原文連結:http://tecdat.cn/?p=3863
原文出處:拓端資料部落
對于某企業新使用者,會利用大資料來分析該使用者的資訊來确定是否為付費使用者,弄清楚使用者屬性,進而針對性的進行營銷,提高營運人員的辦事效率。
對于付費使用者預測,主要是思考收入由哪些因素推動,再對每個因素做預測,最後得出付費預測。這其實不是一個财務問題,是一個業務問題。
流失預測。這方面會偏向于大額付費使用者,提取額特征向量運用到應用場景的使用者流失和預測裡面去。
方法
回歸是一種極易了解的模型,就相當于y=f(x),表明自變量x與因變量y的關系。最常見問題有如醫生治病時的望、聞、問、切,之後判定病人是否生病或生了什麼病,其中的望聞問切就是擷取自變量x,即特征資料,判斷是否生病就相當于擷取因變量y,即預測分類。
問題描述
我們嘗試并預測使用者是否可以根據資料中可用的人口資訊變量使用邏輯回歸預測月度付費是否超過 50K。
在這個過程中,我們将:
1.導入資料
2.檢查類别偏差
3.建立訓練和測試樣本
4.建立logit模型并預測測試資料
5.模型診斷
檢查類偏差
理想情況下,Y變量中事件和非事件的比例大緻相同。 是以,我們首先檢查因變量ABOVE 50K中的類的比例。
0 1
24720 7841
顯然,不同付費人群比例 有偏差 。 是以我們必須以大緻相等的比例對觀測值進行抽樣,以獲得更好的模型。
建構Logit模型和預測
确定模型的最優預測機率截止值,預設的截止預測機率分數為0.5或訓練資料中1和0的比值。 但有時,調整機率截止值可以提高開發和驗證樣本的準确性。InformationValue :: optimalCutoff功能提供了找到最佳截止值,減少錯誤分類錯誤。
optCutOff <- optimalCutoff(testData$ABOVE50K, predicted)[1]
=> 0.71
模型診斷
分類錯誤
錯誤分類錯誤是預測與實際的不比對百分比 。 錯誤分類錯誤越低, 模型越好。
misClassError(testData$ABOVE50K, predicted, threshold = optCutOff)
[1] 0.0892
ROC曲線
ROC曲線指受試者工作特征曲線 / 接收器操作特性曲線(receiver operating characteristic curve), 是反映敏感性和特異性連續變量的綜合名額,是用構圖法揭示敏感性和特異性的互相關系,它通過将連續變量設定出多個不同的臨界值,進而計算出一系列敏感性和特異性,再以敏感性為縱坐标、(1-特異性)為橫坐标繪制成曲線,曲線下面積越大,診斷準确性越高。在ROC曲線上,最靠近坐标圖左上方的點為敏感性和特異性均較高的臨界值。
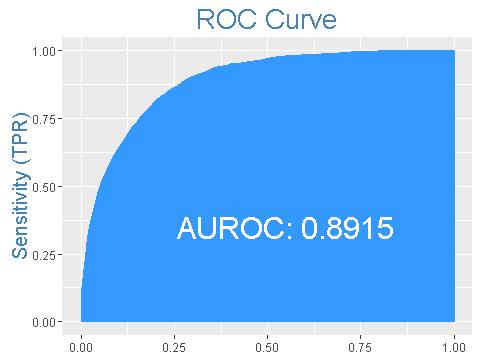
上述模型的ROC曲線面積為89%,相當不錯。
一緻性
簡單來說,在1-0 的所有組合中,一緻性是預測對的百分比 ,一緻性越高,模型的品質越好。
$Concordance
[1] 0.8915107
$Discordance
[1] 0.1084893
$Tied
[1] -2.775558e-17
$Pairs
[1] 45252896
上述型号的89.2%的一緻性确實是一個很好的模型。
混淆矩陣
在人工智能中,混淆矩陣(confusion matrix)是可視化工具,特别用于監督學習,在無監督學習一般叫做比對矩陣。其每一列代表預測值,每一行代表的是實際的類别。這個名字來源于它可以非常容易的表明多個類别是否有混淆(也就是一個class被預測成另一個class)。
confusionMatrix(testData$ABOVE50K, predicted, threshold = optCutOff)
0 1
0 18849 1543
1 383 810
結論
這裡僅僅介紹了模型的建立和評估。通過模型的結論,我們可以得到一些已經為公衆所接受和熟知的現象是:付費和受教育程度、智力、年齡以及性别等相關。 基于此使用者規模預測模型,結合使用者的人口資訊,即可粗略預估産品在一般情況下的收入情況, 進而判斷就得到了付費使用者預測模型,如果把收入分類轉換成流失使用者和有效使用者,就得到了流失使用者預測模型。

最受歡迎的見解
1.R語言多元Logistic邏輯回歸 應用案例
2.面闆平滑轉移回歸(PSTR)分析案例實作
3.matlab中的偏最小二乘回歸(PLSR)和主成分回歸(PCR)
4.R語言泊松Poisson回歸模型分析案例
5.R語言回歸中的Hosmer-Lemeshow拟合優度檢驗
6.r語言中對LASSO回歸,Ridge嶺回歸和Elastic Net模型實作
7.在R語言中實作Logistic邏輯回歸
8.python用線性回歸預測股票價格
9.R語言如何在生存分析與Cox回歸中計算IDI,NRI名額