本期介紹一種常用的相關系數:皮爾遜相關系數(Person)。
相關系數可用來衡量兩個變量之間的相關性的大小,根據資料滿足的不同條件,我們要選擇不同的相關系數進行計算和分析。
一、相關的基本數學概念
總體和樣本
- 總體:所要考察對象的全部個體
- 樣本:從總體中所抽取的一部分個體叫做總體的一個樣本。
- 我們可以通過計算樣本的統計量來估計總體的統計量
- 例如:使用樣本均值、樣本标準差來估計總體的的均值(平均水準)和總體的标準差(偏離程度)
二、皮爾遜相關系數(Person)
1. 協方差(用于引出相關系數的定義)
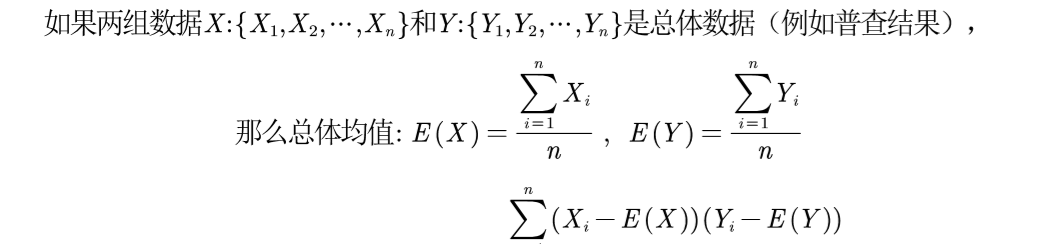
E(X)為第一個X組資料的均值;E(X)為y組資料的均值。總體的協方差是第i個X和Y減去均值的乘積加和除以樣本總數。協方差的大小表示的是兩個變量的總體的誤差,用于度量各個次元偏離其均值的程度。
協方差為0時,兩者獨立。協方差的絕對值越大,兩者對彼此的影響越大,反之,越小。
由協方差可以引出相關系數的定義。
- 我們觀察協方差的公式,可以發現,X,Y(即,兩個變量)的量綱會影響協方差的大小,是以并不适合比較大小,由此引出了相關系數。
2. 總體皮爾遜Person相關系數

-
觀察總體Person相關系數的公式:
我們發現皮爾遜相關系數可以看成消除了兩個變量量綱影響,即将X和Y标準化後的協方差。
是以,我們可以使用皮爾遜相關系數來衡量兩個變量線性相關的程度。
3. 樣本皮爾遜Person相關系數
4.皮爾遜相關系數的使用範圍
- 兩個變量之間是線性關系,且是連續資料。
- 兩個變量的總體是正态分布,或接近正态的單峰分布。
- 兩個變量的觀測值是成對的,且每對觀測值之間互相獨立。
通常情況下通過以下取值範圍判斷變量的相關強度:相關系數 (均取絕對值後):0.8-1.0 極強相關0.6-0.8 強相關0.4-0.6 中等程度相關0.2-0.4 弱相關0.0-0.2 極弱相關或無相關
三、畫皮爾遜相關系數圖
因為畫圖屬于比較簡單的操作,是以不打算專門寫文章來叙述如何畫折線圖之類的。如果要畫什麼圖就去找相應的實作代碼,用自己的資料并對圖的參數進行修改就可以啦。這裡我們來講皮爾遜相關系數圖的實作案例
代碼:
# -*- coding: UTF-8 -*-#畫heatmapimport seaborn as snsimport pandas as pdimport matplotlib.pyplot as plt#pandas讀取csv資料的方法(之前有講),header=None表示無表頭dataset = pd.read_csv("a.csv",header=None)#這裡的資料是DataFrame形式,seaborn讀的就是這種類型的資料 print(dataset)#求相關性系數cov=dataset.corr()#定義畫布大小plt.subplots(figsize=(10, 10))#調用seaborn庫中額heatmap算法sns.heatmap(cov)#顯示出圖檔plt.show()
但是我們發現預設參數畫出來的圖不太好看,我們可以自己設定想要的參數,詳情見sns.heatmap()函數
seaborn.heatmap(data, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)
我們依次來介紹下這些參數:
- data(資料參數):矩陣資料集,可以是numpy的數組(array),也可以是pandas的DataFrame。如果是DataFrame,則df的index/column資訊會分别對應到heatmap的columns和rows,即df.index是熱力圖的行标,df.columns是熱力圖的列标。
- vamx,vmin(矩陣塊顔色參數):分别是熱力圖的顔色取值最大和最小範圍,預設是根據data資料表裡的取值确定
- .cmap:從數字到色彩空間的映射,取值是matplotlib包裡的colormap名稱或顔色對象,或者表示顔色的清單;改參數預設值:根據center參數設定.
- center:資料表取值有差異時,設定熱力圖的色彩中心對齊值;通過設定center值,可以調整生成的圖像顔色的整體深淺;設定center資料時,如果有資料溢出,則手動設定的vmax、vmin會自動改變.
- robust:預設取值False;如果是False,且沒設定vmin和vmax的值,熱力圖的顔色映射範圍根據具有魯棒性的分位數設定,而不是用極值設定.
- annot(annotate的縮寫):預設取值False;如果是True,在熱力圖每個方格寫入資料;如果是矩陣,在熱力圖每個方格寫入該矩陣對應位置資料
- fmt:字元串格式代碼,矩陣上辨別數字的資料格式,比如保留小數點後幾位數字
- annot_kws:預設取值False;如果是True,設定熱力圖矩陣上數字的大小顔色字型,matplotlib包text類下的字型設定:
- linewidths:定義熱力圖裡“表示兩兩特征關系的矩陣小塊”之間的間隔大小
- linecolor:切分熱力圖上每個矩陣小塊的線的顔色,預設值是’white’
- cbar:是否在熱力圖側邊繪制顔色刻度條,預設值是True
- cbar_kws:熱力圖側邊繪制顔色刻度條時,相關字型設定,預設值是None
- cbar_ax:熱力圖側邊繪制顔色刻度條時,刻度條位置設定,預設值是None
- xticklabels, yticklabels:xticklabels控制每列标簽名的輸出;yticklabels控制每行标簽名的輸出。預設值是auto。如果是True,則以DataFrame的列名作為标簽名。如果是False,則不添加行标簽名。如果是清單,則标簽名改為清單中給的内容。如果是整數K,則在圖上每隔K個标簽進行一次标注。如果是auto,則自動選擇标簽的标注間距,将标簽名不重疊的部分(或全部)輸出
- mask:控制某個矩陣塊是否顯示出來。預設值是None。如果是布爾型的DataFrame,則将DataFrame裡True的位置用白色覆寫掉
- ax:設定作圖的坐标軸,一般畫多個子圖時需要修改不同的子圖的該值
- **kwargs:All other keyword arguments are passed to ax.pcolormesh
簡單改改之後,雖然還是不好看,但至少說明可以改變!
plt.subplots(figsize=(60,30))sns.heatmap(cov,yticklabels=False,xticklabels=1,cmap="Blues",center=True)plt.savefig('./BluesStateRelation.png')plt.show()
完
免責聲明:部分圖檔及資料來源于網絡,目的在于傳遞更多資訊及分享,如涉及侵權,請聯系我及時修改或删除。