作者:Noah Golmant
機器之心編譯
參與:Geek AI、劉曉坤
來自 UC Berkeley RISELab 的大學研究員 Noah Golmant 發表部落格,從理論的角度分析了損失函數的結構,并據此解釋随機梯度下降(SGD)中的噪聲如何幫助避免局部極小值和鞍點,為設計和改良深度學習架構提供了很有用的參考視角。
當我們着手訓練一個很酷的機器學習模型時,最常用的方法是随機梯度下降法(SGD)。随機梯度下降在高度非凸的損失表面上遠遠超越了樸素梯度下降法。這種簡單的爬山法技術已經主導了現代的非凸優化。然而,假的局部最小值和鞍點的存在使得分析工作更加複雜。了解當去除經典的凸性假設時,我們關于随機梯度下降(SGD)動态的直覺會怎樣變化是十分關鍵的。向非凸環境的轉變催生了對于像動态系統理論、随機微分方程等架構的使用,這為在優化解空間中考慮長期動态和短期随機性提供了模型。
在這裡,我将讨論在梯度下降的世界中首先出現的一個麻煩:噪聲。随機梯度下降和樸素梯度下降之間唯一的差別是:前者使用了梯度的噪聲近似。這個噪聲結構最終成為了在背後驅動針對非凸問題的随機梯度下降算法進行「探索」的動力。
mini-batch 噪聲的協方差結構
介紹一下我們的問題設定背景。假設我想要最小化一個包含 N 個樣本的有限資料集上的損失函數 f:R^n→R。對于參數 x∈R^n,我們稱第 i 個樣本上的損失為 f_i(x)。現在,N 很可能是個很大的數,是以,我們将通過一個小批量估計(mini-batch estimate)g_B:
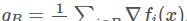
來估計資料集的梯度 g_N:

。其中,B⊆{1,2,…,N} 是一個大小為 m 的 mini-batch。盡管 g_N 本身就是一個關于梯度 ∇f(x) 的帶噪聲估計,結果表明,mini-batch 抽樣可以生成帶有有趣的協方差結構的估計。
引理 1 (Chaudhari & Soatto 定理:https://arxiv.org/abs/1710.11029):在回置抽樣(有放回的抽樣)中,大小為 m 的 mini-batch 的方差等于 Var(g_B)=1/mD(x),其中
該結果意味着什麼呢?在許多優化問題中,我們根本的目标是最大化一些參數配置的似然。是以,我們的損失是一個負對數似然。對于分類問題來說,這就是一個交叉熵。在這個例子中,第一項
是對于(負)對數似然的梯度的協方差的估計。這就是觀測到的 Fisher 資訊。當 N 趨近于正無窮時,它就趨向于一個 Fisher 資訊矩陣,即相對熵(KL 散度)的 Hessian 矩陣。但是 KL 散度是一個與我們想要最小化的交叉熵損失(負對數似然)相差甚遠的常數因子。
是以,mini-batch 噪聲的協方差與我們損失的 Hessian 矩陣漸進相關。事實上,當 x 接近一個局部最小值時,協方差就趨向于 Hessian 的縮放版本。
繞道 Fisher 資訊
在我們繼續詳細的随機梯度下降分析之前,讓我們花點時間考慮 Fisher 資訊矩陣 I(x) 和 Hessian 矩陣 ∇^2f(x) 之間的關系。I(x) 是對數似然梯度的方差。方差與損失表面的曲率有什麼關系呢?假設我們處在一個嚴格函數 f 的局部最小值,換句話說,I(x∗)=∇^2f(x∗) 是正定的。I(x) 引入了一個 x∗附近的被稱為「Fisher-Rao metric」的度量名額: d(x,y)=√[(x−y)^TI(x∗)(x−y) ]。有趣的是,參數的 Fisher-Rao 範數提供了泛化誤差的上界(https://arxiv.org/abs/1711.01530)。這意味着我們可以對平坦極小值的泛化能力更有信心。
回到這個故事中來
接下來我們介紹一些關于随機梯度下降動态的有趣猜想。讓我們做一個類似中心極限定理的假設,并且假設我們可以将估計出的 g_B 分解成「真實」的資料集梯度和噪聲項:g_B=g_N+(1√B)n(x),其中 n(x)∼N(0,D(x))。此外,為了簡單起見,假設我們已經接近了極小值,是以 D(x)≈∇^2f(x)。n(x) 在指數參數中有一個二次形式的密度ρ(z):
這表明,Hessian 矩陣的特征值在決定被随機梯度下降認為是「穩定」的最小值時起重要的作用。當損失處在一個非常「尖銳」(二階導很大)的最小值,并且此處有許多絕對值大的、正的特征值時,我很可能會加入一些把損失從樸素梯度下降的吸引域中「推出來」的噪聲。類似地,對于平坦極小值,損失更有可能「穩定下來」。我們可以用下面的技巧做到這一點:
引理 2:令 v∈R^n 為一個均值為 0 并且協方差為 D 的随機向量。那麼,E[||v||^2]=Tr(D)。
通過使用這一條引理以及馬爾可夫不等式,我們可以看到,當 Hessian 具有大曲率時,更大擾動的可能性越高。我們還可以考慮一個在局部最小值 x∗ 周圍的「穩定半徑」:對于給定的 ϵ∈(0,1),存在一些 r(x∗)>0,使得如果我們的起點 x_0 滿足 ||x_0−x∗||<r(x∗),第 t 次疊代滿足 ||x_t−x∗||<r(對于所有的 t≥0)的機率至少為 1−ϵ。在這種情況下,我們可以說 x∗ 是在半徑 r(x∗) 内随機穩定的。将這種穩定性的概念與我們之前的非正式論證結合起來,我們得到以下結論:
定理 1: 一個嚴格的局部最小值 x∗ 的穩定性半徑 r(x∗) 與 ∇^2f(x∗) 的譜半徑成反比。
讓我們把這個結論和我們所知道的 Fisher 資訊結合起來。如果在随機梯度下降的動态下,平坦極小值更加穩定,這就意味着随機梯度下降隐式地提供了一種正則化的形式。它通過注入各項異性的噪聲使我們擺脫了 Fisher-Rao 範數所帶來的不利泛化條件。
深度學習的啟示:Hessian 矩陣的退化和「wide valleys」
在深度學習中,一個有趣的現象是過度參數化。我們經常有比做示例運算時更多的參數(d>>N)。這時,D(x) 是高度退化的,即它有許多零(或者接近零)的特征值。這意味着損失函數在很多方向上都是局部不變的。這為這些網絡描繪了一個有趣的優化解空間中的場景:随機梯度下降大部分時間都在穿越很寬的「峽谷」(wide valleys)。噪聲沿着幾個有大曲率的方向傳播,這抵消了 g_N 朝着這個「峽谷」的底部(損失表面的最小值)推進的趨勢。
目前關注點:批量大小、學習率、泛化性能下降
由于我們在将 n(x) 加到梯度之前,按照 1/√m 的因子将其進行縮放,是以增加了批處理的規模,降低了小批量估計的整體方差。這是一個值得解決的問題,因為大的批量尺寸可以使模型訓練得更快。它在兩個重要的方面使得訓練更快:訓練誤差在更少的梯度更新中易于收斂,并且大的批量尺寸使得我們能利用大規模資料并行的優勢。但是,不使用任何技巧就增大批量尺寸會導緻測試誤差增大。這個現象被稱為泛化能力下降(generalization gap),并且目前還存在一些為什麼會出現這種情況的假說。一個流行的解釋是,我們的「探索性噪聲」不再有足夠的力量将我們推出一個尖銳最小值的吸引域。一種解決辦法是簡單地提高學習率,以增加這種噪聲的貢獻。這種縮放規則非常成功(https://arxiv.org/abs/1706.02677)。
長期關注點:逃離鞍點
雖然泛化能力下降「generalization gap」最近已經成為了一個熱門話題,但之前仍有很多工作研究鞍點的影響。雖然不會漸進收斂到鞍點(http://noahgolmant.com/avoiding-saddle-points.html),我們仍然可能附近停留相當長的一段時間(https://arxiv.org/abs/1705.10412)。而且盡管大的批量尺寸似乎會更易于産生更尖銳的最小值,但真正大的批量尺寸會将我們引導到确定的軌迹上,這個軌迹被固定在鞍點附近。一項研究(https://arxiv.org/abs/1503.02101)表明,注入足夠大的各項同性噪聲可以幫助我們逃離鞍點。我敢打賭,如果噪聲有足夠的「放大」能力,小批量的随機梯度下降(mini-batch SGD)會在造成訓練困難的次元上提供足夠的噪聲,并且幫助我們逃離它們。
一旦我們解決了「尖銳的最小值」的問題,鞍點可能是下一個大規模優化的主要障礙。例如,我在 CIFAR-10 資料集上用普通的随機梯度下降算法訓練了 ResNet34。當我将批量尺寸增大到 4096 時,泛化能力下降的現象出現了。在這一點之後(我最高測試了大小為 32K 的批量尺寸,有 50K 個訓練樣本),性能顯著降低:訓練誤差和測試誤差都僅僅在少數幾個 epoch 中比較平穩,并且網絡無法收斂到一個有效解上。以下是這些結果的初步學習曲線(即看起來比較醜、還有待改進):
進一步的工作
目前提出的大多數處理尖銳的最小值/鞍點的解決方案都是圍繞(a)注入各向同性噪聲,或(b)保持特定的「學習率和批量尺寸」。我認為從長遠來看,這還不夠。各向同性噪聲在包含「wide valley」結構的解空間中做的并不好。增加學習率也增大了對梯度的更新,這使得權重更新得更大。我認為正确的方法應該是想出一種有效的方法來模拟小批量噪聲的各向異性,這種方法從學習率和批處理大小的組合中「解耦」出來。存在能夠使用子采樣梯度資訊和 Hessian 向量乘積去做到這一點的方法,我正在進行這個實驗。我很希望聽聽其它的關于如何解決這個問題的想法。與此同時,我們還需要做大量的理論工作來更詳細地了解這種動态,特别是在一個深度學習環境中。