XML解析方式有三種:DOM、SAX、StAX
xml文檔每個成分都是一個節點,每個xml标簽對應一個元素節點:整個文檔是一個文檔節點,每個xml标簽對應一個元素節點,包含早xml标簽中是文本節點,注釋是注釋節點。
DOM解析:
DOM Document Object Model ----- 文檔對象模型 基于樹形結構的xml解析方式。 會将整個XML載入記憶體,以樹形結構方式存儲,易于程式設計 當xml文檔是聚焦大,會造成較大的資源消耗。 即将整個xml 加載記憶體中,形成文檔對象,所有對xml操作都對記憶體中文檔對象進行
SAX解析:
基于事件模型的sax解析方式 當xml 文檔非常大,不可能将xml所有資料加載到記憶體 即一邊解析 ,一邊處理,一邊釋放記憶體資源 ---- 不允許在記憶體中保留大規模xml 資料 使用推模式如下圖所示
即由伺服器為主導,向用戶端主動發送資料( 推送 ) 推模式(事件由解析器産生并通過回調函數發送給應用程式)
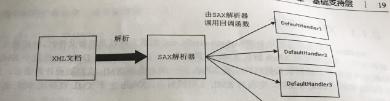
缺點:不存儲xml文檔結構,開發人員自己維護業務邏輯涉及的多層節點之間關系。
流式處理是以隻能向後單向進行,無法像dom那樣自由導航到之前處理過得節點上重新處理,也不支援xPath
stax
STAX 是一種 拉模式 XML 解析方式(SAX性能不如STAX,STAX技術較新)
采取如下圖所示的模式
即拉模式由用戶端為主導,主動向伺服器申請資料( 輪詢 )(應用程式通過調用解析器推進解析程序)

簡化了處理xml文檔代碼,可同時處理多個xml文檔,可決定何時停止解析。
版權聲明:本文為CSDN部落客「weixin_33881050」的原創文章,遵循CC 4.0 BY-SA版權協定,轉載請附上原文出處連結及本聲明。
原文連結:https://blog.csdn.net/weixin_33881050/article/details/92411602