推薦系統回顧 & 冷啟動問題
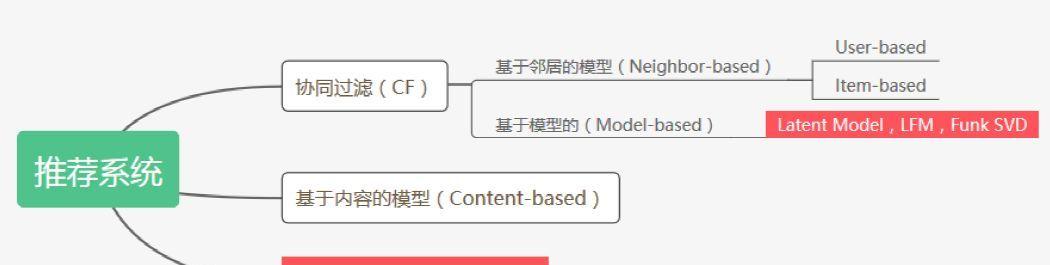
推薦系統的主流算法分為兩類:基于記憶的(Memory-based,具體包括User-based和Item-based),基于模型的(Model-based)和基于内容的(Content-based)。在基于模型的方法中,隐模型(Latent Model)又是其中的代表,并且已經成為大多數推薦系統的選擇,例如基于矩陣分解的LFM(Latent Factor Model)。
LFM主要依靠Users和Items形成的偏好矩陣(Preference Matrix)來估計出一個可以補全原偏好矩陣的兩個分解矩陣。這種方法簡單有效,而且因為分解出來的矩陣大小遠遠小于原矩陣,是以也十分節省存儲空間。
但是,以LFM為代表的利用Users和Items的互動資訊來進行推薦的隐模型,矩陣越稀疏,效果就會越差,極端情況就是,來了一些新的User或者Item,它們壓根沒有任何曆史互動資訊,即冷啟動(Cold Start)問題,這時LFM就真無能為力了。是以,不少的方法開始利用Users和Items的内容資訊(Content)來輔助解決冷啟動問題,跟之前的LFM結合起來,形成Hybrid model。甚至有一些模型完全使用基于内容的方法(Content-based)來進行推薦。然而,Hybrid的方法,使得模型擁有多個訓練目标函數,使得訓練過程變得十分複雜;而完全基于内容的方法,在實證檢驗中被發現,性能遠遠不如Memory-based的方法。
本文介紹的一篇論文,提出了一種借用神經網絡中的Dropout的思想,來處理冷啟動問題,想法十分新穎而有趣。而且,本文提出的一種模型,可以結合Memory和Content的資訊,但是隻使用一個目标函數,即擁有了以往Hybrid model的性能,還解決了冷啟動問題,同時大大降低了模型訓練的複雜程度。

Ⅰ. 論文主要思想
前面講了,要處理冷啟動問題,我們必須使用content資訊。但是想要整個系統的推薦效果較好,我們也必須使用preference資訊。目前最好的方法,就是二者結合形成的Hybrid方法,但是往往有多目标函數,訓練複雜。于是本文的作者就想:
如何把content和preference的資訊都結合起來,同時讓訓練過程更簡單呢?
