作者:David A. Teich等
機器之心編譯
關于深度學習性能,還有很多不明之處。例如,你怎麼進行測量?你應該測量什麼?在不久之前的 GTC 2018,英偉達 CEO 黃仁勳介紹了 PLASTER 架構,從可程式設計性到學習率 7 大挑戰來評測深度學習性能。今日,英偉達部落格對 PLASTER 架構進行了詳細介紹,機器之心編譯了相關白皮書的主要内容。
白皮書連結:https://www.tiriasresearch.com/wp-content/uploads/2018/05/TIRIAS-Research-NVIDIA-PLASTER-Deep-Learning-Framework.pdf
PLASTER 代表的含義:
- 可程式設計性(Programmability)
- 延遲(Latency)
- 準确率(Accuracy)
- 模型大小(Size of Model)
- 吞吐量(Throughput)
- 能效(Energy Efficiency)
- 學習率(Rate of Learning)
可程式設計性
機器學習不僅在模型的規模和複雜性方面經曆了爆炸性的增長,而且在神經網絡體系結構的多樣性方面也經曆了類似的增長。即使是專家也很難了解模型的選擇,然後選擇合适的模型來解決他們的人工智能問題。
在對深度學習模型進行編碼和訓練之後,針對特定的運作時推斷環境對其進行優化。英偉達使用兩個關鍵工具解決訓練和推理難題。在編碼方面,基于人工智能的服務開發人員使用 CUDA,這是一個并行計算平台和 GPU 通用計算的程式設計模型。在推斷方面,基于人工智能的服務開發人員使用了英偉達的可程式設計推斷加速器 TensorRT。
CUDA 通過簡化在英偉達平台上實作算法所需的步驟來幫助資料科學家。TensorRT 可程式設計推斷加速器采用經過訓練的神經網絡,并對其進行優化以用于運作時部署。它測試浮點數和整數精度的不同級别,以便開發人員和運算過程能夠平衡系統所需的準确率和性能,進而提供優化的解決方案。
開發人員可以直接在 TensorFlow 架構中使用 TensorRT 來優化基于人工智能的服務傳遞模型。TensorRT 可以從包括 Caffe2、MXNet 和 PyTorch 在内的各種架構中導入開放神經網絡交換 ( ONNX ) 模型。雖然深度學習仍然是在技術層面編碼,但這将幫助資料科學家更好地利用寶貴的時間。
延遲
人和機器做決策或采取行動時都需要反應時間。延遲就是請求與做出回應之間所需要的時間。大部分人性化軟體系統(不隻是 AI 系統),延遲都是以毫秒來計量的。
由于 Siri、Alexa 等語音接口的出現,語音識别成為了很常見的一種應用。在消費者與客服領域,虛拟助手是很大的一種需求。但是,當人們接入虛拟助手時,即使數秒的延遲都會讓人感覺不自然。
圖像和視訊管理是另一種需要低延遲、實時推理服務的應用。谷歌曾表示,7 毫秒是圖像和視訊管理應用的最優化延遲。
另一個例子是自動翻譯。早期基于程式、專家系統的設計,不能了解高速語言的細微差别,難以提供實時會話。現在,深度學習進一步改進了機器翻譯。
準确率
雖然準确率對每個行業來說都不可或缺,但對醫療保健行業來說尤其重要。在過去的幾十年中,醫學成像技術有了很大進步,增加了其在醫療中的使用量,并且需要更多的圖像分析來确定醫學問題。醫學成像的進步和使用還意味着必須把大量資料從醫療器械傳給醫學專家進行分析。解決資料量問題有兩個選擇:一是以較長延遲為代價傳輸完整資訊,二是對資料進行采樣并使用技術對其進行重建,但這些技術可能導緻錯誤的重建和診斷。
深度學習的一個優點是可以以高精度進行訓練,并且以較低精度實作。深度學習訓練可以在更進階别的數學精度上非常精确地進行,通常選擇 FP32。然後在運作時可以用較低精度的數學來實作,通常選擇 FP16,進而獲得改良的吞吐量、效率甚至延遲。保持高準确率對于最佳使用者體驗至關重要。TensorRT 利用 Tesla V100 Tensor Core 的 FP16 處理以及 Tesla P4 的 INT8 特性來加速推斷,與 FP32 相比,其推理速度提高了 2 - 3 倍,同時準确率損失接近零。
基于人工智能的服務開發人員可以優化其深度學習模型以提高效率,然後在工作中以較低代價實作這些模型。
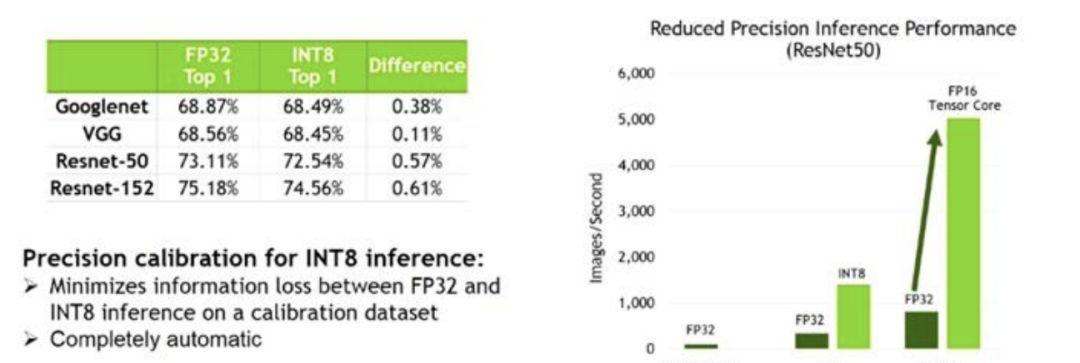
圖 2:TensorRT 降低了精度的推斷性能
模型大小
深度學習模型的大小和處理器間的實體網絡容量都對性能有所影響,特别是在延遲和吞吐量方面。深度學習網絡模型數量激增,模型大小和複雜性随之增加,也是以能夠做更複雜的分析,滿足了更強大系統的訓練需求。在深度學習模型中,計算力和實體網絡擴充的原因是:
- 網絡層數量
- 每層節點(神經元)數量;
- 每層計算複雜度
- 一個網絡層節點間連接配接的數量以及相鄰層間節點的數量
深度學習市場還處于早期階段。在對比模型大小時,目前的思路都歸結于實體關聯:深度學習模型大小與計算和推理所需的實體網絡資源成正比。例如,當開發者優化一個已訓練深度學習模型來保證推斷準确率和延遲時,可能會降低計算精度、簡化每個模型網絡層或者簡化模型網絡層間的連接配接。然而,使用更大的已訓練模型往往會帶來更大的優化模型來做推斷。

圖 3:深度學習模型大小
吞吐量
吞吐量用來表述:在給定建立或部署的深度學習網絡規模的情況下,可以傳遞多少推斷結果。開發人員越來越多地在指定的延遲門檻值内優化推斷。雖然延遲限制可確定良好的客戶體驗,但在此限制内最大化吞吐量對于最大限度地增加資料中心效率和收益至關重要。
人們傾向于把吞吐量作為唯一的性能名額,因為每秒計算的次數越多,其他領域的性能就越好。但是,如果系統無法在指定的延遲要求、電源預算或伺服器節點數内提供足夠的吞吐量,那它最終将無法很好地滿足應用程式的推斷需求。如果吞吐量和延遲之間缺乏适當的平衡,結果會是較差的客戶體驗、服務等級協定(SLAs)缺失,以及服務可能出現故障。
娛樂業長期以來一直把吞吐量作為關鍵性能名額,尤其是在動态廣告投放中。例如,品牌贊助商将廣告動态地置于諸如電視節目或體育賽事的視訊流中。廣告商想知道其廣告出現的頻率,以及它們是否傳達給了預期閱聽人。了解這些投放的準确性和焦點對于廣告商來說至關重要。
圖 4:直播時的圖像識别
能效
随着深度學習加速器性能的提高,深度學習加速器的能耗也飛速增加。為深度學習解決方案提供 ROI 涉及了更多的層面,而不能僅僅看到系統的推斷性能。能耗增長會快速增加提供服務的成本,這推動了在裝置和系統中對提高能效的需求。
例如,語音進行中通常需要海量處理來提供自然語音的智能應答。提供實時語音處理的資料中心推斷通常涉及大量計算機資源的支撐,并給企業總成本帶來很大的影響。是以,行業中使用每瓦特推斷數(inferences-per-watt)來度量營運狀況。超大規模資料中心追求能效的最大化,以在固定電源預算的情況下提供盡可能多的推斷。
解決方案不是僅僅看哪些單獨的處理器擁有更低的能耗。例如,如果某個處理器的功率是 200W,另一個處理器的功率是 130W,這并不表示 130W 的處理器系統更好。如果 200W 的系統能以 20 倍的速度更快地完成任務,那麼它的能效更大。
每瓦特推斷數還取決于訓練過程和推斷過程中的延遲因素。能效不僅取決于過程中的純能耗,還取決于吞吐量。能效是另一個展示 PLASTER 元素互相關聯的例子,并且必須在完整的推斷性能圖景中被考慮到。
學習率
近年來,企業開始實施開發營運,使用更強大的系統和更進階的程式設計工具,讓開發和業務變得更加緊密。雖然深度學習仍處于起步階段,但很多等待利用深度學習的學術、政府和商業機構卻并非如此。他們想要的不是利用空洞而靜态的資料訓練出來的推斷引擎。「AI」中包含了智能(intelligence)一詞,使用者希望神經網絡能在合理的期限内進行學習和适應。為了讓複雜的深度學習系統推動商業發展,軟體工具開發者必須支援開發營運。
随着組織機構繼續對深度學習和神經網絡進行實驗研究,他們将學習如何更有效地建構和實作深度學習系統。由于推斷服務持續接收新資料并且服務本身也在增長和變化,深度學習模型必須周期性地重新訓練。為此,當新資料到達時,IT 機構和軟體開發者必須更快地重新訓練模型。多 GPU 伺服器配置已經使深度學習訓練時間從數周、數天降低到了數小時、數分鐘。更快的訓練時間意味着開發者可以更頻繁地重新訓練他們的模型以提高準确率或保持高準确率。目前一些深度學習實作已經可以每天重新訓練多次。
可程式設計性也是學習率的一個影響因素。為了減少開發者工作流,谷歌和英偉達近日釋出了 TensorFlow 和 TensorRT 的內建。開發者可以在 TensorFlow 架構内調用 TensorRT 來優化已訓練的網絡,進而在英偉達的 GPU 上高效運作。深度學習能夠更好地整合訓練過程和推斷過程,因而更易成為開發營運的解決方案,幫助機構在疊代他們的深度學習模型時快速地實作變化。