B*樹索引是最常用的資料庫索引,一般所說的索引都是B*樹索引
B*樹索引的構造類似于二叉樹,能根據鍵提供一行或一個行集的快速通路,通常隻需要很少的讀操作就能找到正确的行。
B*樹索引的結構有可能如下圖所示
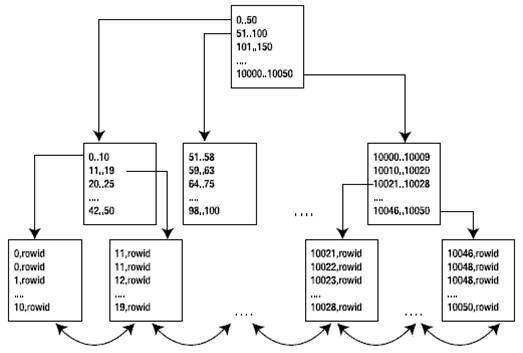
這個樹最底層的塊稱為葉子節點(leaf node)或葉子塊(leaf block),其中分别包含各個索引建以及一個rowid(指向所索引的行)。葉子節點之上的内部塊稱為分支塊(branch block)。這些節點用于在結構中實作導航。
有意思的是,索引的葉子節點實際上又構成了一個雙向連結清單,執行索引區間掃描(值的有序掃描)也很容易,找到第一個值之後,我們不需要再在索引結構中導航,而隻需根據需要,通過葉子節點向前或向後掃描就可以了。是以要滿足諸如以下的謂詞條件将相當簡單:
where x between 20 and 30
Oracle發現第一個最小值大于或等于20的索引葉子塊,然後水準地周遊葉子節點連結清單,直到命中一個大于30的值。
B*樹索引中不存在非唯一(nonunique)條目。在一個非唯一索引中,Oracle會把rowid作為一個額外的列追加到鍵上,使得鍵唯一。在一個唯一索引中,根據你定義的唯一性,Oracle不會再向索引建增加rowid。
所有葉子塊都應該在樹的同一個層上,這一層的層号就稱為索引的高度,這表示所有從索引的根塊到葉子塊的周遊都會通路同樣數目的塊。即索引是高度平衡的,大多數的B*樹索引高度都是2或者3,即使索引中有數百萬行記錄,是以一般來說,在索引中找到一個鍵隻需要執行2或3次I/O。随着基表的增長,通過索引通路資料的性能基本上不會有太大的惡化,因為隻要索引高度不變化,讀索引的I/O是相同的。而通過rowid通路資料行的效率也是相同,性能僅根據傳回的資料量而變化。
![PAT 1089 Insert or Merge[難][圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)