作者們想到,冷啟動問題,就相當于一種資料缺失問題。而資料缺失的問題又可以使用Dropout來進行模拟。
是以,針對冷啟動問題,本文不是引入額外的内容資訊和額外的目标函數,而是改進整個學習過程,讓模型可以針對這種缺失的輸入來訓練。
Ⅱ. Notations
由于微信公衆号沒法打公式,下面用圖檔代替:
Ⅲ. 模型架構 & 訓練方法
前面講過,我們是使和來訓練模型,R如何輸入呢?直接的想法就是把R的每一行每一列作為Users和Items的preference向量輸入,但是由于Users和Items數量太大了,難以訓練。這個時候,之前的LFM就派上用場了。我們先把R分解成兩個小矩陣U和V,我們可以認為,U和V相乘可以基本重構R,涵蓋了R的絕大部分資訊。是以,在preference方面,我們使用U和V來代替R作為模型的輸入。
架構圖如下:
定義我們的目标函數為:
這個目标函數一開始不大了解,直接從公式看,就是希望我們訓練出來的兩個user和item的向量盡可能拟合原來的向量可以看做是通過Latent Model得到的,而可以看做是通過一個深度神經網絡DNN得到的。是以目标函數就是縮小Latent Model與DNN的差異。而Latent Model的結果是固定的,DNN是依靠我們訓練的,是以是以Latent Model為标杆來訓練的。
U和V都是有比較豐富的preference資訊的向量,在實際推薦中,如果preference資訊比較豐富,那麼我們隻利用這些資訊就可以得到很好的推薦效果。我們在冷啟動時利用content資訊,也是希望能夠達到有preference資訊時候的性能。是以,當我們有充足的preference資訊的時候,訓練出的模型給予ntent内容的權重會趨于0,這樣就回歸了傳統的Latent Model了。
在訓練時,為了模拟冷啟動問題,我們會按照一定的抽樣比例,讓user或者item的preference向量為0,是以,針對冷啟動,其目标函數為:
這個時候,由于preference向量的缺失,是以content會竭盡所能去擔起大任,進而可以逼近Latent Model的效果,這也是我們的目的:preference不夠,content來湊。
從上面的分析可以看出,僅僅使用一個目标函數,這個模型就可以一箭雙雕:設定dropout的時候,鼓勵模型去使用content資訊;不設定dropout的時候,模型會盡量使用preference資訊。另外,本身Dropout作為一種正則化手段,也可以防止模型過拟合。
上面解釋了模型在熱啟動和冷啟動時是怎麼處理的。此外,文章還提出了在冷啟動後,使用者或者項目開始産生少數的preference資訊的時候應該怎麼處理,這樣才能讓不同階段無縫銜接。
以往處理這種準冷啟動問題也很複雜,因為它既不是冷啟動,但是可用的preference資訊也十分稀少。而更新一次latent model是比較費時的,不能說來一些preference資訊就更新一次,再來推薦。是以本文給出了一種簡單的方法,用user互動過的那少數幾個item的向量的平均,來代表這個user的向量。他們稱這個過程為transformation。是以,使用者有一些互動之後,先這樣transform一下,先拿去用,背景慢慢地更新latent model,等更新好了,再換成latent model來進行推薦。
是以,作者在模型訓練的時候,還增加了這樣的一個transform過程。
這樣,整體的訓練算法就是這樣的:
Ⅳ. 實驗 & 結果展示
訓練過程是這樣的,我們有N個users和M個items,是以理論上可以形成N×M個樣本。
設定一個mini-batch,比如100,每次抽100個user-item pair,設定一個dropout rate,例如0.3,則從100個使用者中選出30個pair。對于這30個pair,我們輪流使用dropout和transform來處理後輸入DNN,其餘的70個則直接輸入DNN。
接下來看看實驗。
實驗使用的資料集是一個科學文章資料庫,使用者可以在上面收藏各種文章,系統也會向使用者推薦文章。
文章的content向量是tf-idf向量,使用者由于沒有content資訊是以忽略了。另外,preference矩陣R稀疏程度達到99.8%,因為平均每個使用者收藏文章30多篇,而資料集中有一兩萬篇文章。
看看效果:
可以看出來cold start問題中,使用dropout可以大大提升推薦性能。但是過高的dropout rate會影響warm start的性能。
另外,作者也将模型和之前的一些模型做了對比,其中:
CTR和CDL是hybrid model,WMF是latent model,DeepMusic則是一個content model。
作者還提到他們模型的另一大優點就是,可以輕松地結合到之前的其他模型上,是以,作者将它們的模型和WMF以及CDL結合,稱為DN-WMF和DN-CDL。對比如下:
可以看到,在cold start中,DN-WMF取得了最佳效果,而且DN-WMF和DN-CDL都超過了之前的模型。這個不意外。
在warm start中,DN-WMF和DN-CDL稍稍遜色于以往的模型,這時hybrid model取得了最佳效果,但是确實差距很小。但是考慮到DN-WMF和DN-CDL的模型比hybrid模型簡單地多,是以基本扯平。
值得注意的是這個DeepMusic,這是一個純content-based model,意思是不使用preference資訊。可以看到,在warm start這種有着豐富preference資訊的環境下,它的效果遠不如利用preference的其他模型。而在cold start這種沒有preference資訊的情況下,效果就超過了hybrid model。這個時候WMF這種純靠preference根本不能算了。這也就解釋了,為什麼前面的目标函數要以preference-based的latent model為标杆了。
在另外一個資料集上的結果這裡直接放出,就不贅述了: