一個核心運作程式,2的時候,用CPU的2個核心運作程式。為-1的時候,用所有CPU的核心運作程式。
累死我了....終于寫完所有參數了。
除此之外,LogisticRegression也有一些方法供我們使用:
有一些方法和MultinomialNB的方法都是類似的,是以不再累述。
對于每個函數的具體使用,可以看下官方文檔:點我檢視
同時,如果對于過拟合、正則化、L1範數、L2範數不了解的,可以看這位大牛的部落格:點我檢視
2、編寫代碼
了解到這些,我們就可以編寫Sklearn分類器的代碼了。代碼非常短:
# -*- coding:UTF-8 -*-
from sklearn.linear_model import LogisticRegression
"""
函數說明:使用Sklearn建構Logistic回歸分類器
Parameters:
無
Returns:
無
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-09-05
"""
def colicSklearn():
frTrain = open('horseColicTraining.txt') #打開訓練集
frTest = open('horseColicTest.txt') #打開測試集
trainingSet = []; trainingLabels = []
testSet = []; testLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr = []
for i in range(len(currLine)-1):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[-1]))
for line in frTest.readlines():
currLine = line.strip().split('\t')
lineArr =[]
for i in range(len(currLine)-1):
lineArr.append(float(currLine[i]))
testSet.append(lineArr)
testLabels.append(float(currLine[-1]))
classifier = LogisticRegression(solver='liblinear',max_iter=10).fit(trainingSet, trainingLabels)
test_accurcy = classifier.score(testSet, testLabels) * 100
print('正确率:%f%%' % test_accurcy)
if __name__ == '__main__':
colicSklearn()
運作結果如下:
可以看到,正确率又高一些了。更改solver參數,比如設定為sag,使用随機平均梯度下降算法,看一看效果。你會發現,有警告了。
顯而易見,警告是因為算法還沒有收斂。更改max_iter=5000,再運作代碼:
可以看到,對于我們這樣的小資料集,sag算法需要疊代上千次才收斂,而liblinear隻需要不到10次。
還是那句話,我們需要根據資料集情況,選擇最優化算法。
五、總結
1、Logistic回歸的優缺點
優點:
- 實作簡單,易于了解和實作;計算代價不高,速度很快,存儲資源低。
缺點:
- 容易欠拟合,分類精度可能不高。
2、其他
- Logistic回歸的目的是尋找一個非線性函數Sigmoid的最佳拟合參數,求解過程可以由最優化算法完成。
- 改進的一些最優化算法,比如sag。它可以在新資料到來時就完成參數更新,而不需要重新讀取整個資料集來進行批量處理。
- 機器學習的一個重要問題就是如何處理缺失資料。這個問題沒有标準答案,取決于實際應用中的需求。現有一些解決方案,每種方案都各有優缺點。
- 我們需要根據資料的情況,這是Sklearn的參數,以期達到更好的分類效果。