一 大資料的架構回顧二 大資料的企業應用
一 大資料的架構回顧
Hadoop
job 送出簡圖 或 YARN 架構 或 YARN 工作機制 或 job 送出流程
0、job 送出簡圖
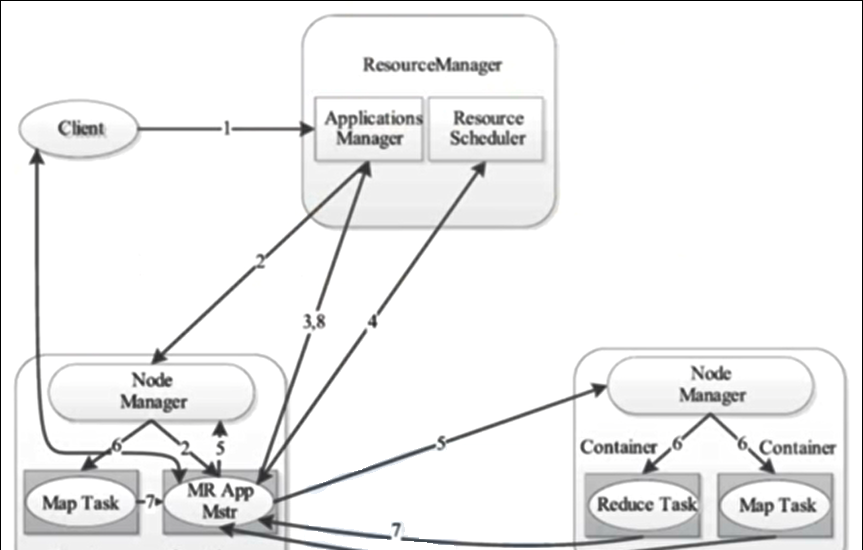
1、YARN 架構

2、YARN 工作機制
3、job 送出流程源碼解析圖解
MapReduce 的 Shuffle 過程介紹
Shuffle 的本義是洗牌、混洗,把一組有一定規則的資料盡量轉換成一組無規則的資料,越随機越好。
MapReduce 中的 Shuffle 更像是洗牌的逆過程,把一組無規則的資料盡量轉換成一組具有一定規則的資料。
為什麼 MapReduce 計算模型需要 Shuffle 過程?我們都知道 MapReduce 計算模型一般包括兩個重要的階段:Map 是映射,負責資料的過濾分發;Reduce 是規約,負責資料的計算歸并。
Reduce 的資料來源于 Map,Map 的輸出即是 Reduce 的輸入,Reduce 需要通過 Shuffle來 擷取資料。
從 Map 輸出到 Reduce 輸入的整個過程可以廣義地稱為 Shuffle。Shuffle 橫跨 Map 端和 Reduce 端,在 Map 端包括 Spill 過程,在 Reduce 端包括 copy 和 sort 過程,如圖所示: 複制
環形緩沖區簡圖
Zookeeper
使用 zookeeper 監聽伺服器節點動态上下線案例
Zookeeper 中維護 Kafka 時的存儲結構如下:
Flume
Flume Agent 内部原理
Flume Agent 的聚合
Flume 的負載均衡
Kafka
Kafka 工作流程1
Kafka 工作流程2
Kafka 高階消費者 和 低階消費者
HBase
HBase 架構圖
HBase 讀資料流程
HBase 寫資料流程
Hive
1、HQL 的編寫、練習(一定要好好寫!!!每天寫一條!!!超級重要!!!想進大廠的必備!!!牛客網HQL題庫:https://www.nowcoder.com/ta/sql)
2、Hive 的調優:https://www.cnblogs.com/chenmingjun/p/10452686.html
3、資料倉庫的理論 + 簡單的數倉庫搭建
Sqoop
Sqoop 是一款開源的工具,主要用于在 Hadoop(Hive) 與傳統的資料庫 (mysql,postgresql,…) 間進行資料的高校傳遞,可以将一個關系型資料庫(例如:MySQL,Oracle,Postgres等)中的資料導入到 Hadoop 的 HDFS 中,也可以将 HDFS 的資料導進到關系型資料庫中。
Sqoop 的批量導入必須要會,面試經常要問。
DataX
是阿裡開源的架構,支援很多資料源之間的轉化。但是隻開源了單節點的源代碼,分布式的代碼沒有開源。
支援資料庫如下:
Spark
二 大資料的企業應用
應用一:資料倉庫的搭建
資料倉庫各層圖解
資料倉庫涉及到的知識點
應用二:産品資訊分析
應用三:用于行為分析
應用四:人工智能基礎