有使用者一直好奇爬蟲識别網站上的爬蟲資料是如何整理的,今天就更大家來揭秘爬蟲資料是如何收集整理的。
通過查詢 IP 位址來獲得 rDNS 方式
我們可以通過爬蟲的 IP 位址來反向查詢 rDNS,例如:我們通過反向 DNS 查找工具查找此 IP: 116.179.32.160 ,rDNS 為:baiduspider-116-179-32-160.crawl.baidu.com
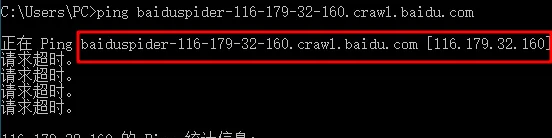
從上面大緻可以判斷應該是百度搜尋引擎蜘蛛。由于 Hostname 可以僞造,是以我們隻有反向查找,仍然不準确。我們還需要正向查找,我們通過 ping 指令查找 baiduspider-116-179-32-160.crawl.baidu.com 能否被解析為:116.179.32.160,通過下圖可以看出 baiduspider-116-179-32-160.crawl.baidu.com 被解析為 116.179.32.160 的 IP 位址,說明是百度搜尋引擎爬蟲确信無疑。
通過 ASN 相關資訊查找
并不是所有爬蟲都遵守上面的規定,大部分爬蟲反向查找沒有任何結果,我們需要查詢 IP 位址的 ASN 資訊來判斷爬蟲資訊是不是正确。
例如:這個 IP 是 74.119.118.20,我們通過查詢 IP 資訊可以看到這個 IP 位址是美國加利福尼亞桑尼維爾的 IP 位址。

通過 ASN 資訊我們可以看出來他是 Criteo Corp. 公司的 IP。
上面的截圖是通過日志記錄檢視到 critieo crawler 的記錄資訊,黃色部分是它的 User-agent ,後面是它的 IP,這條記錄也沒有什麼問題(這個 IP 的确是 CriteoBot 的 IP 位址)。
通過爬蟲的官方文檔公布的 IP 位址段
有一些爬蟲會公布 IP 位址段,我們會将官方公布的爬蟲 IP 位址段直接儲存到資料庫,這是一種既簡單又快捷的方法。
通過公開日志
我們經常可以在網際網路上檢視到公開日志,例如下圖就是我找到的公開日志記錄: