關于Scrapy工作流程回顧
Scrapy單機架構
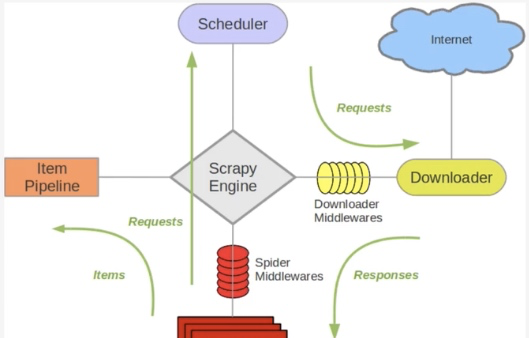
上圖的架構其實就是一種單機架構,隻在本機維護一個爬取隊列,Scheduler進行排程,而要實作多态伺服器共同爬取資料關鍵就是共享爬取隊列。

分布式架構
我将上圖進行再次更改
這裡重要的就是我的隊列通過什麼維護?
這裡一般我們通過Redis為維護,Redis,非關系型資料庫,Key-Value形式存儲,結構靈活。
并且redis是記憶體中的資料結構存儲系統,處理速度快,提供隊列集合等多種存儲結構,友善隊列維護
如何去重?
這裡借助redis的集合,redis提供集合資料結構,在redis集合中存儲每個request的指紋
在向request隊列中加入Request前先驗證這個Request的指紋是否已經加入集合中。如果已經存在則不添加到request隊列中,如果不存在,則将request加入到隊列并将指紋加入集合
如何防止中斷?如果某個slave因為特殊原因當機,如何解決?
這裡是做了啟動判斷,在每台slave的Scrapy啟動的時候都會判斷目前redis request隊列是否為空
如果不為空,則從隊列中擷取下一個request執行爬取。如果為空則重新開始爬取,第一台叢集執行爬取向隊列中添加request
如何實作上述這種架構?
這裡有一個scrapy-redis的庫,為我們提供了上述的這些功能
scrapy-redis改寫了Scrapy的排程器,隊列等元件,利用他可以友善的實作Scrapy分布式架構
關于scrapy-redis的位址:https://github.com/rmax/scrapy-redis
搭建分布式爬蟲
前提是要安裝scrapy_redis子產品:pip install scrapy_redis
這裡的爬蟲代碼是用的之前寫過的爬取知乎使用者資訊的爬蟲
修改該settings中的配置資訊:
替換scrapy排程器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
添加去重的class
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
添加pipeline
如果添加這行配置,每次爬取的資料也都會入到redis資料庫中,是以一般這裡不做這個配置
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
共享的爬取隊列,這裡用需要redis的連接配接資訊
這裡的user:pass表示使用者名和密碼,如果沒有則為空就可以
REDIS_URL = 'redis://user:[email protected]:9001'
設定為為True則不會清空redis裡的dupefilter和requests隊列
這樣設定後指紋和請求隊列則會一直儲存在redis資料庫中,預設為False,一般不進行設定
SCHEDULER_PERSIST = True
設定重新開機爬蟲時是否清空爬取隊列
這樣每次重新開機爬蟲都會清空指紋和請求隊列,一般設定為False
SCHEDULER_FLUSH_ON_START=True
分布式
将上述更改後的代碼拷貝的各個伺服器,當然關于資料庫這裡可以在每個伺服器上都安裝資料,也可以共用一個資料,我這裡方面是連接配接的同一個mongodb資料庫,當然各個伺服器上也不能忘記:
所有的伺服器都要安裝scrapy,scrapy_redis,pymongo
這樣運作各個爬蟲程式啟動後,在redis資料庫就可以看到如下内容,dupefilter是指紋隊列,requests是請求隊列